Clear Sky Science · es
F-Transformer: un transformer federado para generación de secuencias eficiente y respetuosa con la privacidad
Por qué importan herramientas de lenguaje más pequeñas y seguras
Cada vez que escribes un mensaje, buscas en la web o dictas a tu teléfono, un software intenta en silencio predecir y generar lenguaje con aspecto natural. Sin embargo, los modelos de lenguaje más potentes de hoy son enormes, demandan mucha potencia de cálculo y a menudo requieren enviar textos sensibles a servidores centrales. Este artículo presenta una nueva forma de construir modelos de lenguaje que son lo bastante ligeros para hardware modesto y respetuosos con la privacidad del usuario, a la vez que igualan o superan el rendimiento de algunos de los sistemas más mediáticos actuales.
De modelos gigantes a máquinas esbeltas
Las herramientas modernas de lenguaje suelen basarse en transformers, una familia de redes neuronales que sobresalen en manejar frases largas y relaciones sutiles entre palabras. Sistemas famosos como GPT-2 y BERT dependen de cientos de millones a miles de millones de parámetros internos, lo que los hace potentes pero también difíciles de ejecutar en dispositivos cotidianos. Por lo general se entrenan en centros de datos centralizados que deben recopilar grandes volúmenes de texto, lo que suscita preocupaciones sobre privacidad y propiedad de los datos. Los autores sostienen que muchos usos del mundo real, desde hospitales hasta teléfonos móviles, necesitan modelos de lenguaje mucho más pequeños, menos exigentes y capaces de aprender sin reunir todos los datos crudos en un único lugar.
Aprender juntos sin compartir secretos
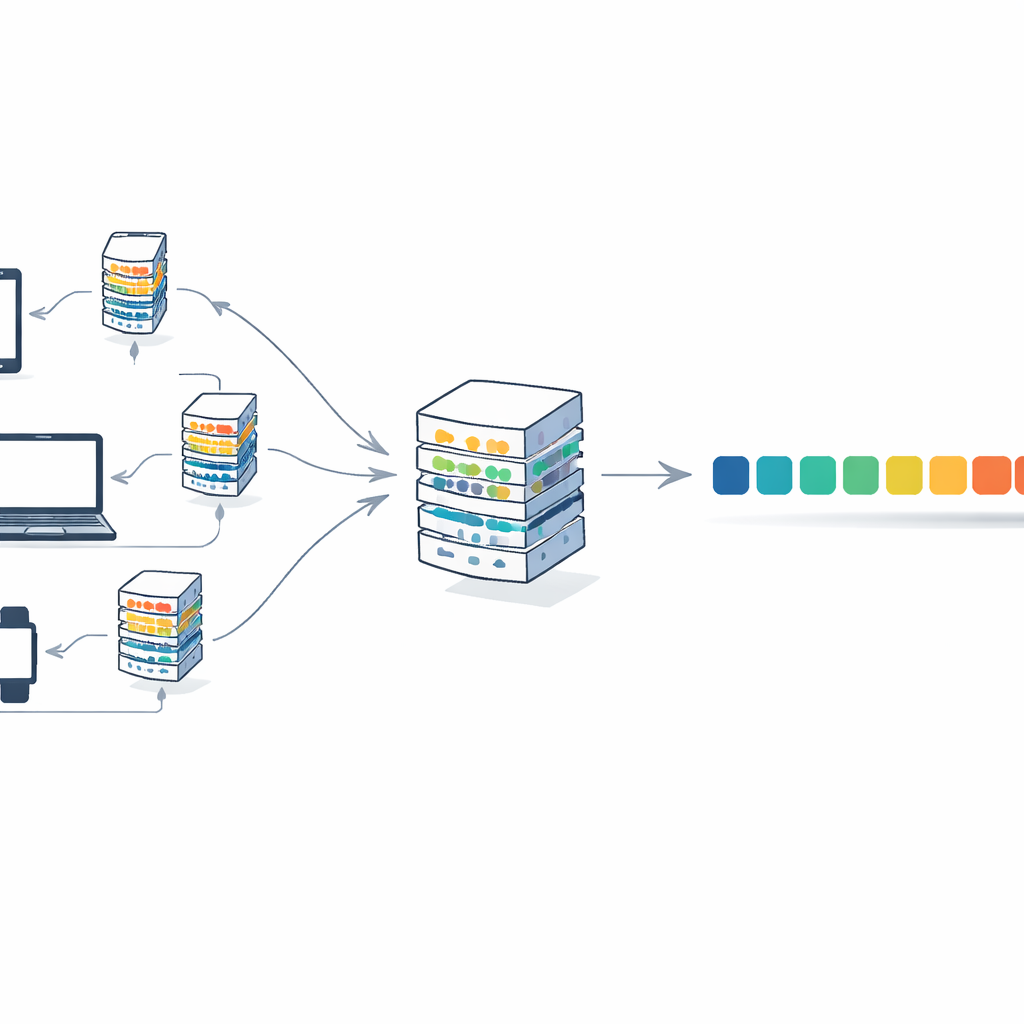
Para abordar esto, el artículo combina transformers con una estrategia de entrenamiento llamada aprendizaje federado. En este esquema, muchos clientes —como instituciones o dispositivos— conservan su texto localmente. Cada cliente entrena su propia copia del modelo con sus datos privados y envía únicamente los pesos del modelo actualizados, no el texto, a un servidor central. El servidor promedia esas actualizaciones en un único modelo global y lo devuelve. A lo largo de muchas rondas, el modelo mejora al agregar conocimiento de fuentes diversas, sin que documentos crudos salgan de sus ubicaciones originales. Esto reduce los riesgos para la privacidad y además reparte la carga computacional entre los clientes en lugar de depender de una sola máquina grande.
