Clear Sky Science · fr
Une approche hiérarchique de deep reinforcement learning sensible à la mobilité pour le déchargement de tâches tolérant aux pannes dans l’informatique véhiculaire en bordure-cloud
Des routes plus intelligentes pour des voitures assoiffées de données
Les voitures modernes deviennent des ordinateurs roulants, traitant en continu des flux de caméras, des données de capteurs et des informations de navigation. Une grande partie de ce traitement doit s’effectuer en millisecondes pour garantir la sécurité des conducteurs et la réactivité des services. Cet article explore comment rendre ce calcul en temps réel plus fiable et plus rapide en coordonnant le lieu d’exécution des « corvées » numériques d’un véhicule — à l’intérieur de la voiture, sur de petits ordinateurs en bord de route ou sur des serveurs cloud distants — même lorsque la circulation est dense, les connexions fluctuantes et que des équipements tombent parfois en panne.
Pourquoi les voitures ont besoin d’aide depuis la route
Les véhicules connectés et autonomes d’aujourd’hui exécutent des tâches telles que la détection d’objets, le maintien de trajectoire et l’assistance en réalité augmentée. Tout faire uniquement à bord exigerait du matériel très puissant et une consommation d’énergie importante. L’informatique véhiculaire en bordure-cloud (VECC) répond à ce besoin en permettant aux voitures de décharger les tâches exigeantes vers des unités au bord de la route (RSU) — de petites stations de calcul le long des routes — qui peuvent à leur tour coopérer avec des serveurs cloud plus volumineux. Mais cette architecture rencontre des difficultés pratiques : les véhicules se déplacent rapidement entre les RSU, les liaisons sans fil sont intermittentes, et les machines d’edge ou du cloud peuvent se surcharger ou tomber en panne. Tous ces facteurs peuvent entraîner des retards importants ou des échecs de tâche, inacceptables pour des applications de conduite sensibles au temps.
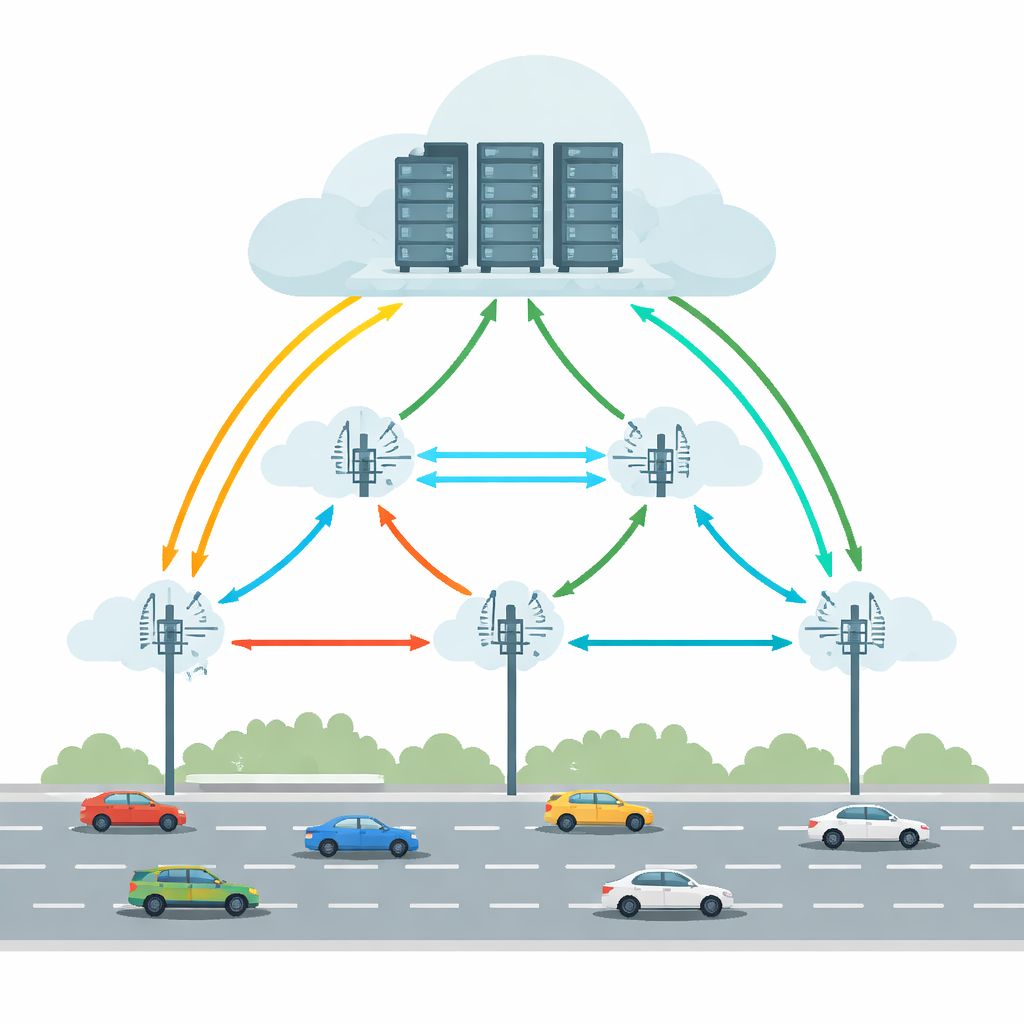
Équilibrer mobilité, latences et pannes
