Clear Sky Science · de
Ein zweistufiger mobilitätsbewusster Deep-Reinforcement-Learning-Ansatz für fehlertolerante Aufgaben-Auslagerung in vehikulärem Edge-Cloud-Computing
Intelligentere Straßen für datenhungrige Autos
Moderne Autos werden zu rollenden Computern, die ständig Kameraaufnahmen, Sensordaten und Navigationsinformationen verarbeiten. Ein Großteil dieser Arbeit muss in Millisekunden geschehen, um Fahrer zu schützen und Dienste reaktionsfähig zu halten. Diese Arbeit untersucht, wie man dieses Echtzeit-Computing zuverlässiger und schneller machen kann, indem koordiniert wird, wo die digitalen „Hausarbeiten“ eines Fahrzeugs erledigt werden — im Auto selbst, an kleinen Rechnern am Straßenrand oder in entfernten Cloud-Servern — selbst wenn der Verkehr dicht ist, Verbindungen instabil sind und Geräte gelegentlich ausfallen.
Warum Autos Hilfe von der Straße brauchen
Heutige vernetzte und autonome Fahrzeuge führen Aufgaben wie Objekterkennung, Spurhaltung und Augmented-Reality-Navigation aus. Alles allein im Fahrzeug zu berechnen würde leistungsfähige Hardware und erheblichen Energieeinsatz erfordern. Vehicular Edge Cloud Computing (VECC) begegnet dem, indem es Autos erlaubt, rechenintensive Aufgaben an Roadside Units (RSUs) — kleine Recheneinheiten am Straßenrand — auszulagern, die ihrerseits mit größeren Cloud-Servern kooperieren können. Dieses Szenario hat aber praktische Probleme: Fahrzeuge wechseln schnell zwischen RSUs, drahtlose Verbindungen fallen aus, und sowohl Edge- als auch Cloud-Maschinen können überlastet werden oder ausfallen. Zusammengenommen können diese Faktoren zu langen Verzögerungen oder gar zum Scheitern von Aufgaben führen — in zeitkritischen Fahranwendungen inakzeptabel.
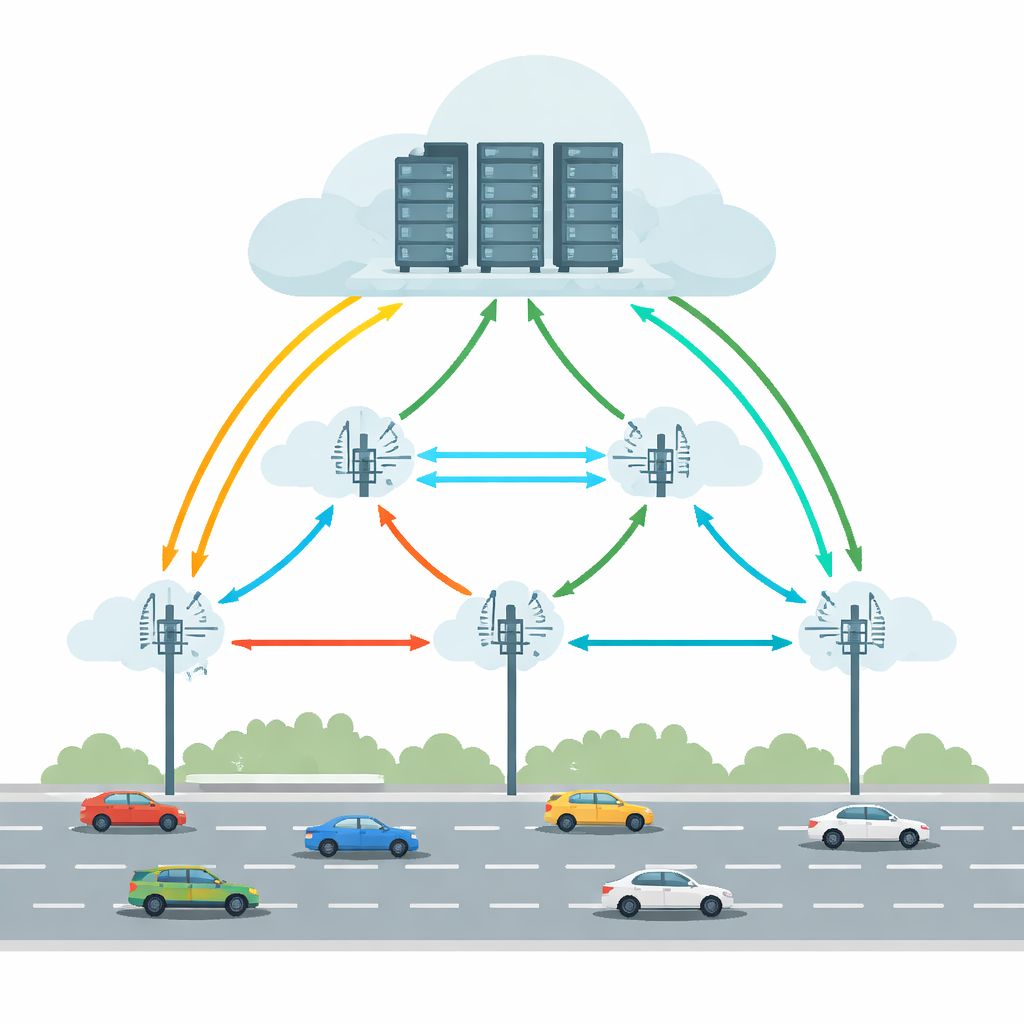
Bewegung, Verzögerungen und Ausfälle ausbalancieren
Viele frühere Systeme versuchten, das Offloading zu verbessern, indem sie vorhersagten, wo sich ein Fahrzeug befinden wird, Verzögerungen minimierten oder Energie einsparen wollten. Sie behandelten Zuverlässigkeit jedoch meist als Nebensache und gingen oft von stabilen Bedingungen aus. Die echten Straßen sind unordentlicher: drahtlose Verbindungen können abbrechen, Server können ausfallen, und Verkehrsmuster