Clear Sky Science · tr
Dongba tek-harf veri setinin oluşturulması için yeni bir çapraz-modallik hizalama öğrenme çerçevesi
Yazının Yaşayan Bir Fosilini Kurtarmak
Çin’in Naxi halkının Dongba yazısı sıklıkla yazının “yaşayan bir fosili” olarak anılır: dinsel el yazmalarında hâlâ kullanılan son piktografik sistemlerden biridir. Ancak bunu okuyabilen sadece az sayıda yaşlı ritüel uzmanı vardır ve hayatta kalan metinlerin çoğu kırılgan el yazması sayfalar halinde bulunmaktadır. Bu çalışma, bu yaşlanan el yazmalarını zengin, aranabilir tek-harfli veri tabanlarına dönüştürmek için yapay zekâ destekli yeni bir yöntem sunar; böylece insanlık tarihine açılan benzersiz bir pencereyi korumaya yardımcı olur.
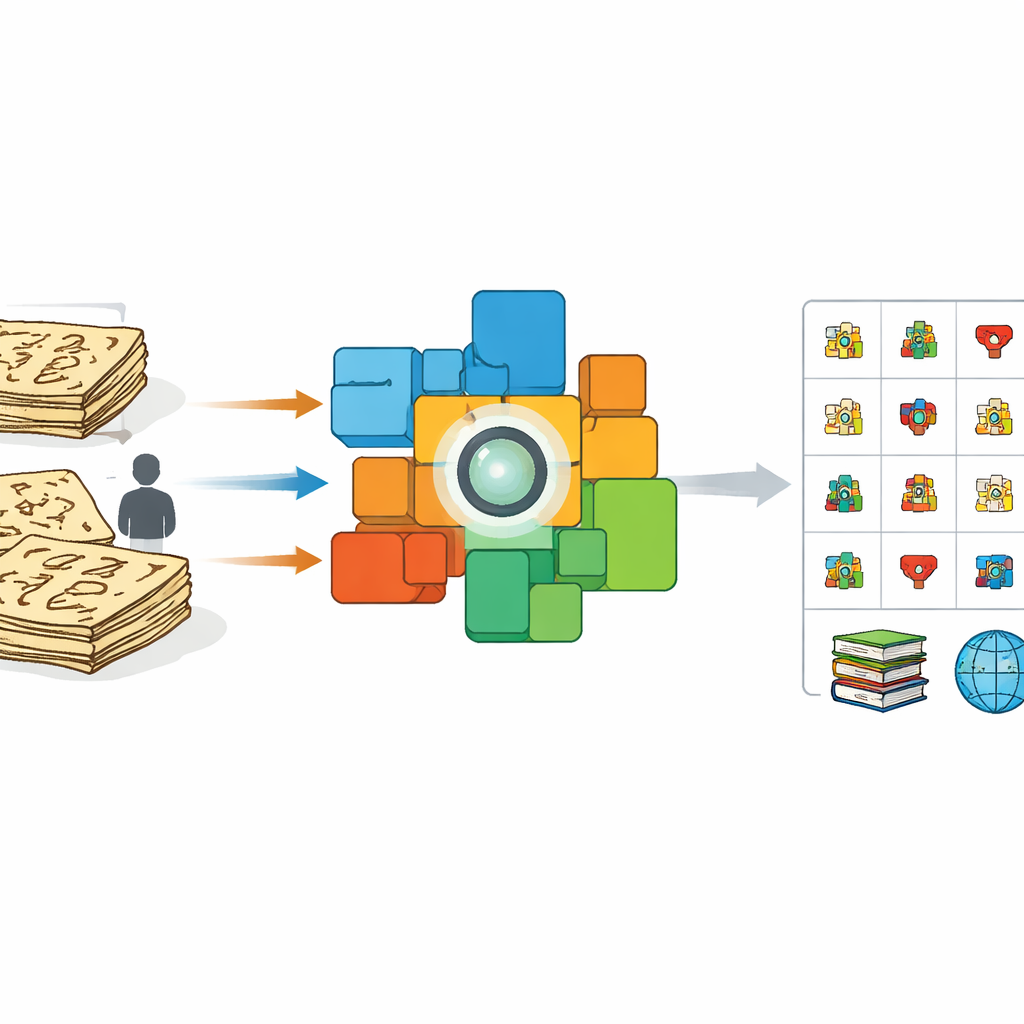
Neden Antik Resimler Bilgisayarlar İçin Zordur
İlk bakışta bir bilgisayara Dongba okumayı öğretmek, diğer el yazılarını öğretmek gibi görünebilir. Ancak geçmiş girişimler çoğunlukla gönüllülerin modern kalem veya kalemle karakterleri kopyalaması ve bu temiz görüntülerin otomatik olarak "uzatılması" veya şekillendirilmesine dayanıyordu. Bu özenli taklitler, yüzyıllık kitaplardaki gerçek fırça yazısı veya oyma karakterlerden çok farklı görünür. Mürekkep yoğunluğu değişir, çizgiler kopar veya birleşir, yazarlar şekillerde serbestlik gösterir. Sonuç olarak, yapay örneklerle eğitilen sistemler gerçek el yazmalarında, özellikle nadir veya önce belgelenmemiş sembollerle karşılaştıklarında kötü performans gösterir. Aynı zamanda binlerce karakteri elle etiketleyebilecek uzman sayısı çok azdır ve bu da koruma için bir darboğaz oluşturur.
