Clear Sky Science · ru
Двухуровневый метод обучения с подкреплением с учётом мобильности для отказоустойчивого оффлоадинга задач в транспортно-краевом облачном вычислении
Более «умные» дороги для машин, жаждущих данных
Современные автомобили превращаются в передвижные компьютеры, постоянно обрабатывающие видеопотоки, данные датчиков и навигационную информацию. Большая часть этих вычислений должна выполняться за миллисекунды, чтобы сохранять безопасность водителей и отзывчивость сервисов. В статье рассматривается, как сделать такие вычисления в реальном времени более надёжными и быстрыми путём координации того, где выполняются цифровые «дела» автомобиля — внутри машины, на небольших компьютерах у обочины или на удалённых облачных серверах — даже когда движение плотное, связи ненадёжны, а устройства время от времени выходят из строя.
Зачем автомобилям помощь от дороги
Современные подключённые и автономные транспортные средства выполняют задачи типа обнаружения объектов, удержания полосы и дополненной реальности. Полагаться только на вычисления внутри автомобиля означало бы необходимость мощного оборудования и больших энергозатрат. Транспортно-краевое облачное вычисление (VECC) решает это, позволяя автомобилям передавать тяжёлые задачи на дорожные блоки (RSU) — небольшие вычислительные станции вдоль дороги, которые в свою очередь могут взаимодействовать с более крупными облачными серверами. Но такая схема сталкивается с практическими трудностями: автомобили быстро переходят между RSU, беспроводные каналы пропадают, а и краевые, и облачные машины могут перегружаться или выходить из строя. Всё это приводит к сильным задержкам или полным отказам задач, что недопустимо для критичных по времени приложений вождения.
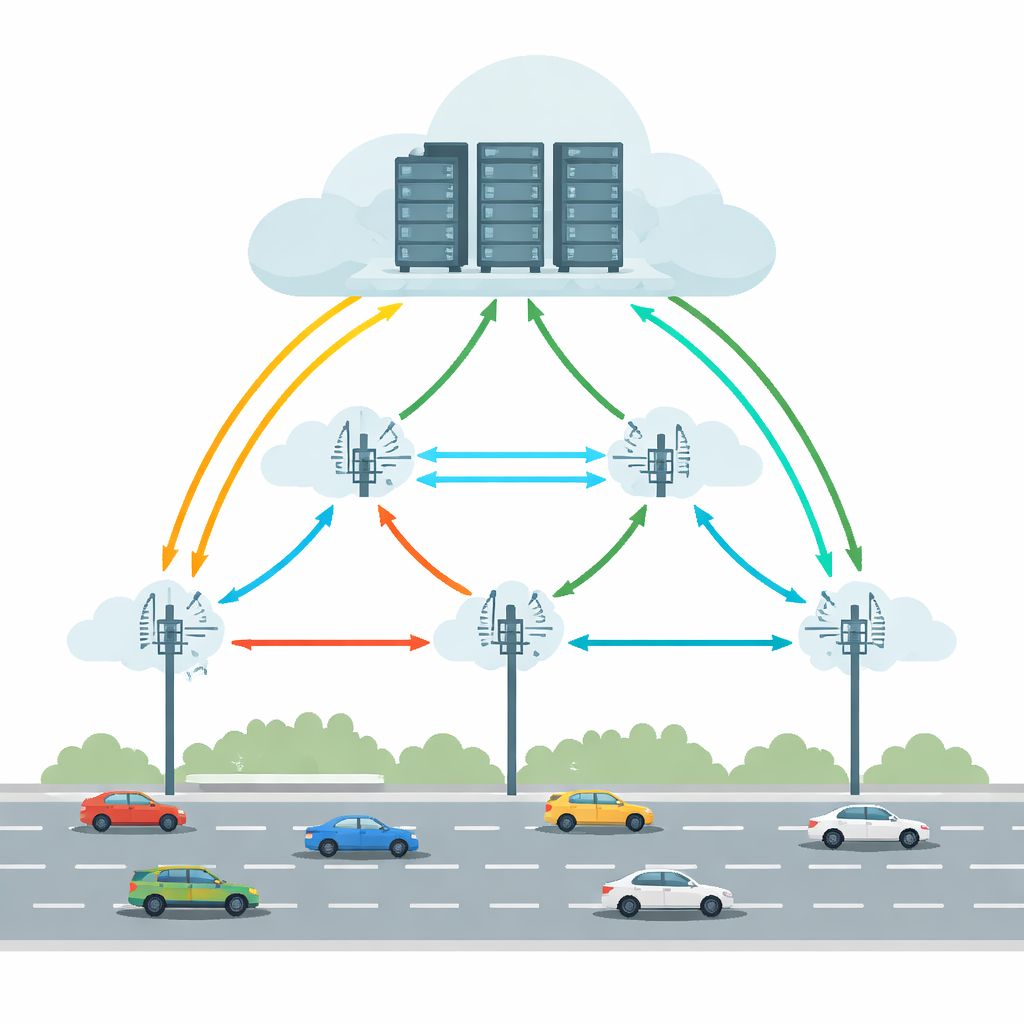
Баланс между движением, задержками и отказами
