Clear Sky Science · es
Un nuevo marco de aprendizaje de alineación cruzada multimodal para la construcción de un conjunto de datos de caracteres individuales Dongba
Salvando un fósil viviente de la escritura
La escritura Dongba del pueblo Naxi de China suele llamarse un “fósil viviente” de la escritura: es uno de los últimos sistemas pictográficos aún usados en manuscritos religiosos. Sin embargo, solo un reducido número de ancianos especialistas rituales la puede leer, y la mayoría de los textos supervivientes existen únicamente como frágiles páginas manuscritas. Este estudio presenta un nuevo método impulsado por inteligencia artificial para convertir esos manuscritos envejecidos en una base de datos buscable y rica de caracteres individuales, contribuyendo a preservar una ventana única a la historia humana.
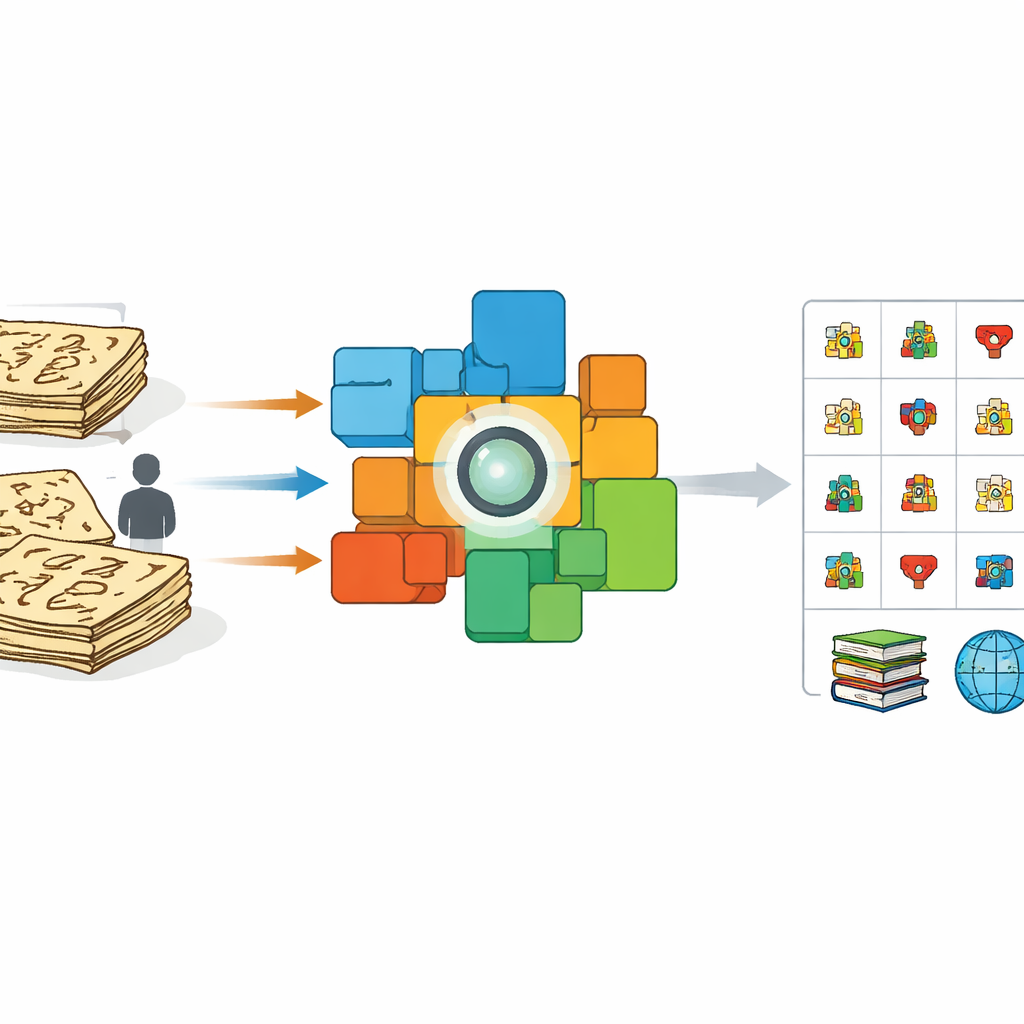
Por qué las imágenes antiguas son difíciles para los ordenadores
A primera vista, enseñar a un ordenador a leer Dongba podría parecer similar a enseñarle a leer cualquier otra escritura manuscrita. Pero los intentos previos se basaron mayormente en voluntarios que copiaban caracteres con bolígrafos o lápices modernos y en el “estirado” o deformación automática de esas imágenes limpias. Estas imitaciones ordenadas se ven muy diferentes de los caracteres reales escritos con pincel o tallados en libros de siglos de antigüedad. La densidad de la tinta varía, los trazos se rompen y se fusionan, y los escribas improvisan formas. Como resultado, los sistemas entrenados con muestras artificiales funcionan mal con manuscritos reales, especialmente frente a símbolos raros o no documentados anteriormente. Al mismo tiempo, hay muy pocos especialistas capaces de etiquetar miles de caracteres a mano, lo que crea un cuello de botella para la preservación.
