Clear Sky Science · en
A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing
Smarter Roads for Data-Hungry Cars
Modern cars are becoming rolling computers, constantly crunching camera feeds, sensor data, and navigation information. Much of this work must happen in milliseconds to keep drivers safe and services responsive. This paper explores how to make that real-time computing more reliable and faster by coordinating where a vehicle’s digital “chores” are done—inside the car, at small computers by the roadside, or in distant cloud servers—even when traffic is heavy, connections are shaky, and devices occasionally fail.
Why Cars Need Help from the Road
Today’s connected and self-driving vehicles run tasks such as object detection, lane keeping, and augmented-reality guidance. Doing all of this inside the car alone would require powerful hardware and significant energy. Vehicular Edge Cloud Computing (VECC) tackles this by letting cars offload demanding tasks to Roadside Units (RSUs)—small computing stations along the road—that can in turn cooperate with larger cloud servers. But this setup faces practical headaches: cars move quickly between RSUs, wireless links come and go, and both edge and cloud machines can become overloaded or fail. Together, these factors can cause long delays or outright task failures, which are unacceptable for time-critical driving applications.
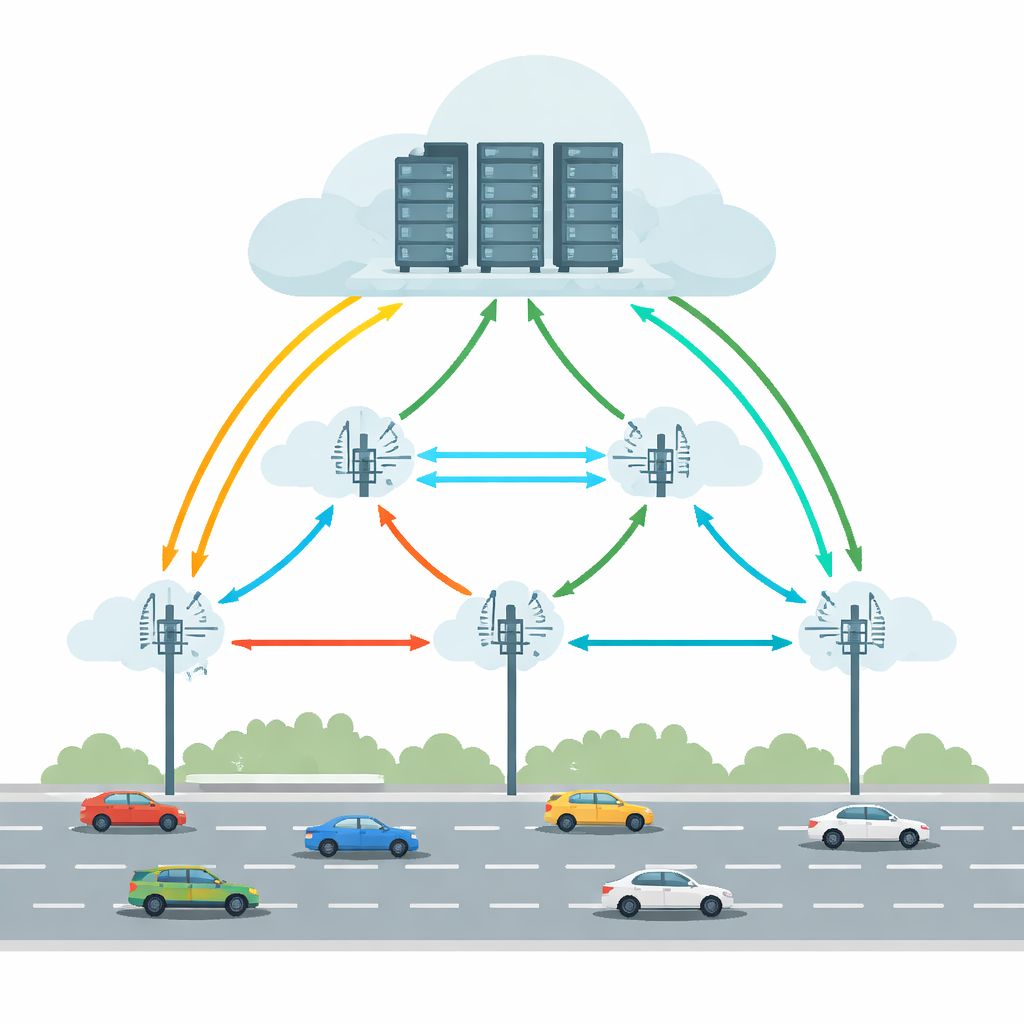
Balancing Movement, Delays, and Failures
Many previous systems tried to improve offloading by predicting where a car will be, minimizing delay, or saving energy. However, they usually treated reliability as an afterthought and often assumed stable conditions. Real roads are messier: wireless links can drop, servers can fail, and traffic patterns can change suddenly. This paper argues that a practical solution must look at vehicle mobility, network delays, and the risk of failures all at once, across multiple RSUs. It also needs to avoid a single central “brain” that becomes a bottleneck as the road network grows. Instead, decision-making should be distributed, with local units that can react quickly while still learning from the wider system.
Two-Level Learning Brains Along the Road
The authors propose a bi-level decision framework powered by Deep Q-Networks, a type of deep reinforcement learning that learns by trial and error. At the first level, a learning agent—replicated at every RSU—chooses which RSU is best suited to handle each incoming task. It takes into account each RSU’s load, processing power, failure tendencies, and expected travel path of the vehicle, as well as the time it will take to ship results back along that path. At the second level, once an RSU is chosen, a local agent decides exactly how to execute the task: which server should be primary, which should serve as backup, and which failure-recovery pattern to use. Three strategies are considered: retrying on the same server, switching to a backup server after a failure, or running primary and backup in parallel and keeping the one that finishes first.
