Clear Sky Science · es
Un enfoque de aprendizaje profundo por refuerzo consciente de la movilidad en dos niveles para el descarte tolerante a fallos de tareas en computación vehicular en el borde-nube
Caminos más inteligentes para coches ávidos de datos
Los coches modernos se están convirtiendo en ordenadores rodantes, procesando constantemente las cámaras, los sensores y la información de navegación. Gran parte de ese trabajo debe realizarse en milisegundos para mantener a los conductores seguros y los servicios ágiles. Este artículo explora cómo hacer que ese cómputo en tiempo real sea más fiable y rápido coordinando dónde se realizan las “tareas domésticas” digitales de un vehículo: dentro del coche, en pequeños ordenadores junto a la carretera o en servidores en la nube distantes, incluso cuando el tráfico es intenso, las conexiones son inestables y los dispositivos fallan ocasionalmente.
Por qué los coches necesitan ayuda de la carretera
Los vehículos conectados y autónomos de hoy ejecutan tareas como detección de objetos, mantenimiento de carril y asistencia en realidad aumentada. Hacer todo esto únicamente dentro del coche requeriría hardware potente y un consumo energético significativo. La Computación Vehicular en el Borde-Nube (VECC) aborda esto permitiendo que los coches descarguen tareas exigentes a Unidades en el Lado de la Carretera (RSU): pequeñas estaciones de cálculo a lo largo de la vía que, a su vez, pueden cooperar con servidores en la nube más grandes. Pero esta arquitectura afronta problemas prácticos: los coches se mueven rápidamente entre RSU, los enlaces inalámbricos aparecen y desaparecen, y tanto los equipos del borde como los de la nube pueden sobrecargarse o fallar. En conjunto, estos factores pueden causar demoras largas o la pérdida completa de tareas, lo que es inaceptable para aplicaciones de conducción críticas en tiempo.
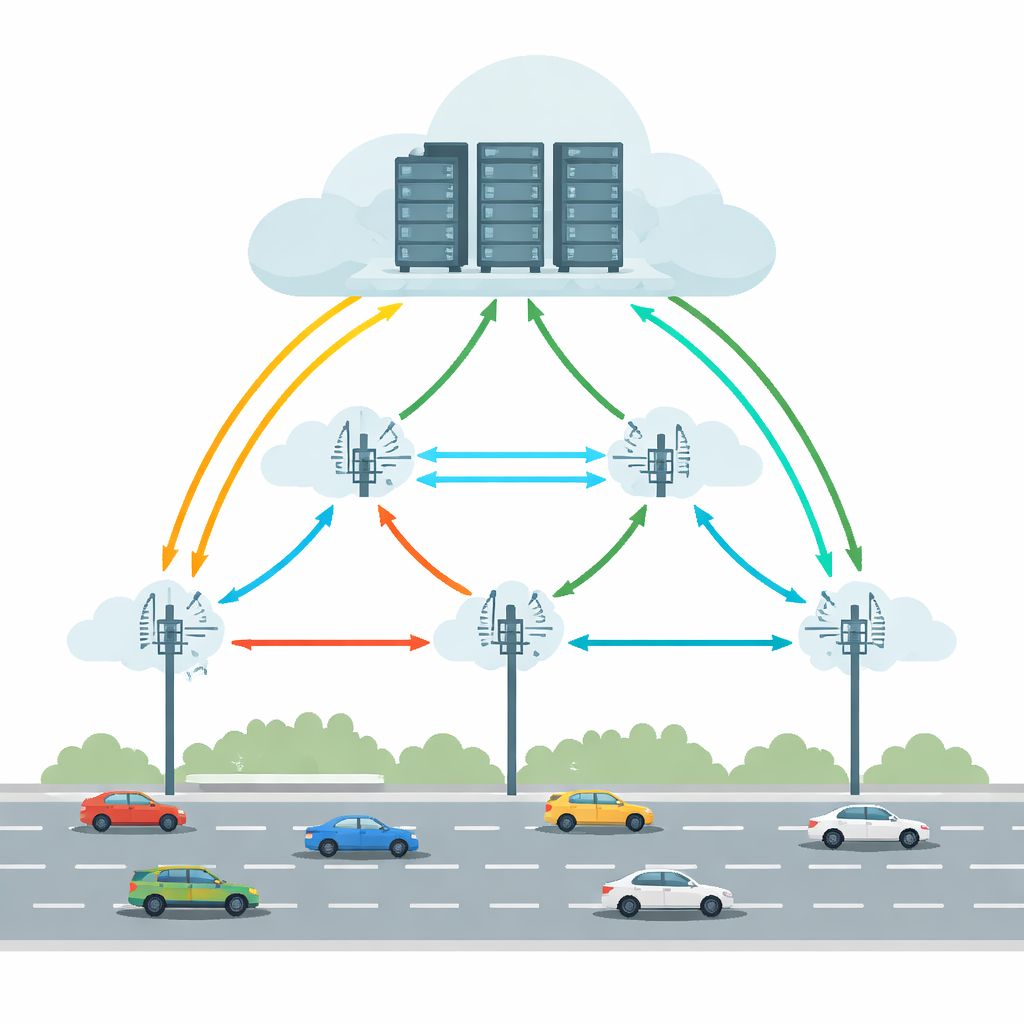
Equilibrar movimiento, latencias y fallos