Beaucoup de systèmes antérieurs ont cherché à améliorer le déchargement en prédisant la position d’un véhicule, en minimisant la latence ou en économisant l’énergie. Toutefois, ils traitaient généralement la fiabilité comme un aspect secondaire et supposaient souvent des conditions stables. Les routes réelles sont plus désordonnées : les liaisons sans fil peuvent tomber, les serveurs peuvent échouer et les schémas de trafic peuvent changer brusquement. Cet article soutient qu’une solution pratique doit considérer simultanément la mobilité des véhicules, les délais réseau et le risque de pannes, et ce sur plusieurs RSU. Elle doit aussi éviter un « cerveau » central unique qui deviendrait un goulot d’étranglement à mesure que le réseau routier s’étend. La prise de décision devrait être distribuée, avec des unités locales capables de réagir rapidement tout en apprenant du système global.
Deux niveaux d’agents intelligents le long de la route
Les auteurs proposent un cadre décisionnel à deux niveaux alimenté par des Deep Q-Networks, un type d’apprentissage profond par renforcement qui apprend par essais et erreurs. Au premier niveau, un agent d’apprentissage — répliqué sur chaque RSU — choisit quel RSU est le mieux placé pour traiter chaque tâche entrante. Il prend en compte la charge de chaque RSU, sa puissance de calcul, ses tendances aux pannes, le trajet prévu du véhicule ainsi que le temps nécessaire pour renvoyer les résultats le long de ce trajet. Au second niveau, une fois l’RSU choisi, un agent local décide exactement comment exécuter la tâche : quel serveur doit être principal, lequel doit faire office de secours et quel schéma de récupération après panne utiliser. Trois stratégies sont envisagées : réessayer sur le même serveur, basculer vers un serveur de secours après une panne, ou exécuter le primaire et le secours en parallèle et garder celui qui termine en premier.
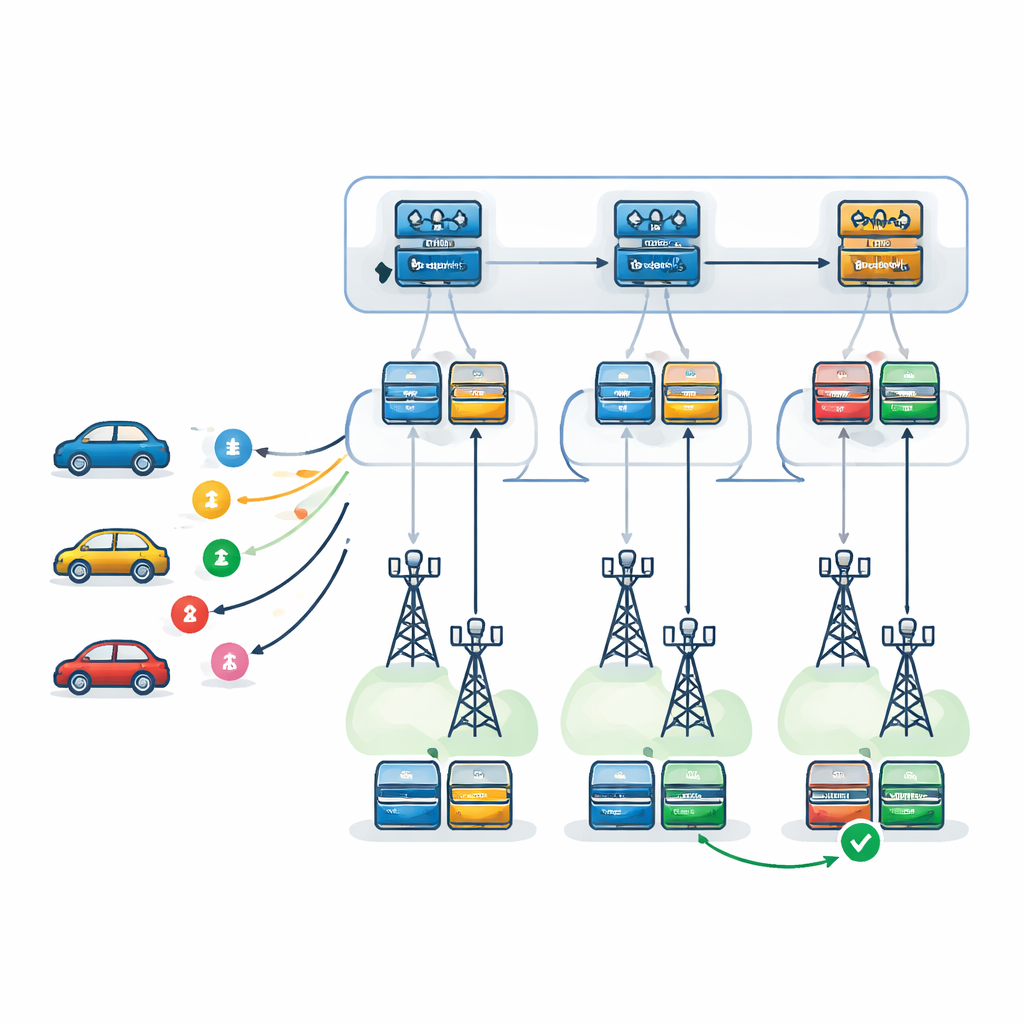
Tester le système dans une ville virtuelle
Pour évaluer l’efficacité de cette architecture à deux niveaux, les chercheurs ont construit un simulateur détaillé couplant un système de trafic (SUMO) à un moteur événementiel (SimPy). Cela leur a permis de modéliser des véhicules en mouvement, des conditions sans fil changeantes et des files d’attente réalistes aux serveurs d’edge et cloud. Ils ont comparé leur méthode à plusieurs alternatives : un système à deux niveaux similaire utilisant un autre algorithme d’apprentissage (Proximal Policy Optimization), une stratégie gourmande simple qui choisit toujours l’RSU apparemment le