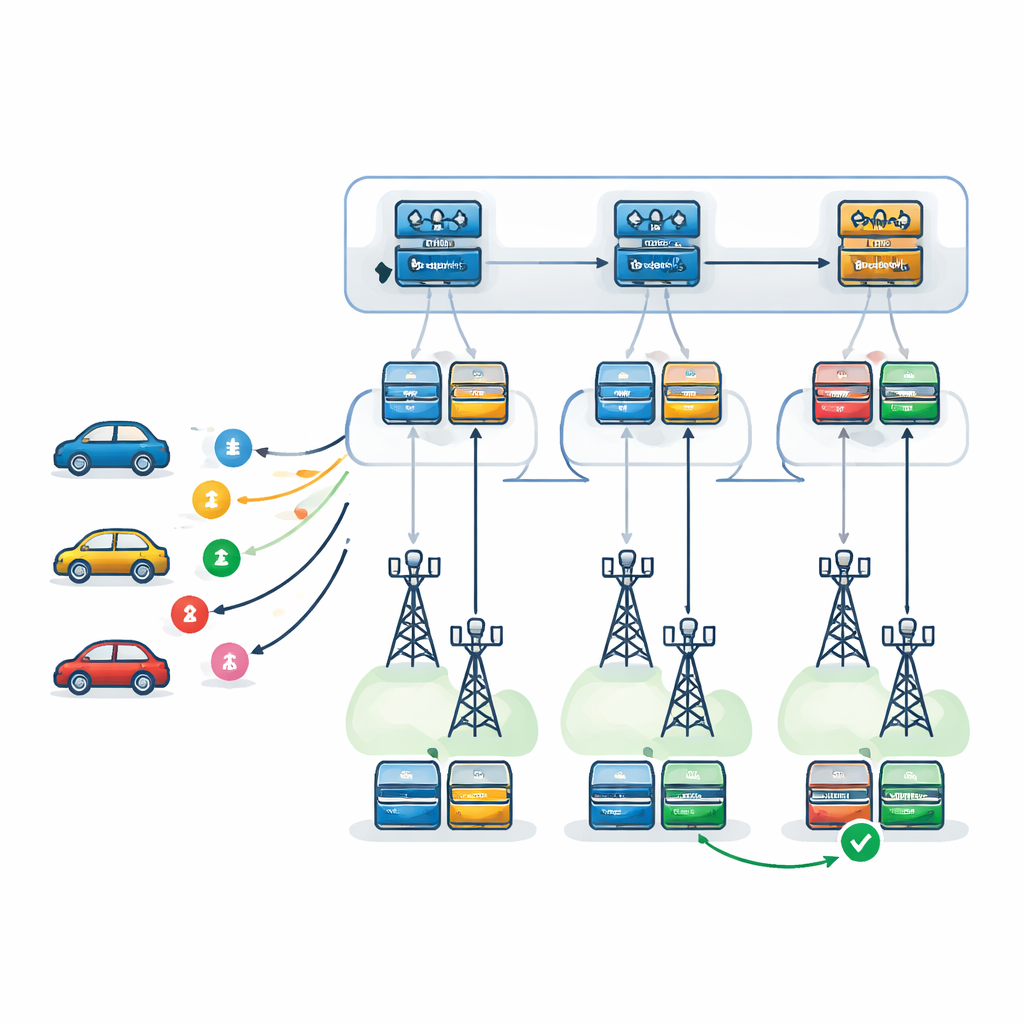
Testing the System in a Virtual City
To see how well this two-level learning setup works, the researchers built a detailed simulator that couples a traffic system (SUMO) with an event-based engine (SimPy). This allowed them to model moving vehicles, changing wireless conditions, and realistic queues at edge and cloud servers. They compared their method to several alternatives: a similar two-level system using a different learning algorithm (Proximal Policy Optimization), a simple greedy strategy that always picks the apparently best RSU at the moment, a no-forwarding setup where tasks are handled only by the RSU that first receives them, and a single “flat” learning agent that tries to make all decisions at once. Across many episodes and under different traffic intensities, they measured average rewards, overall delay, and how often tasks failed or missed their deadlines.
What the Results Show on Busy Roads
Under light traffic and fairly loose deadlines, most methods performed similarly because resources were underutilized. The differences appeared under heavy, imbalanced traffic and tighter timing constraints—exactly the stressful situations that matter most. In those settings, the bi-level Deep Q-Network reduced task failures by about 29% to 63% compared with the other approaches, and improved overall reward by roughly 8% to 38%. The hierarchical structure proved more scalable than the flat learner as the number of RSUs and servers grew, and it remained robust even when communication between RSUs was somewhat unreliable or when predictions about a vehicle’s future route were imperfect.
What This Means for Everyday Drivers
In simple terms, the study shows that giving the road network a layered “learning brain” can make connected and autonomous vehicles more responsive and dependable. By first choosing the right roadside unit for each task and then planning how that task should survive delays and failures, the system keeps response times low and raises the chance that answers arrive before they are too late. While real-world deployment will still need to handle messy conditions and safety concerns, this work outlines a path toward smarter, fault-tolerant digital infrastructure that can keep up with the growing computational demands of future cars.
Citation: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Keywords: vehicular edge computing, task offloading, deep reinforcement learning, fault tolerance, intelligent transportation systems