Poner a las imágenes y a los significados a aprender juntos
Los autores adoptan un enfoque distinto: en lugar de pedir a los expertos que etiqueten cada carácter uno por uno, aprovechan páginas completas que ya vienen con traducciones al chino línea por línea. A partir de una edición académica de 100 volúmenes de textos Dongba, escanean imágenes de oraciones y las emparejan con su explicación moderna correspondiente. Luego afinan un potente modelo visón‑lenguaje conocido como CLIP para que, en un espacio matemático compartido, las imágenes de oraciones Dongba se acerquen a sus traducciones y se alejen de textos no relacionados. Este entrenamiento cruzado multimodal empuja al codificador de imágenes a centrarse en los detalles visuales que transmiten significado y a ignorar las variaciones desordenadas en los trazos o la disposición.
De páginas enteras a signos individuales
Una vez que el modelo ha aprendido cómo se relacionan oraciones completas con sus explicaciones, el equipo pasa a los caracteres individuales. Recortan decenas de miles de símbolos únicos directamente de los manuscritos, preservando su apariencia irregular y envejecida. En paralelo, construyen un “diccionario” de referencia con imágenes de caracteres tomadas de libros especializados, cada una vinculada a una breve definición en chino. Usando el codificador de imágenes entrenado, comparan cada carácter recortado del manuscrito con este diccionario. Si una imagen del manuscrito es extremadamente similar a una imagen del diccionario, se le asigna esa categoría conocida. Si no, el sistema la trata como una posible nueva variante, añade su representación de características al conjunto de ejemplos de referencia y la marca para revisión experta. Esta “expansión de anclas” dinámica amplia gradualmente el rango de formas reconocidas e incluso descubre caracteres ausentes en los diccionarios existentes.
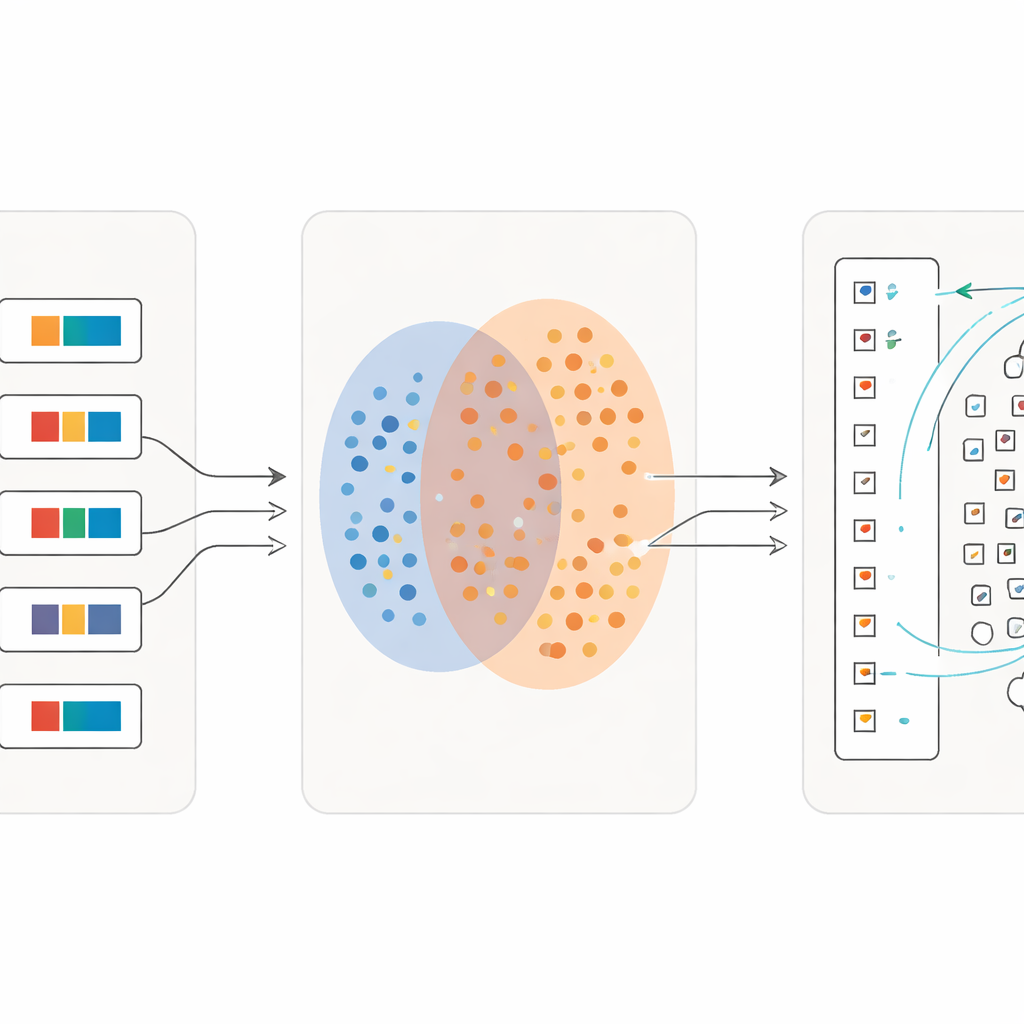
Aprendizaje en detalles cada vez más finos