Многие предыдущие решения пытались улучшить оффлоадинг, прогнозируя положение автомобиля, минимизируя задержки или экономя энергию. Однако обычно надёжность рассматривалась как побочный эффект, а условия работы — как стабильные. На реальной дороге всё гораздо сложнее: беспроводные соединения могут прерываться, серверы — выходить из строя, а дорожные потоки — внезапно меняться. Авторы утверждают, что практичное решение должно учитывать мобильность транспортных средств, сетевые задержки и риск отказов одновременно и в пределах нескольких RSU. Кроме того, нужно избегать единой центральной «мозговой» системы, которая становится узким горлышком по мере роста сети. Вместо этого принятие решений должно быть распределённым: локальные узлы должны быстро реагировать, одновременно обучаясь на данных всей системы.
Двухуровневые «мозги» вдоль дорог
Авторы предлагают двухуровневую структуру принятия решений на основе Deep Q-Networks — разновидности глубокого обучения с подкреплением, обучающегося методом проб и ошибок. На первом уровне агент обучения — развернутый в каждом RSU — выбирает, какой RSU лучше справится с поступающей задачей. Он учитывает загрузку RSU, вычислительную мощность, склонность к отказам и ожидаемый маршрут автомобиля, а также время, необходимое для отправки результатов по этому маршруту. На втором уровне, после выбора RSU, локальный агент решает, как именно выполнить задачу: какой сервер будет основным, какой — резервным, и какую стратегию восстановления после отказа использовать. Рассматриваются три стратегии: повторная попытка на том же сервере, переключение на резервный сервер после отказа или параллельный запуск основного и резервного и сохранение результата того, кто закончит первым.
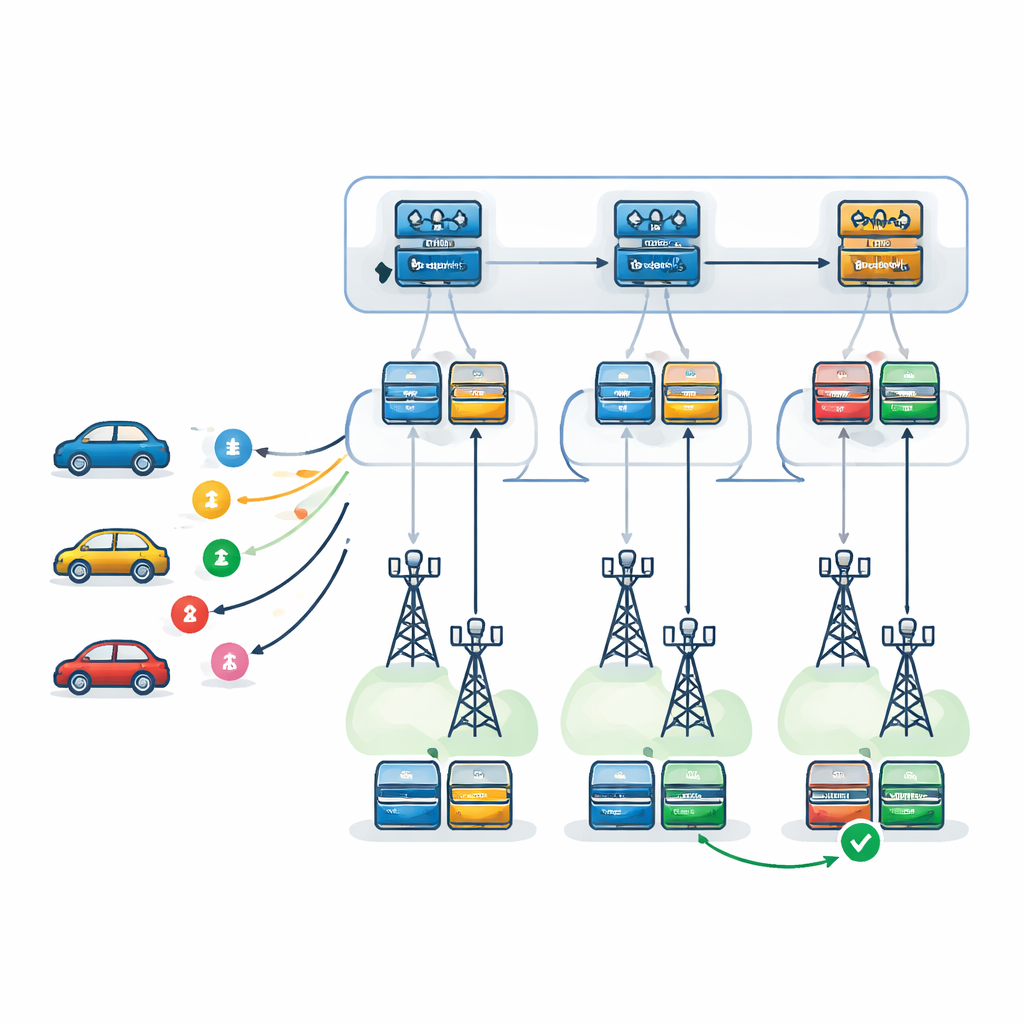
Тестирование системы в виртуальном городе
Чтобы оценить эффективность двухуровневой схемы обучения, исследователи построили подробный симулятор, сочетающий систему моделирования трафика (SUMO) с событийным движком (SimPy). Это позволило моделировать движущиеся транспортные средства, изменяющиеся беспроводные условия и реалистичные очереди на краевых и облачных серверах. Они сравнили свой метод с несколькими альтернативами: похожей двухуровневой системой на другом алгоритме обучения (Proximal Policy Optimization), простой жадной