Clear Sky Science · ru
Новая рамочная модель обучения кросс-модальному выравниванию для создания набора данных по одиночным иероглифам Дунба
Сохранение «живого ископаемого» письменности
Письмо Дунба народа наси в Китае часто называют «живым ископаемым» письменности: это одна из последних пиктографических систем, по-прежнему используемых в религиозных рукописях. Однако читать его умеют лишь немногие пожилые ритуальные специалисты, а большинство сохранившихся текстов представлены хрупкими рукописными листами. В этом исследовании предложен новый подход на основе искусственного интеллекта, который превращает стареющие рукописи в богатую, полнотекстовую базу данных отдельных знаков, помогая сохранить уникальное окно в историю человечества.
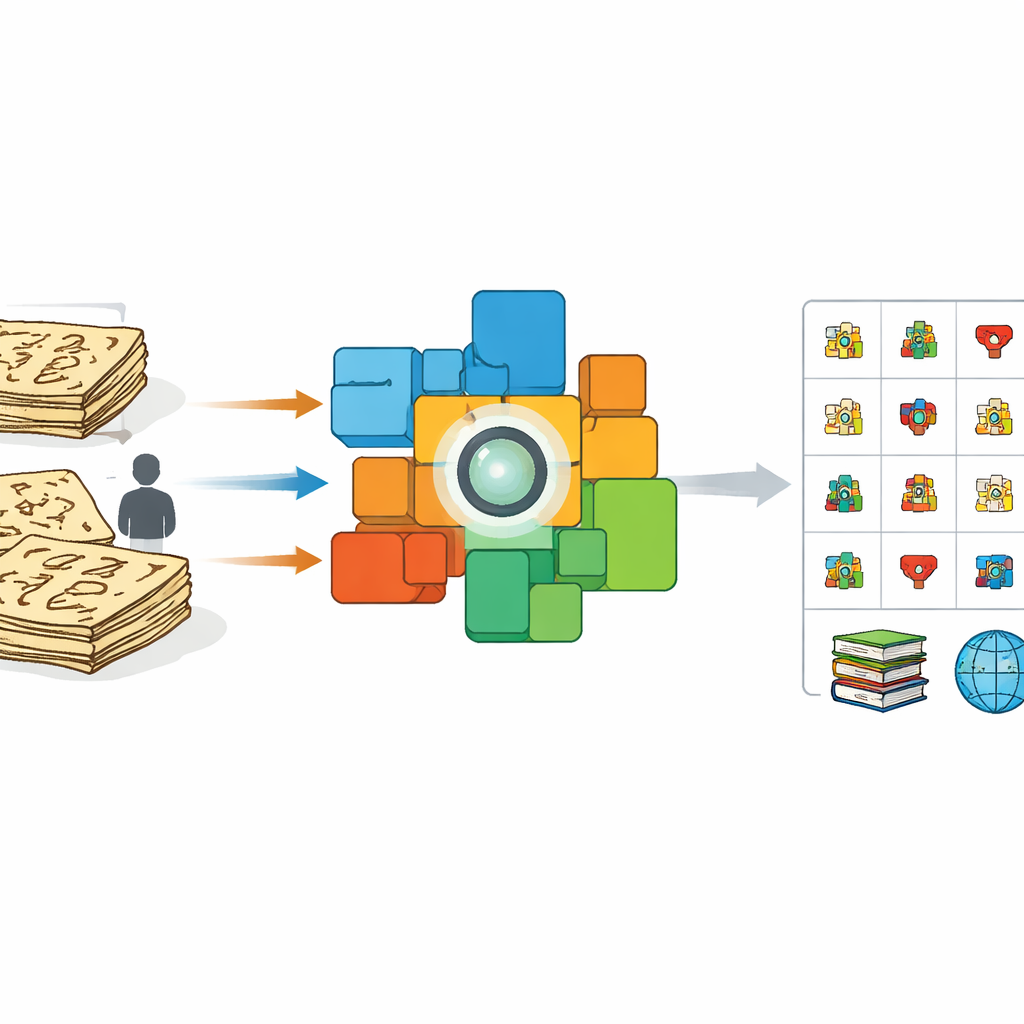
Почему древние рисунки сложны для компьютеров
На первый взгляд обучение компьютера чтению Дунба похоже на обучение распознаванию любого рукописного текста. Но прежние попытки в основном опирались на волонтёров, копировавших знаки современными ручками или стилусами, и на автоматическую «растяжку» и деформацию этих чистых изображений. Такие аккуратные имитации сильно отличаются от настоящих знаков, написанных кистью или высеченных в книгах вековой давности. Плотность чернил варьируется, штрихи прерываются и сливаются, а писцы импровизируют формы. В результате системы, обученные на искусственных образцах, слабо работают на подлинных рукописях, особенно при столкновении с редкими или ранее не задокументированными символами. Одновременно очень мало специалистов, способных вручную пометить тысячи символов, что создаёт узкое место в процессе сохранения.
