Clear Sky Science · it
F-Transformer: un trasformatore federato per la generazione di sequenze efficiente e rispettosa della privacy
Perché contano strumenti linguistici più piccoli e più sicuri
Ogni volta che scrivi un messaggio, cerchi sul web o detti al telefono, un software cerca silenziosamente di prevedere e generare linguaggio naturale. I modelli linguistici più potenti di oggi, tuttavia, sono enormi, richiedono molta potenza di calcolo e spesso richiedono l’invio di testo sensibile a server centrali. Questo articolo presenta un nuovo modo di costruire modelli linguistici che sono sufficientemente leggeri per hardware modesti e rispettosi della privacy degli utenti, pur pareggiando o superando le prestazioni di alcuni dei sistemi più noti di oggi.
Dai modelli giganti a macchine snelle
Gli strumenti linguistici moderni si basano tipicamente sui transformer, una famiglia di reti neurali eccellente nel gestire frasi lunghe e relazioni sottili tra parole. Sistemi famosi come GPT-2 e BERT si affidano a centinaia di milioni fino a miliardi di parametri interni, il che li rende potenti ma anche difficili da eseguire su dispositivi di uso quotidiano. Di solito si addestrano in centri dati centralizzati che devono raccogliere grandi volumi di testo, sollevando preoccupazioni su privacy e proprietà dei dati. Gli autori sostengono che molti usi nel mondo reale, dagli ospedali ai telefoni cellulari, richiedono modelli linguistici molto più piccoli, meno esigenti e in grado di apprendere senza aggregare tutti i dati grezzi in un unico luogo.
Imparare insieme senza condividere i segreti
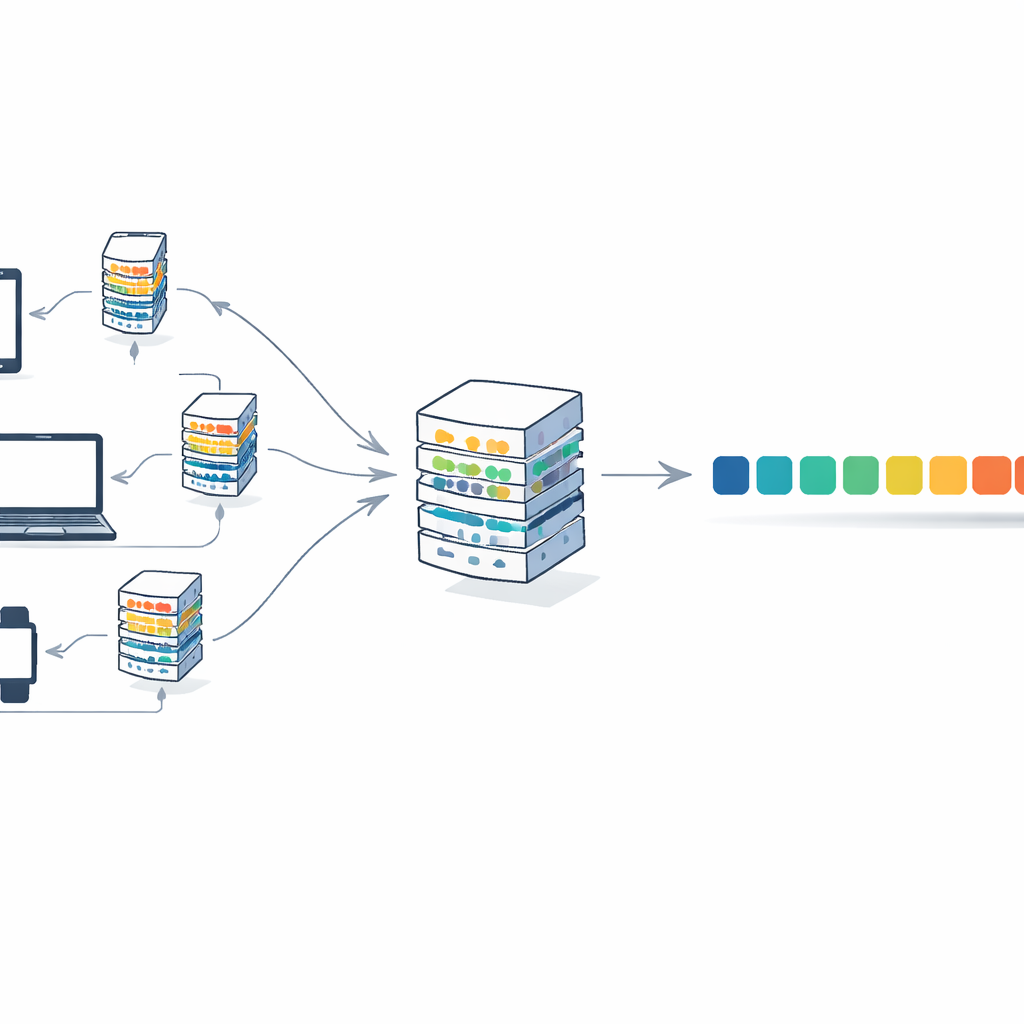
Per affrontare questo problema, l’articolo combina i transformer con una strategia di addestramento chiamata apprendimento federato. In questo schema, molti client — come istituzioni o dispositivi — mantengono i loro testi localmente. Ciascun client addestra la propria copia del modello sui dati privati e invia solo i pesi aggiornati del modello, non il testo stesso, a un server centrale. Il server media questi aggiornamenti in un singolo modello globale e lo rimanda indietro. Nel corso di molte iterazioni, il modello migliora mettendo insieme conoscenze provenienti da fonti diverse, pur non facendo mai uscire i documenti grezzi dai loro luoghi d’origine. Questo riduce i rischi per la privacy e distribuisce anche il carico computazionale sui client anziché dipendere da una singola macchina potente.