meilleur à l’instant, une configuration sans transfert où les tâches sont traitées uniquement par l’RSU qui les reçoit d’abord, et un agent d’apprentissage unique « plat » qui tente de prendre toutes les décisions à la fois. Sur de nombreux épisodes et sous différentes intensités de trafic, ils ont mesuré les récompenses moyennes, les délais globaux et la fréquence des échecs ou des dépassements de délai des tâches.
Ce que montrent les résultats sur des routes chargées
En condition de trafic léger et avec des délais assez laxistes, la plupart des méthodes ont des performances comparables car les ressources sont sous-utilisées. Les différences apparaissent en cas de trafic dense, déséquilibré et de contraintes temporelles plus strictes — exactement les situations stressantes qui comptent le plus. Dans ces contextes, le Deep Q-Network hiérarchique a réduit les échecs de tâches d’environ 29 % à 63 % par rapport aux autres approches, et a amélioré la récompense globale d’environ 8 % à 38 %. La structure hiérarchique s’est avérée plus évolutive que l’agent plat à mesure que le nombre de RSU et de serveurs augmentait, et elle est restée robuste même lorsque la communication entre RSU était quelque peu peu fiable ou lorsque les prédictions sur la trajectoire future d’un véhicule étaient imparfaites.
Ce que cela signifie pour les conducteurs au quotidien
En termes simples, l’étude montre que doter le réseau routier d’un « cerveau » d’apprentissage en couches peut rendre les véhicules connectés et autonomes plus réactifs et plus fiables. En choisissant d’abord la bonne unité au bord de la route pour chaque tâche, puis en planifiant comment cette tâche doit survivre aux délais et aux pannes, le système maintient des temps de réponse faibles et augmente la probabilité que les réponses arrivent à temps. Si le déploiement réel devra encore gérer des conditions chaotiques et des enjeux de sécurité, ce travail trace une voie vers une infrastructure numérique plus intelligente et tolérante aux pannes, capable de suivre la demande croissante en calcul des voitures de demain.
Citation: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Mots-clés: informatique en périphérie véhiculaire, déchargement de tâches, apprentissage profond par renforcement, tolérance aux pannes, systèmes de transport intelligents