Когда изображения и значения учатся вместе
Авторы используют другой подход: вместо того чтобы просить экспертов помечать каждый знак по отдельности, они используют целые страницы, которые уже снабжены построчными китайскими переводами. Из академического издания Дунба в 100 томах они сканируют изображения предложений и сопоставляют каждое с его современным пояснением. Затем они дообучают мощную визуально-языковую модель, известную как CLIP, так чтобы в общем математическом пространстве изображения предложений Дунба сближались со своими переводами и отдалялись от нерелевантного текста. Такое кросс-модальное обучение заставляет кодировщик изображений фокусироваться на визуальных деталях, несущих смысл, и игнорировать незначительные вариации в штрихах или разметке.
От целых страниц к отдельным знакам
Когда модель научилась соотносить целые предложения с их пояснениями, команда переходит к отдельным символам. Они вырезают десятки тысяч одиночных знаков прямо из рукописей, сохраняя их неровный, выдержанный временем вид. Параллельно они создают справочный «словарь» изображений знаков, взятых из специализированных книг, каждый из которых связан с кратким китайским определением. Используя обученный кодировщик изображений, они сравнивают каждое вырезанное изображение из рукописи со словарём. Если изображение из рукописи чрезвычайно похоже на словарное, ему присваивается соответствующая известная категория. Если нет, система рассматривает его как возможный новый вариант, добавляет его признаки в пул эталонных примеров и помечает для проверки экспертом. Эта динамическая «экспансия якорей» постепенно расширяет диапазон распознаваемых форм и даже выявляет знаки, отсутствующие в имеющихся словарях.
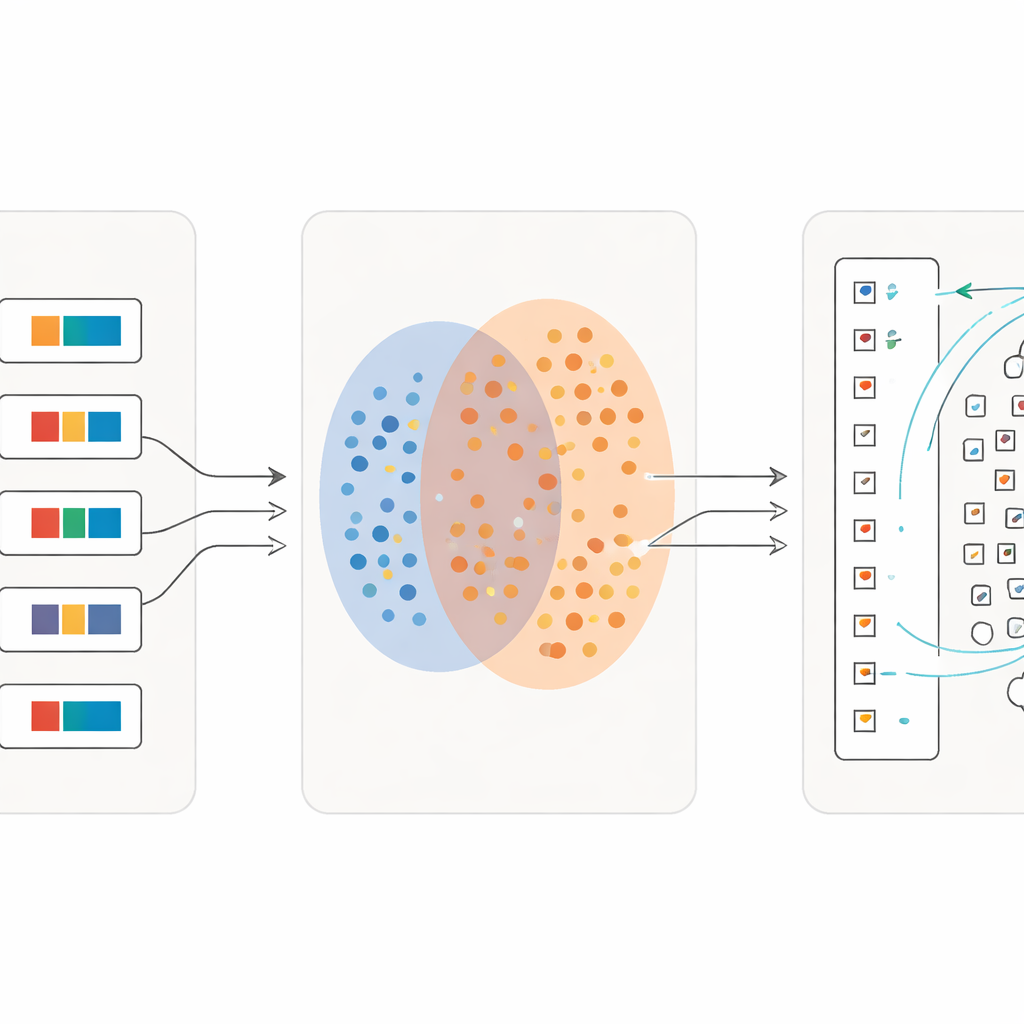
Обучение в всё более тонких деталях