Görüntülerin ve Anlamların Birlikte Öğrenmesine İzin Vermek
Yazarlar farklı bir yaklaşım benimsiyor: uzmanlardan her karakteri tek tek etiketlemelerini istemek yerine, zaten satır satır Çince çevirileriyle birlikte gelen tam sayfaları kullanıyorlar. 100 ciltlik bir Dongba metinleri akademik baskısından cümle görüntüleri tarayıp her birini uygun modern açıklamasıyla eşliyorlar. Ardından CLIP olarak bilinen güçlü bir görsel-dil modelini, Dongba cümlelerinin görüntülerinin paylaşılan matematiksel bir uzayda çevirilerine yakınlaşmasını ve alakasız metinden uzaklaşmasını sağlayacak şekilde ince ayar yapıyorlar. Bu çapraz-modallik eğitimi, görüntü kodlayıcısını anlam taşıyan görsel ayrıntılara odaklanmaya ve fırça darbelerindeki veya düzenindeki dağınık varyasyonları görmezden gelmeye yönlendiriyor.
Tüm Sayfalardan Bireysel İşaretlere
Model tüm cümlelerin açıklamalarıyla nasıl ilişkili olduğunu öğrendikten sonra ekip bireysel karakterlere yöneliyor. El yazmalarından düzensiz, zamanın aşındırdığı görünümü koruyarak on binlerce tek sembol doğrudan kırpıyorlar. Paralel olarak, her biri kısa bir Çince tanım ile ilişkilendirilmiş uzman kitaplardan alınmış karakter görüntülerinden oluşan bir referans “sözlük” oluşturuyorlar. Eğitilmiş görüntü kodlayıcısını kullanarak, kırpılmış her elyazması karakterini bu sözlükle karşılaştırıyorlar. Bir elyazması görüntüsü sözlükteki bir görüntüyle son derece benzerse, o bilinen kategoriye atanıyor. Aksi halde sistem bunu olası yeni bir varyant olarak ele alıyor, özelliğini referans örnekler havuzuna ekliyor ve uzman kontrolü için işaretliyor. Bu dinamik “çapa genişletme” tanınan formların kapsamını kademeli olarak genişletir ve mevcut sözlüklerde eksik olan karakterleri bile ortaya çıkarır.
