Clear Sky Science · pl
Nowa ramowa metoda uczenia wyrównania między modalnościami do tworzenia bazy pojedynczych znaków pisma Dongba
Ratowanie żywego skamieniałości pisma
Pismo Dongba ludu Naxi w Chinach bywa nazywane „żywą skamieniałością” pisma: jest jednym z nielicznych systemów piktograficznych nadal używanych w manuskryptach rytualnych. Jednak tylko nieliczni, głównie starsi specjaliści rytualni, potrafią je czytać, a większość zachowanych tekstów istnieje wyłącznie jako kruche, rękopiśmienne kartki. W tym badaniu przedstawiono nowe, oparte na sztucznej inteligencji podejście, które pozwala przekształcić te starzejące się manuskrypty w bogatą, przeszukiwalną bazę pojedynczych znaków, pomagając zachować wyjątkowe okno na historię ludzkości.
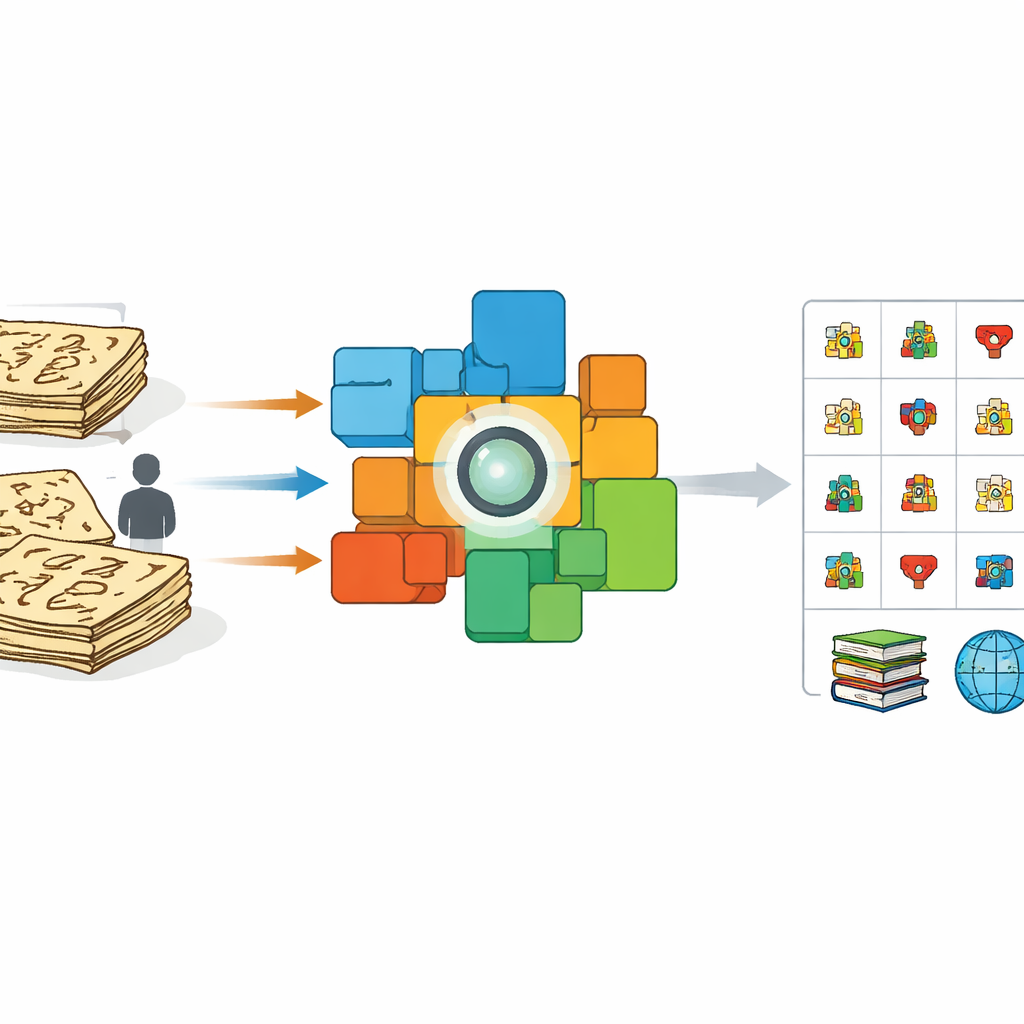
Dlaczego stare obrazy są trudne dla komputerów
Pierwsze spojrzenie może sugerować, że nauczenie komputera czytania Dongba to jak nauczenie go odręcznego pisma. Jednak wcześniejsze próby opierały się głównie na ochotnikach przepisujących znaki współczesnymi długopisami lub stylusami oraz na automatycznym „rozciąganiu” i zniekształcaniu tych czystych obrazów. Te starannie wykonane imitacje wyglądają bardzo inaczej niż prawdziwe pociągnięcia pędzla czy znaki wyryte w wiekowych księgach. Gęstość tuszu się zmienia, kreski pękają i łączą się, a piszący improwizują kształty. W rezultacie systemy wytrenowane na sztucznych próbkach słabo radzą sobie z prawdziwymi manuskryptami, zwłaszcza gdy napotykają rzadkie lub wcześniej nieudokumentowane symbole. Jednocześnie jest bardzo niewielu specjalistów zdolnych ręcznie oznakować tysiące znaków, co tworzy wąskie gardło dla prac konserwatorskich.