Ключевая инновация в том, что процесс не останавливается после одного прохода. Как только первая волна знаков надёжно сопоставлена, исследователи превращают эти сопоставления в новый тренировочный материал: для каждого отдельного символа они создают короткую описательную фразу, используя его словарное значение. Затем они дообучают модель на смеси полных предложений и этих тонких описаний символов. С каждой итерацией система становится более чувствительной к тонким различиям между визуально похожими знаками, оставаясь при этом устойчивой к небрежному письму. В ходе нескольких раундов точность классификации возрастает с чуть более половины правильно восстановленных символов до более чем 97 процентов, даже для многих редких знаков, представленных всего несколькими примерами.
Новый цифровой архив для будущего
В результате команда создаёт Dongba_1512, крупномасштабный набор данных из 705 058 изображений одиночных символов, сгруппированных в 1 512 категорий, все извлечены из подлинных исторических рукописей. Коллекция включает 252 знака, которые не встречаются в современных справочниках, что даёт новый материал для лингвистов и историков. Современные системы распознавания изображений, обученные на этом наборе, показывают высокую точность, тогда как модели, обученные только на искусственной рукописи, сильно ошибаются при работе с реальными страницами. Исследование демонстрирует, что позволяя изображениям и значениям взаимно уточнять друг друга, ИИ может помочь спасти находящиеся под угрозой исчезновения системы письма, для которых нет обширных аннотаций, и ту же стратегию можно адаптировать к другим пиктографическим традициям, таким как шуй или и. В конечном счёте эта работа превращает хрупкие ритуальные книги в надёжный цифровой ресурс для культурного наследия и научных открытий.
Цитирование: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Ключевые слова: письмо Дунба, древнее письмо, цифровая сохранность, визуально-языковые модели, распознавание символов