Clear Sky Science · sv
En tvånivå mobilitetsmedveten djupförstärkningslärande metod för felförtålig uppgiftsavlastning i fordonens kant-molnberäkning
Smartare vägar för datahungriga bilar
Moderna bilar blir rullande datorer som ständigt bearbetar kameraströmmar, sensordata och navigationsinformation. Mycket av detta arbete måste ske på millisekunder för att hålla förare säkra och tjänsterna responsiva. Denna artikel undersöker hur man kan göra sådan realtidsbearbetning mer tillförlitlig och snabbare genom att samordna var en fordons digitala "syssla" utförs — inne i bilen, vid små datorer vid vägkanten eller i avlägsna molnservrar — även när trafiken är tät, anslutningar ostadiga och enheter ibland går sönder.
Varför bilar behöver hjälp från vägen
Dagens uppkopplade och självkörande fordon kör uppgifter som objektigenkänning, filhållning och förstärkt verklighetsvägledning. Att göra allt detta enbart i bilen skulle kräva kraftfull hårdvara och mycket energi. Fordonskant-molnberäkning (VECC) tar itu med detta genom att låta bilar avlasta krävande uppgifter till Roadside Units (RSU) — små beräkningsstationer längs vägen — som i sin tur kan samarbeta med större molnservrar. Men denna uppställning möter praktiska problem: bilar rör sig snabbt mellan RSU:er, trådlänkar kommer och går, och både kant- och molnmaskiner kan bli överbelastade eller falla ur drift. Tillsammans kan dessa faktorer orsaka långa fördröjningar eller rena uppgiftsfel, vilket är oacceptabelt för tidskritiska fordonsapplikationer.
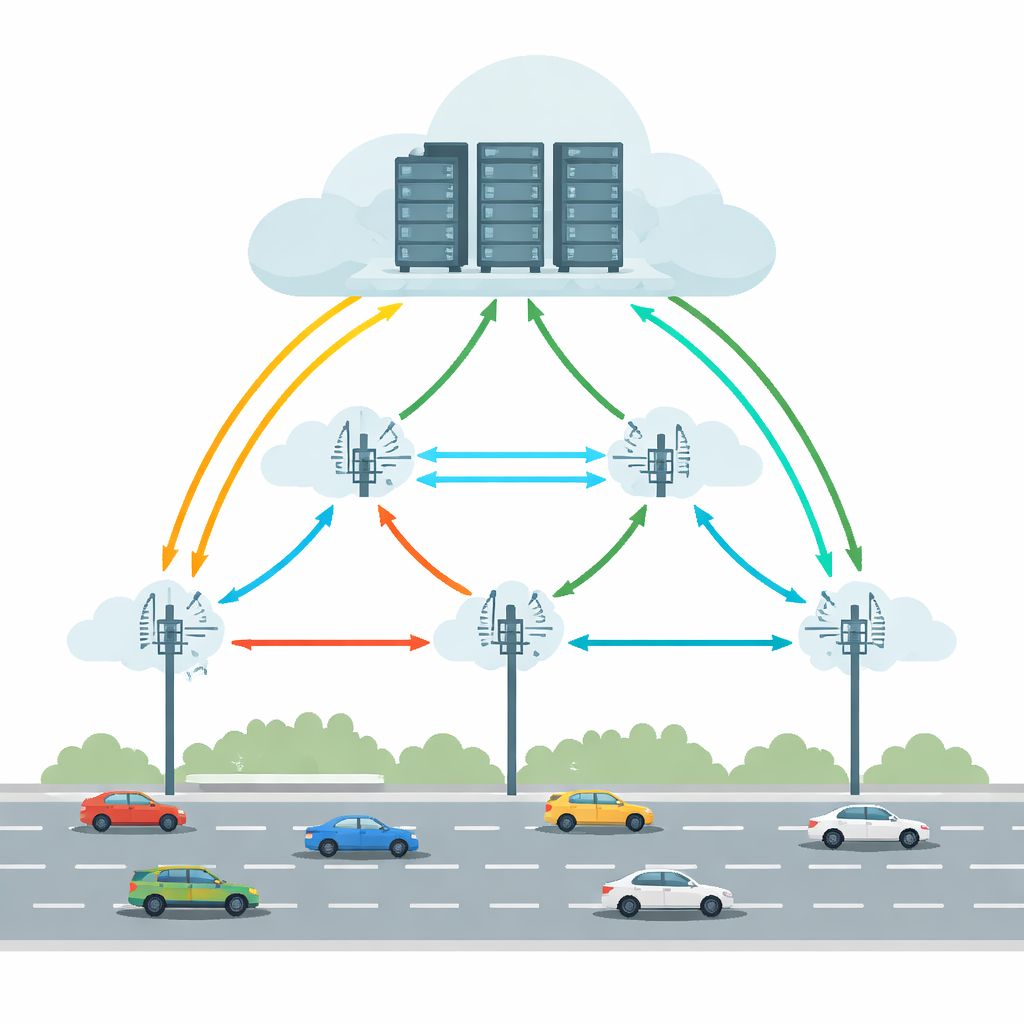
Att balansera rörelse, fördröjningar och fel
Många tidigare system försökte förbättra avlastningen genom att förutsäga var en bil kommer att befinna sig, minimera fördröjning eller spara energi. Men de behandlade ofta tillförlitlighet som en eftertanke och antog ofta stabila förhållanden. Riktiga vägar är rörigare: trådlänkar kan tappas, servrar kan misslyckas och