Pozwalając obrazom i znaczeniom uczyć się razem
Autorzy przyjmują inne podejście: zamiast prosić ekspertów o etykietowanie każdego znaku z osobna, wykorzystują całe strony, które już zawierają linia po linii chińskie tłumaczenia. Z 100‑tomowego wydania naukowego tekstów Dongba skanują obrazy zdań i parują każde z jego odpowiadającym współczesnym wyjaśnieniem. Następnie dopracowują potężny model wizja‑język znany jako CLIP, tak aby w wspólnej przestrzeni matematycznej obrazy zdań Dongba były zbliżane do ich tłumaczeń i odsuwane od niezwiązanych tekstów. To trening międzymodalny skłania enkoder obrazu do koncentrowania się na detalach wizualnych niosących znaczenie i ignorowania nieporządnych wariacji pociągnięć pędzla czy układu strony.
Od całych stron do pojedynczych znaków
Gdy model nauczy się relacji między całymi zdaniami a ich wyjaśnieniami, zespół przechodzi do pojedynczych znaków. Wycinają dziesiątki tysięcy pojedynczych symboli bezpośrednio z manuskryptów, zachowując ich nieregularny, zużyty wygląd. Równolegle tworzą referencyjny „słownik” obrazów znaków zaczerpnięty z książek specjalistycznych, z każdym obrazem powiązanym z krótką chińską definicją. Korzystając z wytrenowanego enkodera obrazu, porównują każdy wycięty znak z manuskryptu z tym słownikiem. Jeśli obraz manuskryptu jest bardzo podobny do obrazu ze słownika, przypisują go do tej znanej kategorii. Jeśli nie, system traktuje go jako możliwą nową wariację, dodaje jego cechę do zbioru przykładów referencyjnych i oznacza do sprawdzenia przez eksperta. Ta dynamiczna „ekspansja kotwic” stopniowo poszerza zakres rozpoznawalnych form, a nawet odkrywa znaki brakujące w istniejących słownikach.
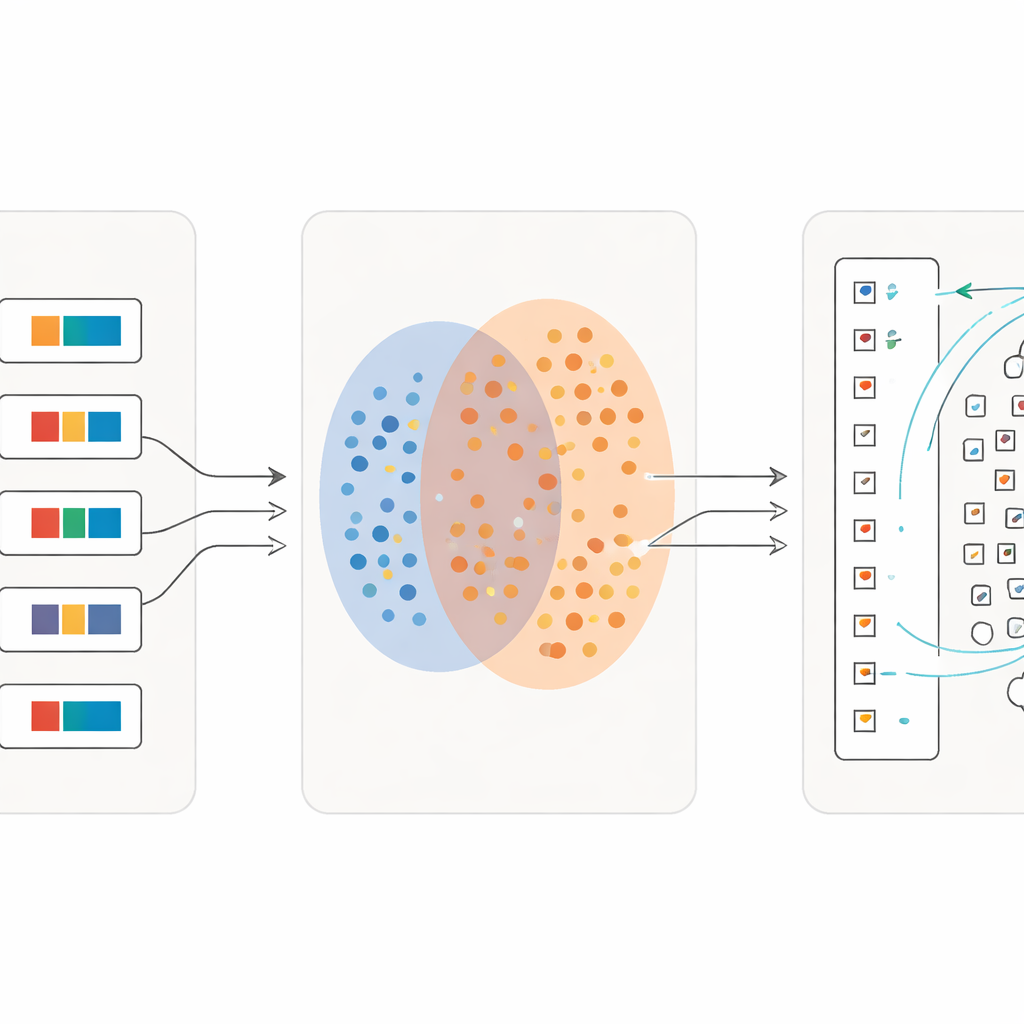
Nauka w coraz większych szczegółach