Una innovación clave es que el proceso no se detiene tras una sola pasada. Una vez que una primera oleada de caracteres se ha emparejado de forma fiable, los investigadores convierten esas coincidencias en nuevo material de entrenamiento: para cada símbolo individual crean una breve frase descriptiva usando su significado del diccionario. Luego vuelven a entrenar el modelo con una mezcla de oraciones completas y estas descripciones de carácter de alta resolución. Con cada iteración, el sistema se vuelve más sensible a diferencias sutiles entre signos visualmente similares, manteniéndose al mismo tiempo robusto frente a escritura descuidada. A lo largo de varias rondas, la precisión de clasificación sube de algo más de la mitad de los caracteres recuperados correctamente a más del 97 por ciento, incluso para muchos símbolos raros con solo unos pocos ejemplos.
Un nuevo archivo digital para el futuro
Al final, el equipo produce Dongba_1512, un conjunto de datos a gran escala de 705.058 imágenes de caracteres individuales agrupadas en 1.512 categorías, todas extraídas de manuscritos históricos auténticos. La colección incluye 252 caracteres que no aparecen en las obras de referencia actuales, ofreciendo material novedoso para lingüistas e historiadores. Los sistemas modernos de reconocimiento de imagen entrenados con este conjunto alcanzan alta precisión, mientras que los modelos entrenados solo con escritura artificial fallan estrepitosamente ante páginas reales. El estudio muestra que al dejar que las imágenes y los significados se guíen mutuamente, la IA puede ayudar a rescatar escrituras en peligro que carecen de amplias anotaciones, y la misma estrategia puede adaptarse a otras tradiciones pictográficas como Shui y Yi. En última instancia, este trabajo convierte frágiles libros rituales en un recurso digital robusto para la herencia cultural y el descubrimiento académico.
Cita: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Palabras clave: escritura Dongba, escritura antigua, preservación digital, modelos visón‑lenguaje, reconocimiento de caracteres