Clear Sky Science · sv
F-Transformer: en federerad transformer för effektiv och integritetsbevarande sekvensgenerering
Varför mindre, säkrare språkverktyg spelar roll
Varje gång du skriver ett meddelande, söker på webben eller dikterar till din telefon försöker mjukvara tyst förutsäga och generera naturligt klingande språk. Dagens mest kraftfulla språkmodeller är dock enorma, kräver mycket beräkningskraft och kräver ofta att känslig text skickas till centrala servrar. Denna artikel presenterar ett nytt sätt att bygga språkmodeller som både är tillräckligt lätta för modest hårdvara och respekterar användarnas integritet, samtidigt som de matchar eller överträffar prestandan hos några av dagens mest omskrivna system.
Från jättemodeller till slimmade maskiner
Moderna språkverktyg bygger vanligtvis på transformers, en familj av neurala nätverk som är duktiga på att hantera långa meningar och subtila ordrelationer. Kända system som GPT-2 och BERT förlitar sig på hundratals miljoner till miljarder interna parametrar, vilket gör dem kraftfulla men också svåra att köra på vardagliga enheter. De tränas ofta i centraliserade datacenter som måste samla stora mängder text, vilket väcker frågor om integritet och äganderätt till data. Författarna hävdar att många verkliga användningsområden, från sjukhus till mobiltelefoner, behöver språkmodeller som är mycket mindre, mindre krävande och kapabla att lära sig utan att flytta allt råmaterial till ett och samma ställe.
Lära tillsammans utan att dela hemligheter
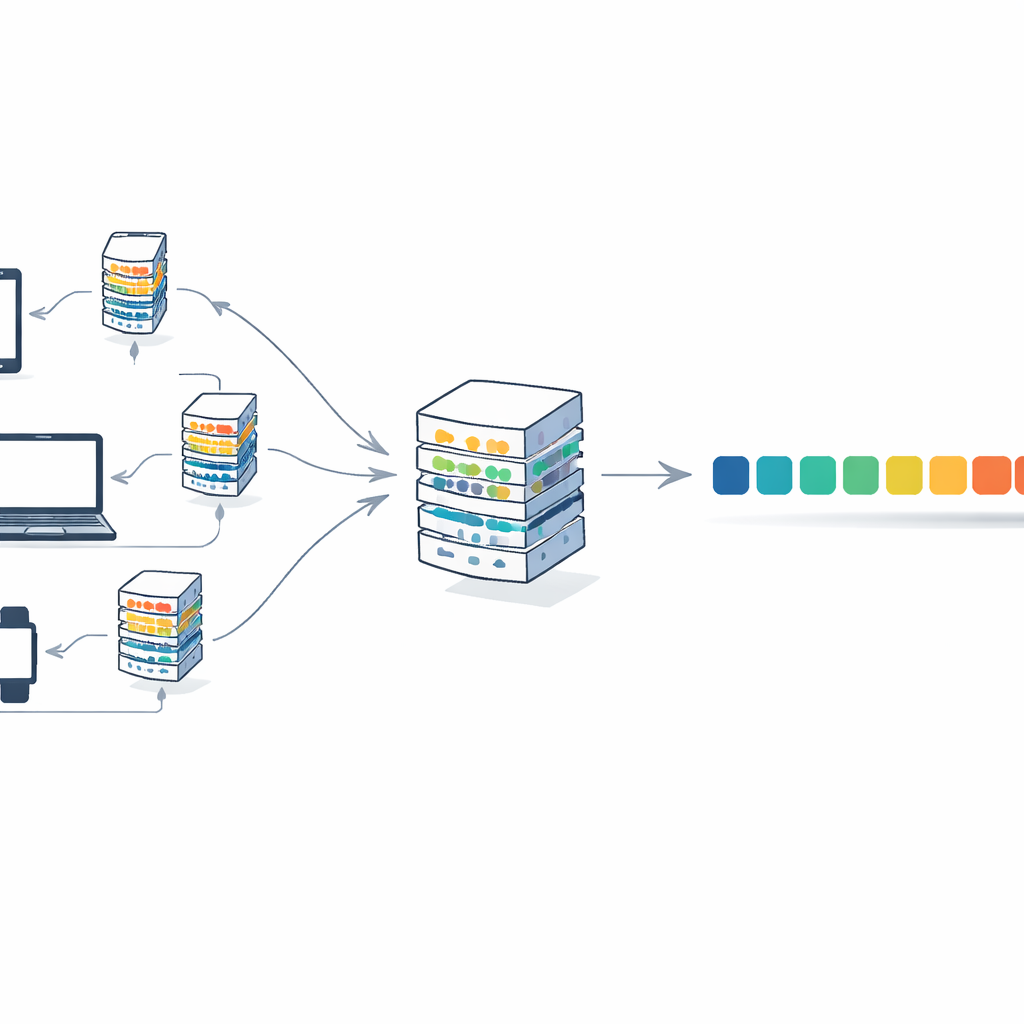
För att lösa detta kombinerar artikeln transformers med en träningsstrategi kallad federated learning. I detta upplägg behåller många klienter — såsom institutioner eller enheter — sin text lokalt. Varje klient tränar sin egen kopia av modellen på sin privata data och skickar endast de uppdaterade modellvikterna, inte själva texten, till en central server. Servern beräknar ett genomsnitt av dessa uppdateringar till en enda global modell och skickar tillbaka den. Över många rundor förbättras modellen genom att samla kunskap från olika källor, samtidigt som inga rådokument lämnar sina ursprungliga platser. Detta minskar integritetsrisker och fördelar även beräkningsbördan över klienterna istället för att förlita sig på en stor maskin.
En kompakt design byggd för delning