Un design compatto pensato per la condivisione
Gli autori introducono F-Transformer, un’architettura transformer progettata fin dall’inizio per questo mondo distribuito e attento alla privacy. Invece di comprimere un modello gigante esistente, scelgono impostazioni snelle: solo 4 teste di attenzione, 4 layer e rappresentazioni delle parole a 64 dimensioni, per un totale di circa 0,87 milioni di parametri addestrabili. Descrivono un quadro a tre livelli: un livello dati che gestisce il testo locale e la tokenizzazione, un livello di intelligenza artificiale che esegue il transformer compatto e la procedura di federated averaging, e un livello applicativo che può supportare usi come generazione di testo, traduzione e risposta a domande tra molte organizzazioni. Presentano anche un obiettivo matematico che, almeno in teoria, fonde accuratezza e privacy in un unico fine di addestramento scoraggiando aggiornamenti che rivelino troppo su singoli record.
Prestazioni con meno potenza e memoria
Per testare F-Transformer, gli autori usano la nota collezione WikiText-2 di articoli di Wikipedia, concentrandosi su quanto bene il modello prevede la parola successiva in una sequenza. Valutano non solo la qualità delle previsioni ma anche il carico del processore e l’uso della memoria, confrontando l’addestramento centralizzato con la loro configurazione federata. Nonostante le dimensioni minuscole, F-Transformer ottiene una perplexity di validazione — una misura standard di quanto bene un modello anticipa il testo — che supera diversi modelli ben noti e molto più grandi, inclusi BERT-Large e varianti di GPT-2, quando i numeri sono normalizzati sulla stessa scala. Allo stesso tempo, la versione federata riduce l’utilizzo del processore di circa il 40 percento e il consumo di memoria di circa il 34 percento rispetto a un baseline centralizzato comparabile. La piccola dimensione del modello riduce anche drasticamente i costi di comunicazione: spostare gli aggiornamenti del modello tra client e server è oltre cento volte più economico che con GPT-2 small.
Cosa significa questo per l’uso quotidiano dell’IA
In termini semplici, lo studio dimostra che è possibile costruire modelli linguistici che apprendono da molte fonti di dati sparse, mantengono il testo grezzo privato e funzionano su hardware modesto — senza rinunciare alle prestazioni. F-Transformer dimostra che un transformer compatto e progettato con cura può competere con sistemi molto più grandi o superarli, pur essendo più semplice da distribuire su telefoni, dispositivi edge o reti istituzionali sensibili. Sebbene le garanzie di privacy presentate siano principalmente di natura architetturale più che formalmente misurate, e siano necessari test reali su dati più vari, i risultati indicano un futuro in cui la generazione di linguaggio di alta qualità non richiede infrastrutture IA massive, centralizzate e potenzialmente intrusive.
Citazione: Patel, N., Brahmbhatt, S., Ramoliya, F. et al. F-Transformer: a federated transformer for efficient and privacy-preserving sequence generation. Sci Rep 16, 14093 (2026). https://doi.org/10.1038/s41598-026-40881-0
Parole chiave: apprendimento federato, modello linguistico transformer, IA che preserva la privacy, PNL leggera, generazione di sequenze