Kluczową innowacją jest to, że proces nie kończy się po jednym przejściu. Gdy pierwsza fala znaków zostanie niezawodnie dopasowana, badacze przekształcają te dopasowania w nowy materiał treningowy: dla każdego pojedynczego symbolu tworzą krótką opisową frazę wykorzystującą jego słownikowe znaczenie. Następnie ponownie trenują model na mieszance pełnych zdań i tych drobniejszych opisów znaków. Z każdą iteracją system staje się bardziej czuły na subtelne różnice między wizualnie podobnymi znakami, pozostając jednocześnie odpornym na niechlujne pismo. W ciągu kilku rund dokładność klasyfikacji wzrasta z nieco ponad połowy poprawnie rozpoznanych znaków do ponad 97 procent, nawet dla wielu rzadkich symboli mających zaledwie kilka przykładów.
Nowe archiwum cyfrowe na przyszłość
Ostatecznie zespół tworzy Dongba_1512, duży zbiór danych zawierający 705 058 pojedynczych obrazów znaków pogrupowanych w 1 512 kategorii, wszystkie pochodzące z autentycznych historycznych manuskryptów. Kolekcja zawiera 252 znaki, które nie występują w aktualnych materiałach referencyjnych, dostarczając nowego materiału dla językoznawców i historyków. Nowoczesne systemy rozpoznawania obrazów wytrenowane na tym zbiorze osiągają wysoką dokładność, podczas gdy modele uczone wyłącznie na sztucznym odręcznym piśmie zawodzą, gdy stają w obliczu prawdziwych stron. Badanie pokazuje, że pozwalając obrazom i znaczeniom wzajemnie się prowadzić, AI może pomóc uratować zagrożone systemy pisma pozbawione obszernego oznakowania, a tę samą strategię można zaadaptować do innych tradycji piktograficznych, takich jak Shui i Yi. Ostatecznie praca ta przekształca kruche księgi rytualne w solidne zasoby cyfrowe dla dziedzictwa kulturowego i badań naukowych.
Cytowanie: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Słowa kluczowe: pismo Dongba, starożytne pismo, cyfrowa konserwacja, modele wizja‑język, rozpoznawanie znaków