Muchos sistemas previos intentaron mejorar el descarte de tareas prediciendo la posición del vehículo, minimizando la latencia o ahorrando energía. Sin embargo, normalmente trataban la fiabilidad como una ocurrencia tardía y a menudo asumían condiciones estables. Las carreteras reales son más caóticas: los enlaces inalámbricos pueden caer, los servidores pueden fallar y los patrones de tráfico pueden cambiar de repente. Este artículo sostiene que una solución práctica debe considerar la movilidad del vehículo, las latencias de la red y el riesgo de fallos simultáneamente, a través de múltiples RSU. También debe evitar un “cerebro” central único que se convierta en cuello de botella a medida que la red vial crece. En su lugar, la toma de decisiones debería ser distribuida, con unidades locales que puedan reaccionar rápidamente mientras aprenden del sistema global.
Cerebros de aprendizaje en dos niveles a lo largo de la carretera
Los autores proponen un marco de decisión en dos niveles impulsado por Redes Q Profundas (Deep Q-Networks), un tipo de aprendizaje profundo por refuerzo que aprende por prueba y error. En el primer nivel, un agente de aprendizaje —replicado en cada RSU— elige qué RSU es la más adecuada para gestionar cada tarea entrante. Tiene en cuenta la carga de cada RSU, su capacidad de procesamiento, sus tendencias a fallar y la trayectoria esperada del vehículo, así como el tiempo que llevará devolver los resultados a lo largo de esa ruta. En el segundo nivel, una vez elegida una RSU, un agente local decide exactamente cómo ejecutar la tarea: qué servidor debe ser primario, cuál actuar como respaldo y qué patrón de recuperación ante fallos emplear. Se consideran tres estrategias: reintentar en el mismo servidor, cambiar a un servidor de respaldo tras un fallo, o ejecutar primario y respaldo en paralelo y quedarse con el que termine primero.
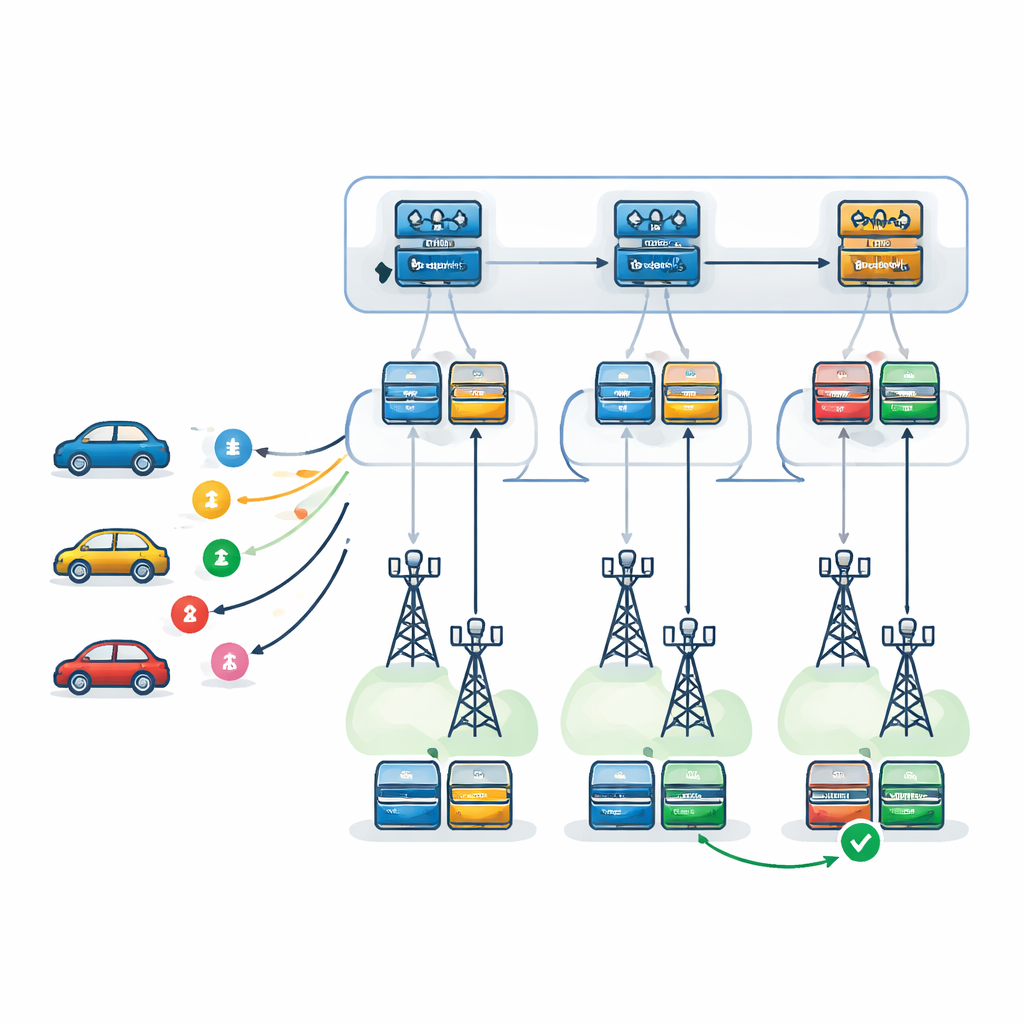
Probando el sistema en una ciudad virtual
Para evaluar el rendimiento de esta configuración de aprendizaje en dos niveles, los investigadores construyeron un simulador detallado que acopla un sistema de tráfico (SUMO) con un motor basado en eventos (SimPy). Esto les permitió modelar vehículos en movimiento, condiciones inalámbricas cambiantes y colas realistas en servidores de borde y nube. Compararon su método con varias alternativas: un sistema similar en dos niveles usando un algoritmo de aprendizaje distinto (Proximal Policy Optimization), una estrategia voraz simple que siempre elige la RSU aparentemente mejor en el momento, una configuración