Clear Sky Science · ja
F-Transformer: 効率的でプライバシーを守る逐次生成のためのフェデレーテッド・トランスフォーマー
なぜ小さくて安全な言語ツールが重要なのか
メッセージを入力するたび、ウェブを検索するたび、あるいは携帯に声を吹き込むたびに、ソフトウェアは自然な言語を予測して生成しようとしています。しかし今日の最も強力な言語モデルは巨大で、計算資源を大量に消費し、敏感なテキストを中央サーバーに送ることを必要とする場合が多いです。本論文は、控えめなハードウェア上で動作でき、利用者のプライバシーを尊重しつつ、今日注目されるいくつかの大規模システムと同等かそれ以上の性能を達成できる言語モデルの新しい構築法を示します。
巨大モデルから効率的な小型機へ
現代の言語ツールは通常トランスフォーマーに基づいており、長い文や微妙な単語関係を扱うのが得意なニューラルネットワークの一群です。GPT-2やBERTのような有名システムは数億から数十億の内部パラメータを持ち、強力である一方で日常的な端末上で動かすのは困難です。これらは通常、大量のテキストを収集する中央のデータセンターで学習され、プライバシーやデータ所有権に関する懸念を生みます。著者らは、病院から携帯電話まで多くの実運用では、はるかに小さく負担の少ないモデルが必要であり、生のデータを一箇所に集めずに学習できることが重要だと主張します。
秘密を共有せずに一緒に学ぶ
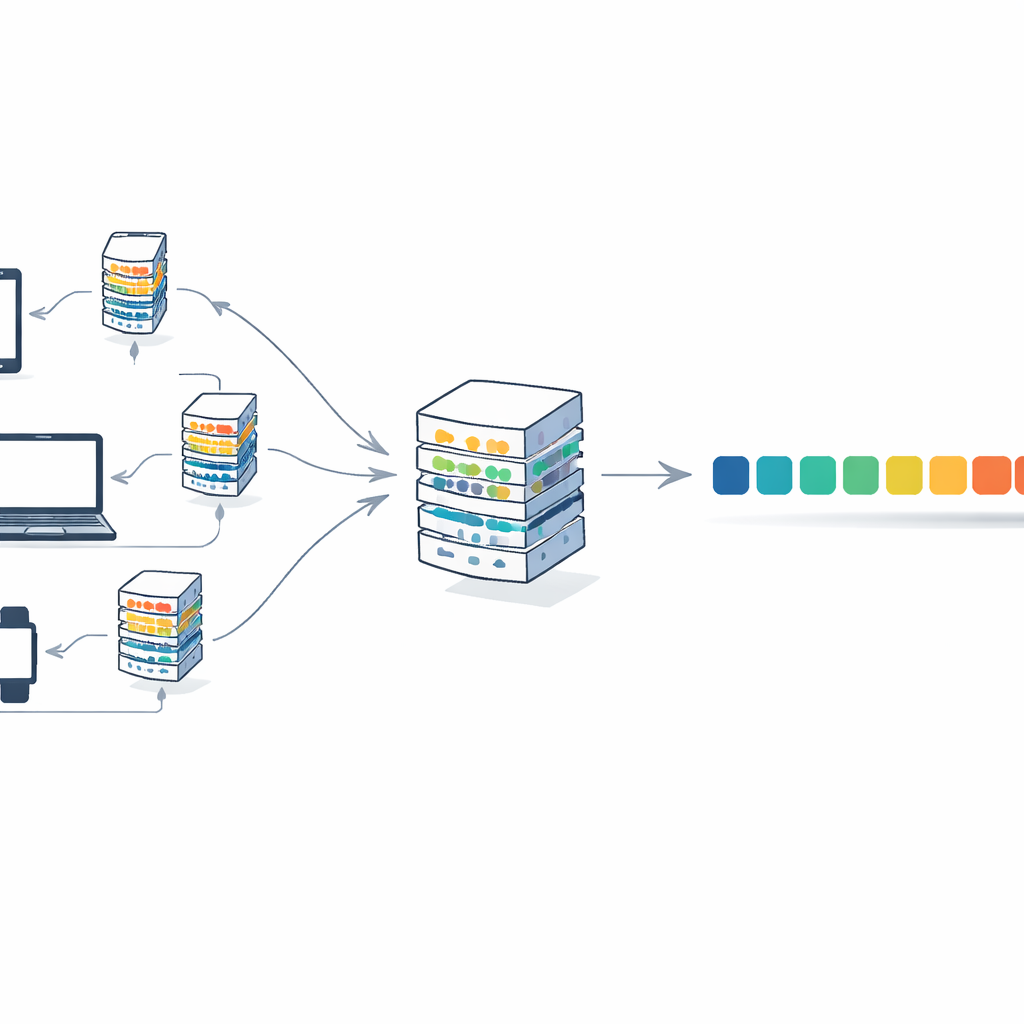
これに対処するため、本論文はトランスフォーマーとフェデレーテッドラーニングと呼ばれる学習戦略を組み合わせます。この仕組みでは、多くのクライアント(機関やデバイスなど)がテキストをローカルに保持します。各クライアントは自分のプライベートデータでモデルのコピーを訓練し、テキストそのものではなく更新されたモデルの重みだけを中央サーバーに送ります。サーバーはこれらの更新を平均化して単一のグローバルモデルを作り、再び各クライアントに返します。多くのラウンドを通じて、多様な情報源から知識を統合してモデルは改良されますが、生のドキュメントは元の場所を離れません。これによりプライバシーリスクが低減し、計算負荷も一台の大きな機械に頼るのではなくクライアント間で分散されます。
共有を念頭に置いたコンパクトな設計
著者らはF-Transformerを導入します。これは分散型でプライバシーに配慮した世界のために設計されたトランスフォーマーのアーキテクチャです。既存の巨大モデルを単に縮小するのではなく、意図的に軽量な設定を採用しています:アテンションヘッド4つ、層数4、単語表現の次元数64、合計で約0.87百万の学習可能パラメータという構成です。彼らは三層のフレームワークを概説します:ローカルテキストとトークナイズを扱うデータ層、コンパクトなトランスフォーマーとフェデレーテッド平均化手順を動かすAI層、そして多くの組織でのテキスト生成、翻訳、質問応答などを支えるアプリケーション層です。さらに、個々の記録について過度に情報を暴露する更新を抑制することで、理論的には精度とプライバシーを単一の訓練目的に組み込む数学的目的関数も提示しています。
