Clear Sky Science · tr
F-Transformer: verimli ve gizliliği koruyan dizi üretimi için federated transformer
Neden Daha Küçük, Daha Güvenli Dil Araçları Önemli
Her mesaj yazdığınızda, webde arama yaptığınızda veya telefonunuza diktede bulunurken, yazılım sessizce doğal görünen dili tahmin etmeye ve üretmeye çalışır. Bugünün en güçlü dil modelleri ise çok büyük, yoğun hesaplama gerektiren ve genellikle hassas metinlerin merkezi sunuculara gönderilmesini gerektiren sistemlerdir. Bu makale, mütevazı donanımlara uygun ölçüde hafif ve kullanıcı gizliliğine saygılı olacak şekilde dil modelleri oluşturmanın yeni bir yolunu sunuyor; üstelik bazı güncel öne çıkan sistemlerin performansını yakalıyor veya geride bırakıyor.
Dev Modellerden İnce Makinelere
Modern dil araçları tipik olarak transformer tabanlıdır; uzun cümleleri ve kelime ilişkilerindeki incelikleri iyi işleyen bir sinir ağı ailesidir. GPT-2 ve BERT gibi ünlü sistemler yüz milyonlarca ila milyarlarca iç parametreye dayanır; bu onları güçlü kılar fakat günlük cihazlarda çalıştırmayı zorlaştırır. Genellikle büyük miktarda metin toplamak zorunda olan merkezi veri merkezlerinde eğitilirler; bu da gizlilik ve veri sahipliği konusunda kaygılar doğurur. Yazarlar, hastanelerden mobil telefonlara kadar birçok gerçek dünya kullanımının çok daha küçük, daha az kaynak talep eden ve tüm ham veriyi tek bir yere toplamak zorunda kalmadan öğrenebilen dil modellerine ihtiyaç duyduğunu savunuyor.
Sırları Paylaşmadan Birlikte Öğrenmek
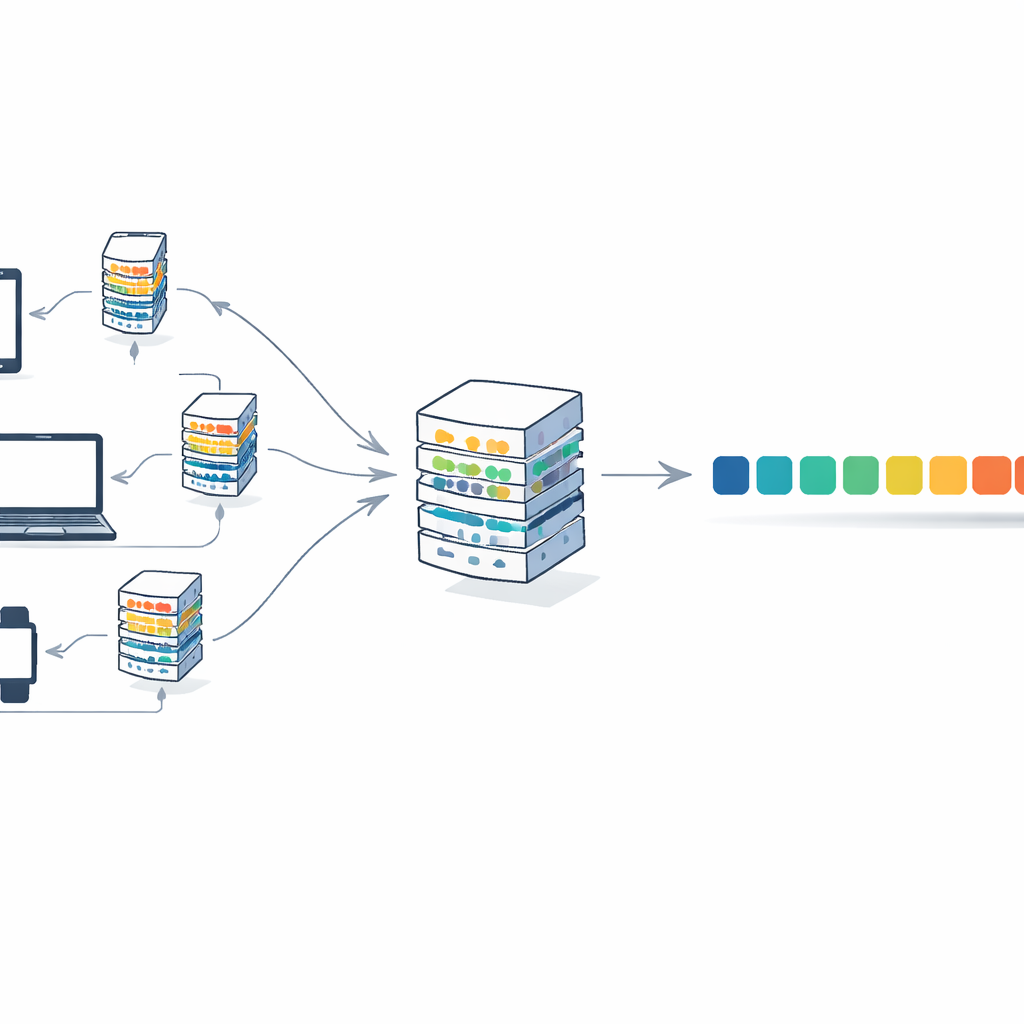
Bunu ele almak için makale transformerları federated learning adlı bir eğitim stratejisiyle birleştiriyor. Bu düzenekte birçok istemci—kurumlar veya cihazlar gibi—metinlerini yerel olarak tutar. Her istemci özel verisi üzerinde kendi model kopyasını eğitir ve yalnızca güncellenmiş model ağırlıklarını, metnin kendisini değil, merkezi bir sunucuya gönderir. Sunucu bu güncellemeleri ortalayarak tek bir küresel model oluşturur ve geri gönderir. Birçok tur boyunca model, farklı kaynaklardan gelen bilgileri birleştirerek gelişir; yine de ham belgeler hiç orijinal yerlerinden çıkmaz. Bu yaklaşım gizlilik risklerini azaltır ve hesaplama yükünü tek bir büyük makineye yüklemek yerine istemcilere yayar.
