Clear Sky Science · he
F-Transformer: טרנספורמר פדרטיבי לדור רצפים יעיל ושומר פרטיות
מדוע כלים לשוניים קטנים ובטוחים חשובים
בכל פעם שאתם מקלידים הודעה, מחפשים ברשת או מדברים לטלפון, תוכנה מנסה ברקע לחזות וליצור שפה שנשמעת טבעית. עם זאת, המודלים השפתיים החזקים של היום עצומים, צורכים משאבי חישוב רבים ולעיתים דורשים שליחת טקסטים רגישים לשרתי מרכזיים. מאמר זה מציג שיטה חדשה לבניית מודלי שפה שהם מספיק קלים לחומרה צנועה וכיבודיים כלפי פרטיות המשתמש, ועדיין משיגים או עולים על ביצועים של מערכות בולטות כיום.
ממודלים ענקיים למכונות רזות
כלי שפה מודרניים מבוססים בדרך-כלל על טרנספורמרים, משפחה של רשתות נוירונים שמצטיינות בטיפול במשפטים ארוכים ובמובנות יחסי מילים עדינות. מערכות מוכרות כמו GPT-2 ו-BERT מסתמכות על מאות מיליוני פרמטרים ועד מיליארדים, מה שהופך אותן לחזקות אך גם לקשות להרצה במכשירים יום-יומיים. הן בדרך-כלל מאומנות במרכזי נתונים מרכזיים שצריכים לאסוף נפחי טקסט גדולים, מה שמעורר דאגות בנוגע לפרטיות ובעלות על הנתונים. המחברים טוענים כי שימושים רבים במציאות — מבתי חולים ועד טלפונים ניידים — זקוקים למודלי שפה הרבה יותר קטנים, לא תובעניים, ויכולים ללמוד מבלי לקרוע את כל הנתונים הגולמיים לאותו מקום.
לומדים יחד מבלי לחלוק סודות
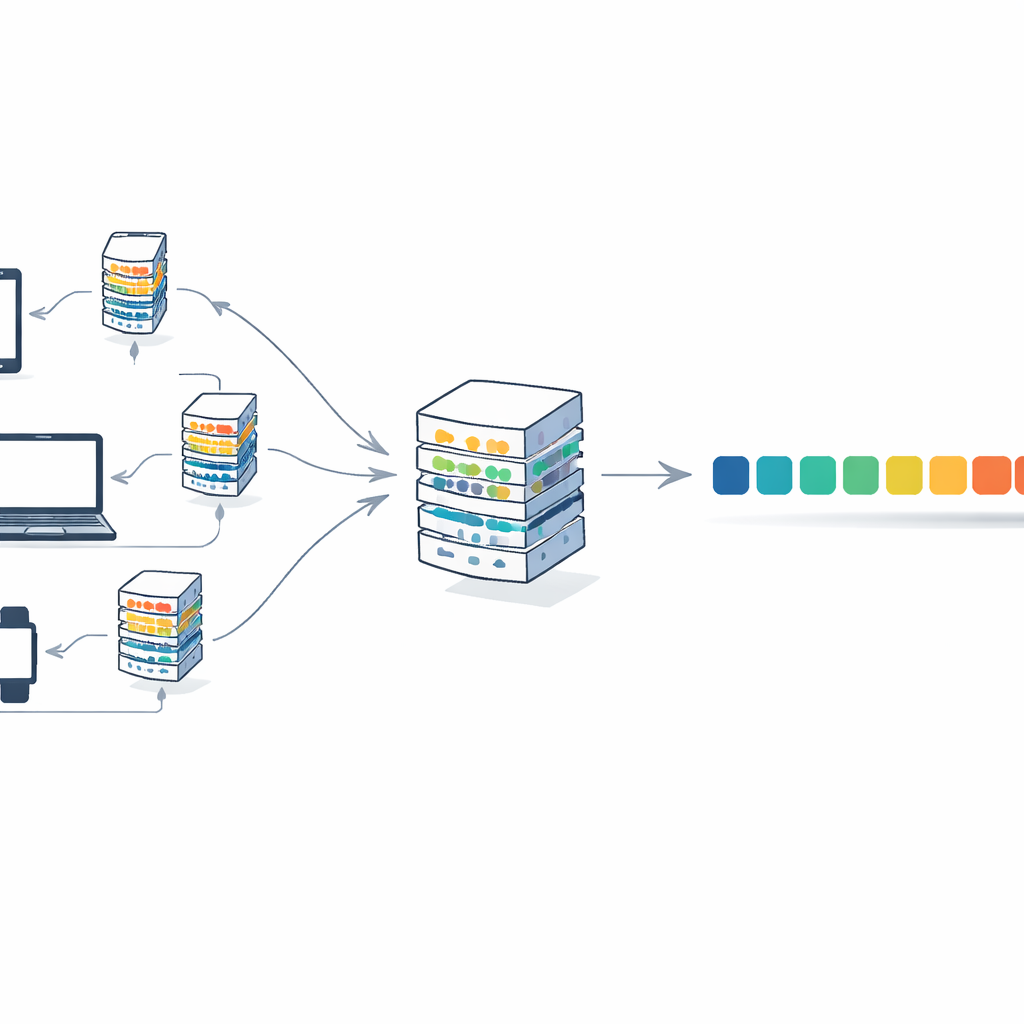
כדי להתמודד עם זאת, המאמר משלב טרנספורמר עם אסטרטגיית אימון שנקראת למידה פדרטיבית. בסידור זה, לקוחות רבים — מוסדות או מכשירים — שומרים את הטקסטים שלהם באופן מקומי. כל לקוח מאמן עותק של המודל על הנתונים הפרטיים שלו ושולח רק את משקלות המודל המעודכנות, לא את הטקסט עצמו, לשרת מרכזי. השרת ממוצע את העדכונים הללו למודל גלובלי אחד ושולח אותו חזרה. במהלך סבבים רבים המודל משתפר על ידי איגום הידע ממקורות מגוונים, ובו בזמן אף מסמכים גולמיים לא עוזבים את מיקומם המקורי. זה מקטין סיכוני פרטיות וגם מפזר את נטל החישוב בין הלקוחות במקום להסתמך על מכונה גדולה אחת.