können sich plötzlich ändern. Dieses Papier argumentiert, dass eine praktikable Lösung Mobilität der Fahrzeuge, Netzwerkverzögerungen und Ausfallrisiken gleichzeitig über mehrere RSUs hinweg betrachten muss. Außerdem sollte sie ein einzelnes zentrales „Gehirn“, das bei wachsendem Straßennetz zum Flaschenhals wird, vermeiden. Stattdessen sollte die Entscheidungsfindung verteilt erfolgen, mit lokalen Einheiten, die schnell reagieren können und gleichzeitig aus dem größeren System lernen.
Zweistufige Lernmechanismen entlang der Straße
Die Autoren schlagen ein zweistufiges Entscheidungsframework vor, das von Deep Q-Networks angetrieben wird — einer Form von Deep Reinforcement Learning, die durch Versuch und Irrtum lernt. Auf der ersten Ebene wählt ein Lernagent — an jeder RSU repliziert —, welche RSU am besten geeignet ist, jede eingehende Aufgabe zu bearbeiten. Er berücksichtigt dabei die Auslastung jeder RSU, deren Rechenleistung, Ausfallneigungen und den erwarteten Fahrweg des Fahrzeugs sowie die Zeit, die benötigt wird, um Ergebnisse entlang dieses Weges zurückzusenden. Auf der zweiten Ebene, nachdem eine RSU gewählt wurde, entscheidet ein lokaler Agent genau, wie die Aufgabe ausgeführt werden soll: welcher Server primär sein soll, welcher als Backup dient und welches Ausfallwiederherstellungsmuster angewendet wird. Drei Strategien werden betrachtet: ein erneuter Versuch auf demselben Server, ein Wechsel zu einem Backup-Server nach einem Ausfall oder das parallele Ausführen von Primär- und Backup-Instanzen und die Übernahme des zuerst abgeschlossenen Ergebnisses.
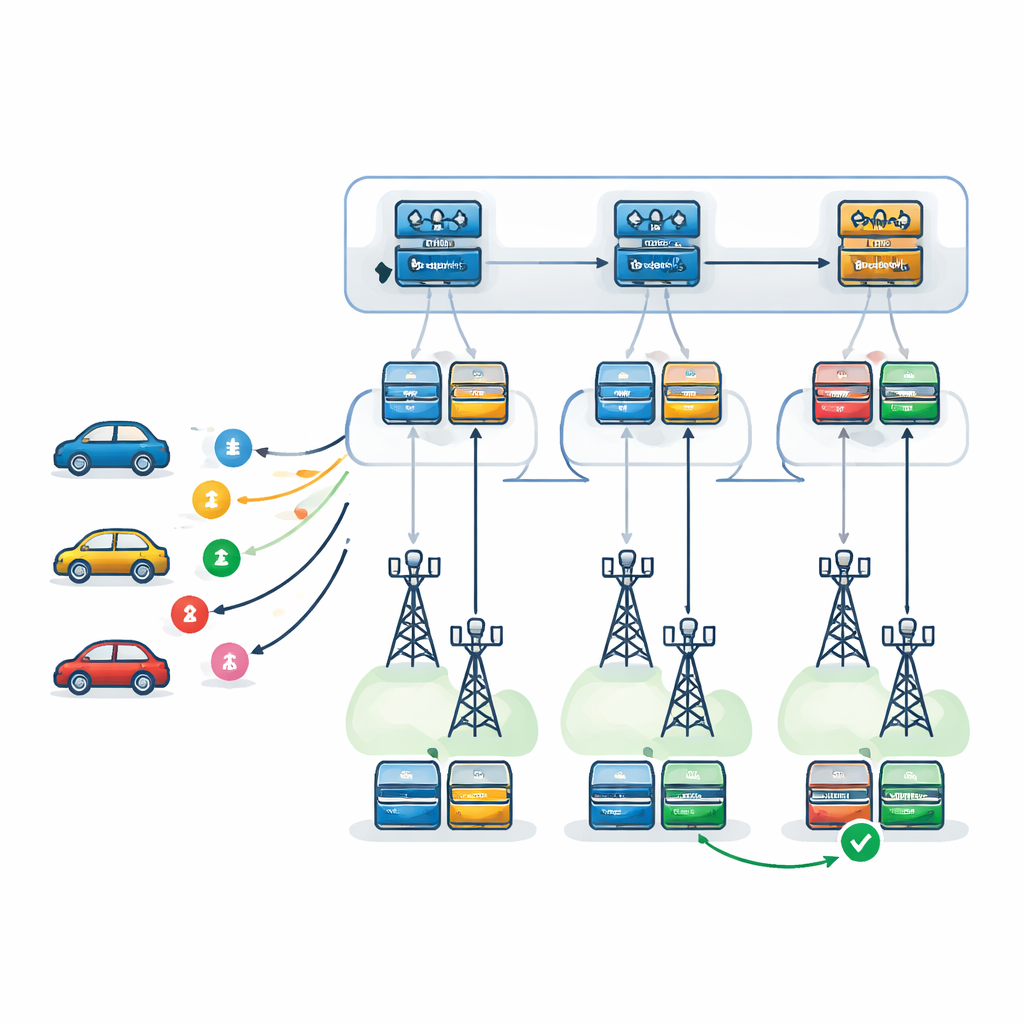
Test des Systems in einer virtuellen Stadt
Um zu prüfen, wie gut dieses zweistufige Lern-Setup funktioniert, bauten die Forschenden einen detaillierten Simulator, der ein Verkehrssystem (SUMO) mit einer ereignisbasierten Engine (SimPy) koppelt. Dadurch konnten sie fahrende Fahrzeuge, sich ändernde Funkbedingungen und realistische Warteschlangen an Edge- und Cloud-Servern modellieren. Sie verglichen ihre Methode mit mehreren Alternativen: einem ähnlichen zweistufigen System, das einen anderen Lernalgorithmus (Proximal Policy Optimization) verwendet, einer einfachen Greedy-Strategie, die immer die