Paylaşım İçin İnşa Edilmiş Kompakt Tasarım
Yazarlar, bu dağıtılmış ve gizliliği gözeten dünya için baştan tasarlanmış bir transformer mimarisi olan F-Transformer’ı tanıtıyor. Mevcut dev bir modeli küçültmek yerine ince ayarlı seçimler yapıyorlar: yalnızca 4 attention head, 4 katman ve 64 boyutlu kelime temsilleriyle toplamda yaklaşık 0.87 milyon eğitilebilir parametre. Üç katmanlı bir çerçeve özetliyorlar: yerel metin ve tokenizasyonu yöneten veri katmanı; kompakt transformer ve federated averaging prosedürünü çalıştıran yapay zeka katmanı; ve metin üretimi, çeviri ve soru-cevap gibi uygulamaları birçok kuruluş arasında destekleyebilecek uygulama katmanı. Ayrıca teorik olarak doğruluk ve gizliliği tek bir eğitim hedefinde harmanlayan, bireysel kayıtlar hakkında çok fazla bilgi açığa çıkaran güncellemelere caydırıcı etki yapan matematiksel bir amaç fonksiyonu sunuyorlar.
Daha Az Güç ve Bellekle İyi Performans
F-Transformer’ı test etmek için yazarlar, modelin bir dizideki sonraki kelimeyi ne kadar iyi tahmin ettiğine odaklanarak yaygın olarak incelenen WikiText-2 Wikipedia makaleleri koleksiyonunu kullanıyorlar. Sadece tahmin kalitesini değil, aynı zamanda işlemci yükü ve bellek kullanımını değerlendirerek merkezi eğitim ile federated kurulumunu karşılaştırıyorlar. Çok küçük boyutuna rağmen F-Transformer, aynı ölçeğe normalleştirildiğinde BERT-Large ve GPT-2 varyantları dahil olmak üzere bazı çok daha büyük tanınmış modelleri geride bırakan bir doğrulama perplexity değeri (modelin metni ne kadar iyi öngördüğünün standart bir ölçüsü) elde ediyor. Aynı zamanda federated versiyon, karşılaştırılabilir merkezi bir tabana göre işlemci kullanımını yaklaşık %40 ve bellek tüketimini yaklaşık %34 oranında azaltıyor. Küçük model boyutu ayrıca iletişim maliyetlerini de büyük ölçüde düşürüyor: istemciler ve sunucu arasında model güncellemelerinin taşınması GPT-2 small’a kıyasla yüzlerce kat daha ucuz.
Günlük AI Kullanımı İçin Anlamı
Daha basit bir ifadeyle, çalışma birçok dağınık veri kaynağından öğrenen, ham metni gizli tutan ve mütevazı donanımlarda çalışabilen dil modelleri oluşturmanın mümkün olduğunu gösteriyor—üstelik performanstan ödün vermeden. F-Transformer, dikkatle tasarlanmış kompakt bir transformer’ın çok daha büyük sistemlerle rekabet edebileceğini veya onları geçebileceğini ve telefonlar, uç cihazlar veya hassas kurumsal ağlarda dağıtımını kolaylaştıracağını kanıtlıyor. Makalenin gizlilik garantileri büyük ölçüde mimari düzeyde olup resmi ölçümlerden çok daha fazlasını içermiyor ve daha çeşitli veriler üzerinde gerçek dünya testleri henüz yapılmayı bekliyor; yine de sonuçlar, yüksek kaliteli dil üretiminin devasa, merkezi ve potansiyel olarak müdahaleci AI altyapısı gerektirmeyen bir geleceğe işaret ediyor.
Atıf: Patel, N., Brahmbhatt, S., Ramoliya, F. et al. F-Transformer: a federated transformer for efficient and privacy-preserving sequence generation. Sci Rep 16, 14093 (2026). https://doi.org/10.1038/s41598-026-40881-0
Anahtar kelimeler: federated learning, transformer language model, gizliliği koruyan yapay zeka, hafif NLP, dizi üretimi