Författarna presenterar F-Transformer, en transformerarkitektur utformad från grunden för denna distribuerade, integritetsmedvetna miljö. Istället för att krympa en befintlig jättemodell väljer de slanka inställningar: bara 4 attention-heads, 4 lager och 64-dimensionella ordrepresentationer, för totalt omkring 0,87 miljoner träningsbara parametrar. De beskriver en tredelad ram: ett datalager som hanterar lokal text och tokenisering, ett AI-lager som kör den kompakta transformern och federated averaging-proceduren, och ett applikationslager som kan stödja användningar som textgenerering, översättning och frågor och svar över många organisationer. De presenterar också ett matematiskt mål som, åtminstone i teorin, förenar noggrannhet och integritet i ett enda träningsmål genom att avskräcka uppdateringar som avslöjar för mycket om enskilda poster.
Prestanda med mindre kraft och minne
För att testa F-Transformer använder författarna den välstuderade WikiText-2-samlingen av Wikipedia-artiklar och fokuserar på hur väl modellen förutspår nästa ord i en sekvens. De utvärderar inte bara förutsägelsekvalitet utan också processorbelastning och minnesanvändning, och jämför centraliserad träning med deras federerade upplägg. Trots sin lilla storlek uppnår F-Transformer en valideringsperplexity — ett standardmått på hur väl en modell förutser text — som slår flera välkända, mycket större modeller, inklusive BERT-Large och varianter av GPT-2, när siffrorna normaliseras till samma skala. Samtidigt minskar den federerade versionen processoranvändningen med cirka 40 procent och minnesförbrukningen med cirka 34 procent jämfört med en jämförbar centraliserad referens. Den lilla modellstorleken minskar också kommunikationskostnaderna kraftigt: att flytta modeluppdateringar mellan klienter och server är över hundra gånger billigare än med GPT-2 small.
Vad detta betyder för vardaglig användning av AI
Enkelt uttryckt visar studien att det är möjligt att bygga språkmodeller som lär sig från många spridda datakällor, håller rå text privat och körs på modest hårdvara — utan att ge upp prestanda. F-Transformer visar att en väl utformad, kompakt transformer kan konkurrera med eller överträffa mycket större system samtidigt som den är enklare att distribuera på telefoner, edge-enheter eller känsliga institutionella nätverk. Även om artikelns integritetsgarantier främst är arkitektoniska snarare än formellt mätta, och verklighetstester på mer varierad data fortfarande återstår, pekar resultaten mot en framtid där högkvalitativ språkgenerering inte kräver massiv, centraliserad och potentiellt integritetskränkande AI-infrastruktur.
Citering: Patel, N., Brahmbhatt, S., Ramoliya, F. et al. F-Transformer: a federated transformer for efficient and privacy-preserving sequence generation. Sci Rep 16, 14093 (2026). https://doi.org/10.1038/s41598-026-40881-0
Nyckelord: federated learning, transformer language model, privacy-preserving AI, lightweight NLP, sequence generation