עיצוב קומפקטי שנוצר לשיתוף
המחברים מציגים את F-Transformer, ארכיטקטורת טרנספורמר שנבנתה מלכתחילה לעולם מבוזר ורגיש לפרטיות. במקום להצניע מודל ענק קיים, הם בוחרים בהגדרות רזות: רק 4 ראשים של תשומת לב, 4 שכבות וייצוגי מילים מממד 64, לסך של בערך 0.87 מיליון פרמטרים ניתנים לאימון. הם מפרטים מסגרת תלת-שכבתית: שכבת נתונים המטפלת בטקסט המקומי ובטוקניזציה, שכבת בינה מלאכותית שמריצה את הטרנספורמר הקומפקטי ואת נוהל הממוצע הפדרטיבי, ושכבת יישום שיכולה לתמוך בשימושים כמו יצירת טקסט, תרגום ומענה על שאלות ברחבי ארגונים רבים. כמו כן הם מציגים מטרה מתמטית שמטרתה, לפחות בתיאוריה, לאחד דיוק ופרטיות למטרה אימונית אחת על ידי עידוד נגד עדכונים שיכולים לחשוף יותר מדי לגבי רשומות בודדות.
ביצועים עם פחות כוח וזיכרון
כדי לבדוק את F-Transformer, המחברים משתמשים באוסף המוכר WikiText-2 של מאמרי ויקיפדיה, ומתמקדים עד כמה המודל מנבא את המילה הבאה ברצף. הם מעריכים לא רק את איכות החיזוי אלא גם את עומס המעבד ושימוש בזיכרון, ומשווים בין אימון מרכזי לבין הסביבה הפדרטיבית שלהם. למרות גודלו הזעיר, F-Transformer משיג perplexity על קבוצת אימות — מדד סטנדרטי לאופן שבו מודל צופה טקסט — שעולה על מספר מודלים ידועים וגדולים בהרבה, כולל וריאנטים של BERT-Large ו-GPT-2, כאשר המספרים מנורמלים לאותה סקל. במקביל, הגרסה הפדרטיבית חותכת את שימוש המעבד בכ-40% ואת צריכת הזיכרון בכ-34% יחסית לבסיס מרכזי מקביל. גודל המודל הקטן גם מצמצם משמעותית עלויות תקשורת: העברת עדכוני מודל בין לקוחות לשרת זולה ביותר ממאה פעמים לעומת GPT-2 small.
מה זה אומר לשימוש יומיומי בבינה מלאכותית
במילים פשוטות, המחקר מראה שאפשר לבנות מודלי שפה שלומדים ממקורות נתונים מפוזרים, שומרים על טקסט גולמי פרטי ופועלים על חומרה צנועה — מבלי לוותר על ביצועים. F-Transformer מראה שמבנה טרנספורמר קומפקטי ומוקפד יכול להתחרות או לעקוף מערכות גדולות בהרבה ובאותו זמן להיות קל יותר לפריסה על טלפונים, מכשירי קצה או רשתות מוסדיות רגישות. אף שהערבויות לגבי פרטיות במאמר הן בעיקר ארכיטקטוניות ולא מדודות פורמלית, ונדרשים ניסויים ממשיים על נתונים מגוונים יותר, התוצאות מצביעות על עתיד שבו יצירת שפה איכותית לא דורשת תשתית בינה מלאכותית מרכזית, מסיבית ופוטנציאלית פולשנית.
ציטוט: Patel, N., Brahmbhatt, S., Ramoliya, F. et al. F-Transformer: a federated transformer for efficient and privacy-preserving sequence generation. Sci Rep 16, 14093 (2026). https://doi.org/10.1038/s41598-026-40881-0
מילות מפתח: למידה פדרטיבית, מודל שפה טרנספורמר, בינה מלאכותית שומרת פרטיות, עיבוד שפה טבעית קל משקל, יצירת רצפים