Clear Sky Science · ru
F-Transformer: федеративный трансформер для эффективной и защищающей конфиденциальность генерации последовательностей
Почему важны более компактные и безопасные языковые инструменты
Каждый раз, когда вы печатаете сообщение, ищете что-то в интернете или диктуете текст телефону, программное обеспечение пытается предсказать и сгенерировать естественно звучащий язык. Однако самые мощные современные языковые модели огромны, требуют больших вычислительных ресурсов и часто предполагают отправку чувствительного текста на центральные серверы. В этой статье представлен новый подход к построению языковых моделей, которые достаточно легкие для скромного оборудования и уважают приватность пользователей, при этом по качеству сопоставимы или превосходят некоторые широко обсуждаемые системы.
От гигантов к компактным машинам
Современные языковые инструменты обычно основаны на трансформерах — семействе нейросетей, отлично справляющихся с длинными предложениями и тонкими связями между словами. Известные системы, такие как GPT-2 и BERT, содержат сотни миллионов или миллиарды параметров, что делает их мощными, но трудными для запуска на повседневных устройствах. Обычно их обучают в централизованных дата-центрах, которые собирают большие объемы текста, что вызывает опасения по поводу приватности и прав на данные. Авторы утверждают, что для многих практических применений — от больниц до мобильных телефонов — нужны модели, которые гораздо меньшие, менее ресурсоемкие и способны обучаться без сбора всех исходных данных в одном месте.
Учимся вместе, не раскрывая секретов
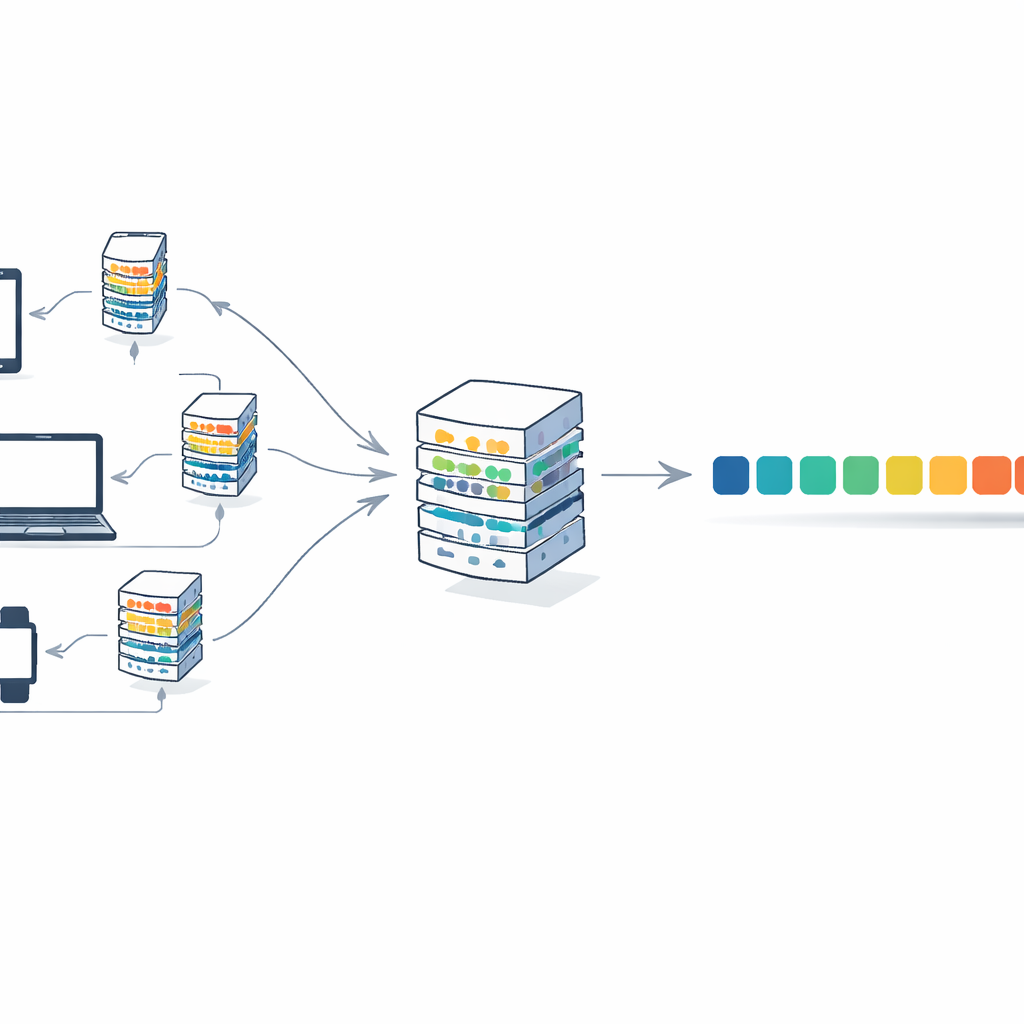
Чтобы решить эту проблему, статья сочетает трансформеры со стратегией обучения, называемой федеративным обучением. В такой схеме многие клиенты — например, учреждения или устройства — хранят свои тексты локально. Каждый клиент обучает свою копию модели на приватных данных и отправляет на центральный сервер только обновленные веса модели, а не сами тексты. Сервер усредняет эти обновления в единый глобальный модел и отправляет его обратно. За множество раундов модель улучшается за счет объединения знаний из разных источников, при этом сырые документы никогда не покидают свои исходные места. Это снижает риски для приватности и распределяет вычислительную нагрузку между клиентами, вместо того чтобы полагаться на одну большую машину.