стратегией, которая всегда выбирает, по-видимому, лучший в момент RSU, схемой без форвардинга, где задачи обрабатываются только RSU, получившим их первым, и «плоским» агентом, который пытается принять все решения одновременно. В ряде прогонов и при разных интенсивностях трафика измерялись средние вознаграждения, общие задержки и частота отказов или пропуска дедлайнов задач.
Что показывают результаты на загруженных дорогах
При лёгком трафике и относительно свободных дедлайнах большинство методов работало похоже, поскольку ресурсы не были загружены. Различия проявились при плотном, несбалансированном трафике и жёстких временных ограничениях — именно в тех стрессовых ситуациях, которые важны больше всего. В таких условиях двухуровневая Deep Q-Network снизила число отказов задач примерно на 29%–63% по сравнению с другими подходами и улучшила общее вознаграждение примерно на 8%–38%. Иерархическая структура оказалась более масштабируемой, чем плоский агент, с ростом числа RSU и серверов, и оставалась устойчивой даже при частично ненадёжной связи между RSU или неточных прогнозах маршрута автомобиля.
Что это значит для повседневных водителей
Проще говоря, исследование показывает, что многослойный «обучающийся мозг» дорожной сети может сделать подключённые и автономные автомобили более отзывчивыми и надёжными. Сначала выбирая подходящий дорожный блок для каждой задачи, а затем планируя, как обеспечить выживание задачи в условиях задержек и отказов, система держит время отклика на низком уровне и увеличивает вероятность того, что ответ придёт вовремя. Хотя развертывание в реальном мире потребует учёта сложных условий и вопросов безопасности, эта работа прокладывает путь к более умной, отказоустойчивой цифровой инфраструктуре, способной справиться с растущими вычислительными потребностями будущих автомобилей.
Цитирование: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Ключевые слова: краевое вычисление для транспортных средств, оффлоадинг задач, глубокое обучение с подкреплением, отказоустойчивость, интеллектуальные транспортные системы