trafikmönster kan ändras plötsligt. Denna artikel argumenterar för att en praktisk lösning måste beakta fordonsmobilitet, nätverksfördröjningar och risken för fel samtidigt, över flera RSU:er. Den måste också undvika en enda central "hjärna" som blir en flaskhals när vägnätet växer. Istället bör beslutsfattandet vara distribuerat, med lokala enheter som kan reagera snabbt samtidigt som de lär sig från det större systemet.
Tvånivåer av lärande längs vägen
Författarna föreslår ett tvånivås beslutsramverk drivet av Deep Q-Networks, en form av djup förstärkningsinlärning som lär sig genom försök och misstag. På första nivån väljer en lärande agent — replikerad vid varje RSU — vilken RSU som är bäst lämpad att hantera varje inkommande uppgift. Den tar hänsyn till varje RSU:s belastning, beräkningskraft, felbenägenhet och fordonets förväntade färdväg, samt tiden det tar att skicka tillbaka resultat längs den vägen. På andra nivån, när en RSU valts, beslutar en lokal agent exakt hur uppgiften ska utföras: vilken server som ska vara primär, vilken som ska fungera som backup och vilken felåterställningsstrategi som ska användas. Tre strategier beaktas: att försöka igen på samma server, att byta till en backupserver efter ett fel, eller att köra primär och backup parallellt och behålla den som blir klar först.
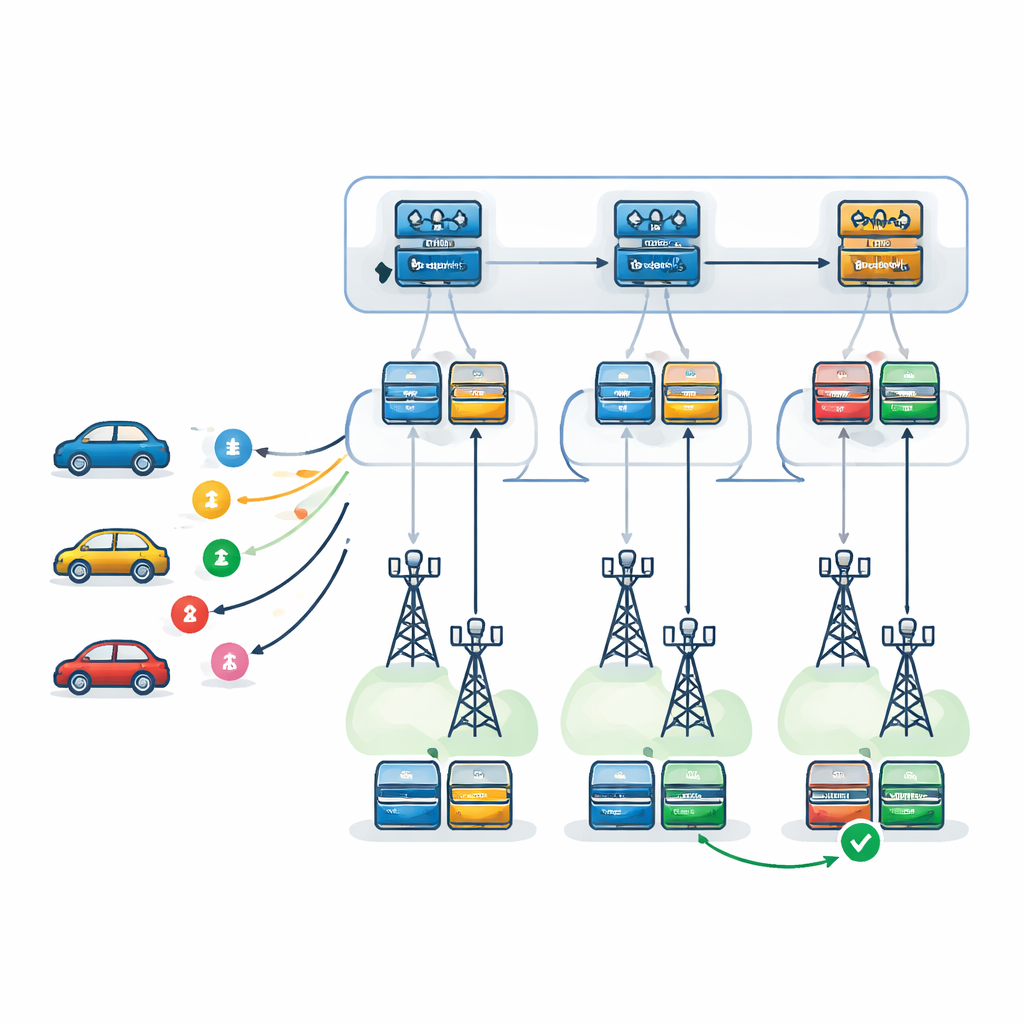
Test av systemet i en virtuell stad
För att se hur väl denna tvånivås uppsättning lärande fungerar byggde forskarna en detaljerad simulator som kopplar ett trafikschema (SUMO) med en händelsebaserad motor (SimPy). Detta gjorde det möjligt att modellera rörliga fordon, föränderliga trådliga förhållanden och realistiska köer vid kant- och molnservrar. De jämförde sin metod med flera alternativ: ett liknande tvånivås system som använder en annan inlärningsalgoritm (Proximal Policy Optimization), en enkel girig strategi som alltid väljer den till synes bästa RSU för tillfället, en