Компактная архитектура, созданная для совместного использования
Авторы представляют F-Transformer — архитектуру трансформера, разработанную с нуля для этого распределенного, ориентированного на приватность подхода. Вместо того чтобы уменьшать существующую гигантскую модель, они выбрали компактные параметры: всего 4 механизма внимания, 4 слоя и 64-мерные представления слов, что в сумме даёт порядка 0,87 миллиона обучаемых параметров. Они описывают трёхуровневую структуру: слой данных, который обрабатывает локальный текст и токенизацию; слой искусственного интеллекта, который запускает компактный трансформер и процедуру федеративного усреднения; и прикладной слой, поддерживающий такие задачи, как генерация текста, перевод и ответы на вопросы в различных организациях. Авторы также представляют математическую цель, которая, по крайней мере теоретически, сочетает точность и приватность в одном обучающем критерии, препятствуя обновлениям, раскрывающим слишком много об отдельных записях.
Производительность при меньших затратах энергии и памяти
Для проверки F-Transformer авторы используют широко изученную коллекцию WikiText-2 из статей Википедии, оценивая, насколько хорошо модель предсказывает следующее слово в последовательности. Они измеряют не только качество предсказаний, но и нагрузку на процессор и использование памяти, сравнивая централизованное обучение с их федеративной схемой. Несмотря на крошечный размер, F-Transformer достигает валидационной перплексии — стандартной метрики того, насколько хорошо модель предугадывает текст — которая превосходит несколько известных, гораздо больших моделей, включая варианты BERT-Large и GPT-2, при нормировке показателей к одному масштабу. В то же время федеративная версия сокращает использование процессора примерно на 40 процентов и потребление памяти примерно на 34 процента по сравнению с сопоставимым централизованным эталоном. Малый размер модели также резко уменьшает затраты на коммуникацию: передача обновлений модели между клиентами и сервером более чем в сто раз дешевле, чем для GPT-2 small.
Что это значит для повседневного использования ИИ
Проще говоря, исследование показывает: возможно построить языковые модели, которые обучаются на множестве разбросанных источников данных, сохраняют сырые тексты приватными и работают на скромном оборудовании — без потери качества. F-Transformer доказывает, что тщательно спроектированный компактный трансформер может соперничать и даже превосходить намного большие системы, при этом его проще развернуть на телефонах, периферийных устройствах или в чувствительных институциональных сетях. Хотя гарантии приватности в статье в основном архитектурные, а не формально измеренные, и реальные испытания на более разнообразных данных ещё впереди, результаты указывают на будущее, где качественная генерация языка не требует массивной, централизованной и потенциально навязчивой инфраструктуры ИИ.
Цитирование: Patel, N., Brahmbhatt, S., Ramoliya, F. et al. F-Transformer: a federated transformer for efficient and privacy-preserving sequence generation. Sci Rep 16, 14093 (2026). https://doi.org/10.1038/s41598-026-40881-0
Ключевые слова: федеративное обучение, языковая модель трансформер, конфиденциальный ИИ, легкий NLP, генерация последовательностей