Un diseño compacto pensado para compartirse
Los autores presentan F-Transformer, una arquitectura transformer diseñada desde cero para este mundo distribuido y consciente de la privacidad. En lugar de encoger un modelo gigante existente, eligen configuraciones delgadas: solo 4 cabezas de atención, 4 capas y representaciones de palabras de 64 dimensiones, para un total de alrededor de 0,87 millones de parámetros entrenables. Esbozan un marco de tres capas: una capa de datos que gestiona el texto local y la tokenización, una capa de inteligencia artificial que ejecuta el transformer compacto y el procedimiento de promedio federado, y una capa de aplicación que puede soportar usos como generación de texto, traducción y respuesta a preguntas entre muchas organizaciones. También presentan un objetivo matemático que, al menos en teoría, combina precisión y privacidad en una sola meta de entrenamiento al desincentivar actualizaciones que revelen demasiado sobre registros individuales.
Rendimiento con menos potencia y memoria
Para probar F-Transformer, los autores usan la ampliamente estudiada colección WikiText-2 de artículos de Wikipedia, centrándose en qué tan bien el modelo predice la siguiente palabra en una secuencia. Evalúan no solo la calidad de la predicción sino también la carga del procesador y el uso de memoria, comparando el entrenamiento centralizado con su configuración federada. A pesar de su tamaño diminuto, F-Transformer logra una perplexidad de validación —una medida estándar de qué tan bien un modelo anticipa el texto— que supera a varios modelos conocidos mucho más grandes, incluyendo variantes de BERT-Large y GPT-2, cuando los números se normalizan a la misma escala. Al mismo tiempo, la versión federada reduce el uso del procesador en aproximadamente un 40% y el consumo de memoria en alrededor de un 34% respecto a una referencia centralizada comparable. El pequeño tamaño del modelo también reduce drásticamente los costes de comunicación: mover las actualizaciones del modelo entre clientes y servidor es más de cien veces más barato que con GPT-2 small.
Lo que esto significa para el uso cotidiano de la IA
En términos sencillos, el estudio muestra que es posible construir modelos de lenguaje que aprendan de muchas fuentes de datos dispersas, mantengan el texto crudo privado y funcionen en hardware modesto —sin renunciar al rendimiento. F-Transformer demuestra que un transformer compacto y cuidadosamente diseñado puede rivalizar o superar sistemas mucho más grandes y al mismo tiempo ser más fácil de desplegar en teléfonos, dispositivos de borde o redes institucionales sensibles. Aunque las garantías de privacidad del artículo son principalmente arquitectónicas más que formalmente medidas, y aún faltan pruebas en el mundo real con datos más variados, los resultados apuntan a un futuro en el que la generación de lenguaje de alta calidad no requiera una infraestructura de IA masiva, centralizada y potencialmente intrusiva.
Cita: Patel, N., Brahmbhatt, S., Ramoliya, F. et al. F-Transformer: a federated transformer for efficient and privacy-preserving sequence generation. Sci Rep 16, 14093 (2026). https://doi.org/10.1038/s41598-026-40881-0
Palabras clave: aprendizaje federado, modelo de lenguaje transformer, IA respetuosa con la privacidad, PNL ligera, generación de secuencias