momentan scheinbar beste RSU wählt, einer No-Forwarding-Konfiguration, bei der Aufgaben nur von der RSU bearbeitet werden, die sie zuerst erhält, und einem einzelnen „flachen“ Lernagenten, der versucht, alle Entscheidungen gleichzeitig zu treffen. Über viele Episoden und unter unterschiedlichen Verkehrsstärken maßen sie durchschnittliche Belohnungen, Gesamtlatenz und wie oft Aufgaben fehlschlugen oder ihre Deadlines verpassten.
Was die Ergebnisse auf belebten Straßen zeigen
Bei geringem Verkehr und relativ lockeren Deadlines lieferten die meisten Methoden ähnliche Ergebnisse, da Ressourcen unterausgelastet waren. Unterschiede traten unter starkem, unausgeglichenem Verkehr und engeren Zeitvorgaben auf — genau die stressigen Situationen, die am wichtigsten sind. In diesen Szenarien reduzierte das zweistufige Deep Q-Network die Aufgabenfehler um etwa 29 % bis 63 % im Vergleich zu den anderen Ansätzen und verbesserte die Gesamtbelohnung um rund 8 % bis 38 %. Die hierarchische Struktur erwies sich als skalierbarer als der flache Lernende, wenn die Anzahl der RSUs und Server wuchs, und sie blieb robust, selbst wenn die Kommunikation zwischen RSUs etwas unzuverlässig war oder Vorhersagen über die künftige Route eines Fahrzeugs ungenau waren.
Was das für den Alltag der Fahrer bedeutet
Einfach ausgedrückt zeigt die Studie, dass ein geschichtetes „Lern-Gehirn“ im Straßennetz vernetzte und autonome Fahrzeuge reaktionsschneller und verlässlicher machen kann. Indem zuerst die richtige Roadside Unit für jede Aufgabe ausgewählt und dann geplant wird, wie diese Aufgabe Verzögerungen und Ausfälle überstehen soll, hält das System die Reaktionszeiten niedrig und erhöht die Wahrscheinlichkeit, dass Ergebnisse rechtzeitig eintreffen. Obwohl die reale Einführung weiterhin mit unordentlichen Bedingungen und Sicherheitsfragen umgehen muss, skizziert diese Arbeit einen Weg zu einer intelligenteren, fehlertoleranten digitalen Infrastruktur, die mit den wachsenden Rechenanforderungen zukünftiger Fahrzeuge Schritt halten kann.
Zitation: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Schlüsselwörter: vehikuläres Edge-Computing, Aufgaben-Auslagerung, Deep Reinforcement Learning, Fehlertoleranz, intelligente Verkehrssysteme