少ない計算資源とメモリでの性能
F-Transformerを検証するため、著者らは広く研究されているWikiText-2(ウィキペディア記事のコレクション)を用い、次に来る単語の予測性能に注目します。予測品質だけでなくプロセッサ負荷やメモリ使用量も評価し、中央集権的な学習とフェデレーテッドな設定を比較しました。極めて小さいにも関わらず、F-Transformerは検証パープレキシティ(モデルがテキストをどれだけ予測できるかの標準指標)で、同スケールに正規化した場合にBERT-LargeやGPT-2系統を含むいくつかの著名で大きなモデルを上回ります。同時に、フェデレーテッド版は比較可能な中央集権ベースラインと比べてプロセッサ使用量を約40%削減し、メモリ消費を約34%削減します。モデルが小さいことで通信コストも大幅に削減され、クライアントとサーバー間でのモデル更新の移動はGPT-2 smallより100倍以上安くなります。
日常のAI利用にとっての意義
平たく言えば、この研究は、多数に分散したデータ源から学習し、生のテキストをプライベートに保ち、控えめなハードウェア上で動作できる言語モデルを、性能を損なうことなく構築できることを示しています。F-Transformerは、慎重に設計されたコンパクトなトランスフォーマーが、はるかに大きなシステムに匹敵するかそれを上回りつつ、携帯電話やエッジデバイス、あるいは機密性の高い機関ネットワークへの展開が容易であることを実証しています。論文のプライバシー保証は主にアーキテクチャ上のものであり形式的に測定されたものではないこと、またより多様なデータでの実運用テストが今後必要であることは残りますが、この結果は高品質な言語生成が巨大で中央集権的で侵襲的になりがちなAIインフラを必ずしも必要としない未来へ向かうことを示唆しています。
引用: Patel, N., Brahmbhatt, S., Ramoliya, F. et al. F-Transformer: a federated transformer for efficient and privacy-preserving sequence generation. Sci Rep 16, 14093 (2026). https://doi.org/10.1038/s41598-026-40881-0
キーワード: フェデレーテッドラーニング, トランスフォーマー言語モデル, プライバシー保護型AI, 軽量NLP, 逐次生成