setup utan vidarebefordran där uppgifter hanteras endast av den RSU som först tar emot dem, och en enstaka "platt" lärande agent som försöker fatta alla beslut på en gång. Över många episoder och under olika trafikintensiteter mätte de genomsnittliga belöningar, total fördröjning och hur ofta uppgifter misslyckades eller missade sina deadlines.
Vad resultaten visar på trafikerade vägar
Under lätt trafik och relativt slappa tidsfrister presterade de flesta metoder likartat eftersom resurser var underutnyttjade. Skillnaderna framträdde vid tät, obalanserad trafik och snävare tidskrav — precis de påfrestande situationer som är viktigast. I dessa scenarier minskade den tvånivåiga Deep Q-Network uppgiftsfel med cirka 29 % till 63 % jämfört med de andra tillvägagångssätten, och förbättrade den totala belöningen med ungefär 8 % till 38 %. Den hierarkiska strukturen visade sig vara mer skalbar än den platta inläraren när antalet RSU:er och servrar ökade, och den förblev robust även när kommunikationen mellan RSU:er var något opålitlig eller när förutsägelser om ett fordons framtida rutt var ofullständiga.
Vad detta betyder för vardagliga förare
Enkelt uttryckt visar studien att en lagerpålad "lärande hjärna" i vägnätet kan göra uppkopplade och autonoma fordon mer snabba och pålitliga. Genom att först välja rätt vägkantsenhet för varje uppgift och sedan planera hur uppgiften ska överleva fördröjningar och fel håller systemet svarstiderna låga och ökar sannolikheten att svaren anländer i tid. Även om verklig drift fortfarande måste hantera röriga förhållanden och säkerhetsfrågor skisserar detta arbete en väg mot smartare, feltolerant digital infrastruktur som kan hänga med de ökande beräkningsbehoven hos framtidens bilar.
Citering: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Nyckelord: fordonskantberäkning, uppgiftsavlastning, djup förstärkningsinlärning, feltolerans, intelligenta transportsystem