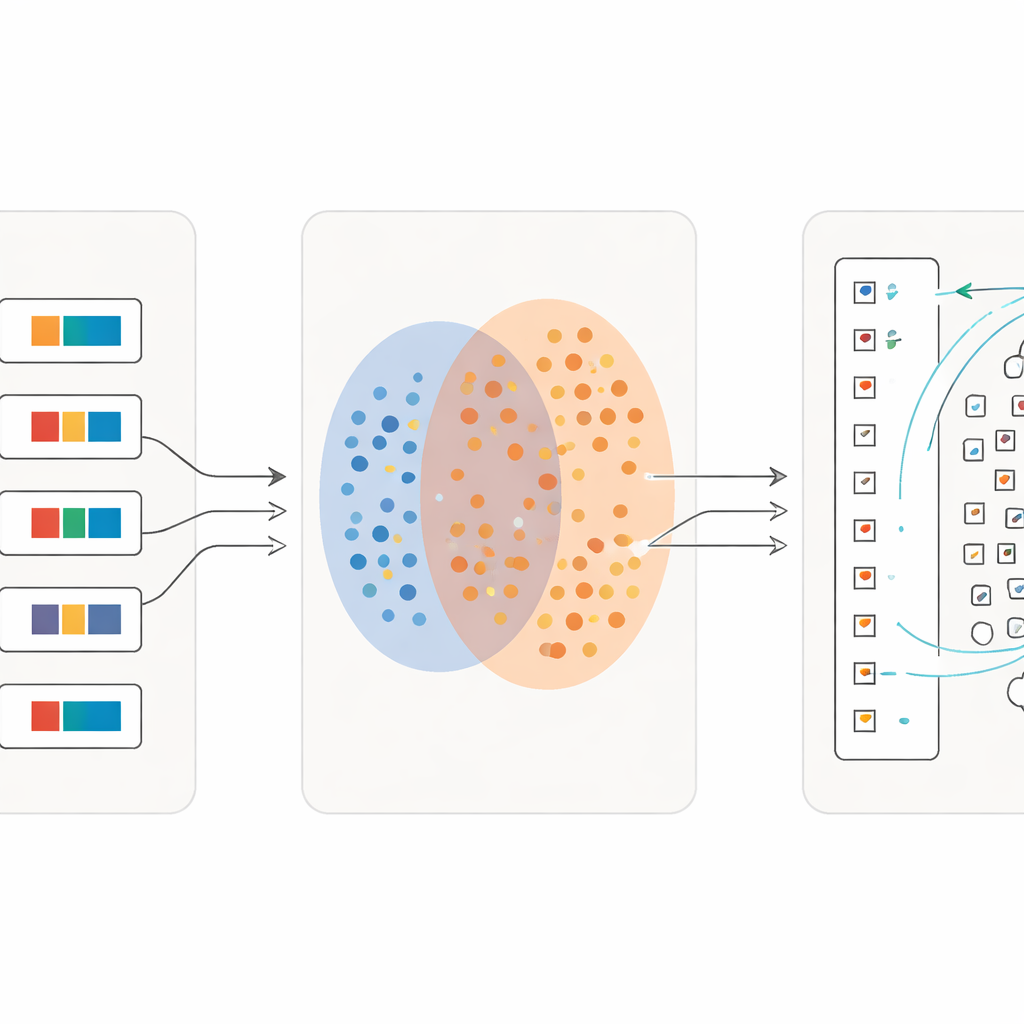
Daha İnce Ayrıntılarda Öğrenme
Anahtar yenilik süreç bir geçişle bitmiyor olmasıdır. İlk dalga karakterler güvenilir şekilde eşleştirildikten sonra araştırmacılar bu eşleşmeleri yeni eğitim materyaline dönüştürüyor: her bir tek sembol için sözlük anlamını kullanarak kısa bir betimleyici ifade oluşturuyorlar. Ardından modeli tam cümleler ile bu ince taneli karakter tanımları karışımı üzerinde yeniden eğitiyorlar. Her yinelemede sistem, görsel olarak benzer işaretler arasındaki ince farklara daha duyarlı hale gelirken, gevşek yazı stiline karşı da dayanıklı kalıyor. Birkaç tur boyunca sınıflandırma doğruluğu, doğru şekilde geri çağrılan karakterlerin biraz üzerinden başlayıp, birkaç örneği olan birçok nadir sembol için bile yüzde 97’nin üzerine çıkıyor.
Gelecek İçin Yeni Bir Dijital Arşiv
Sonuç olarak ekip, tümü özgün tarihsel el yazmalarından alınmış 1.512 kategoride gruplanmış 705.058 tek-harfli görüntüden oluşan büyük ölçekli Dongba_1512 veri setini üretiyor. Koleksiyon güncel referans eserlerde yer almayan 252 karakter içeriyor ve dilbilimciler ile tarihçiler için yeni malzeme sunuyor. Bu veri setiyle eğitilen modern görüntü tanıma sistemleri yüksek doğruluk elde ederken, yalnızca yapay el yazısı ile eğitilen modeller gerçek sayfalarla karşılaştığında ciddi şekilde başarısız oluyor. Çalışma gösteriyor ki görüntüler ve anlamlar birbirini yönlendirdiğinde, yapay zekâ geniş anotasyonlardan yoksun tehlike altındaki yazıları kurtarmaya yardımcı olabilir ve aynı strateji Shui ve Yi gibi diğer piktografik geleneklere de uyarlanabilir. Nihayetinde bu çalışma kırılgan ritüel kitapları kültürel miras ve bilimsel keşif için sağlam bir dijital kaynağa dönüştürüyor.
Atıf: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Anahtar kelimeler: Dongba yazısı, antik yazı, dijital koruma, görsel-dil modelleri, karakter tanıma