sin reenvío donde las tareas las gestiona únicamente la RSU que las recibe primero, y un único agente de aprendizaje “plano” que intenta tomar todas las decisiones de una vez. A lo largo de muchos episodios y bajo diferentes intensidades de tráfico, midieron recompensas medias, latencia global y la frecuencia con la que las tareas fallaban o no cumplían sus plazos.
Qué muestran los resultados en carreteras congestionadas
Bajo tráfico ligero y plazos relativamente holgados, la mayoría de los métodos rindieron de forma similar porque los recursos estaban infrautilizados. Las diferencias surgieron con tráfico intenso e imbalanceado y restricciones temporales más estrictas —exactamente las situaciones estresantes que más importan. En esos escenarios, la Red Q Profunda en dos niveles redujo las fallas de tareas aproximadamente entre un 29% y un 63% en comparación con los otros enfoques, y mejoró la recompensa global en torno a un 8% a 38%. La estructura jerárquica demostró ser más escalable que el aprendiz plano a medida que aumentaba el número de RSU y servidores, y se mostró robusta incluso cuando la comunicación entre RSU era algo poco fiable o cuando las predicciones sobre la ruta futura de un vehículo eran imperfectas.
Qué significa esto para los conductores cotidianos
En términos sencillos, el estudio muestra que dotar a la red vial de un “cerebro” de aprendizaje por capas puede hacer que los vehículos conectados y autónomos sean más ágiles y confiables. Al elegir primero la unidad de carretera adecuada para cada tarea y luego planificar cómo sobrevivirá esa tarea a demoras y fallos, el sistema mantiene los tiempos de respuesta bajos y aumenta la probabilidad de que las respuestas lleguen antes de que sea demasiado tarde. Aunque el despliegue en el mundo real aún deberá lidiar con condiciones complejas y cuestiones de seguridad, este trabajo traza un camino hacia una infraestructura digital más inteligente y tolerante a fallos capaz de seguir el ritmo de las crecientes demandas computacionales de los coches del futuro.
Cita: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Palabras clave: computación en el borde vehicular, descarte de tareas, aprendizaje profundo por refuerzo, tolerancia a fallos, sistemas de transporte inteligentes