Clear Sky Science · ar
إطار تعلم محاذاة عابر للأوضاع جديد لبناء مجموعة بيانات أحادية الحرف لدونغبا
إنقاذ أحفورة حية للكتابة
يُطلق على خط دونغبا لدى شعب ناكسي في الصين غالبًا اسم «أحفورة حية» للكتابة: فهو واحد من آخر الأنظمة التصويرية التي لا تزال تُستخدم في المخطوطات الدينية. ومع ذلك، فإن عدداً قليلاً فقط من المختصين الشعائريين المسنين قادرون على قراءته، ومعظم النصوص الباقية موجودة فقط في شكل صفحات مكتوبة بخط اليد وهشة. تقدم هذه الدراسة نهجًا جديدًا مدفوعًا بالذكاء الاصطناعي لتحويل تلك المخطوطات القديمة إلى قاعدة بيانات غنية قابلة للبحث عن الأحرف الفردية، مما يساعد على حفظ نافذة فريدة في التاريخ البشري.
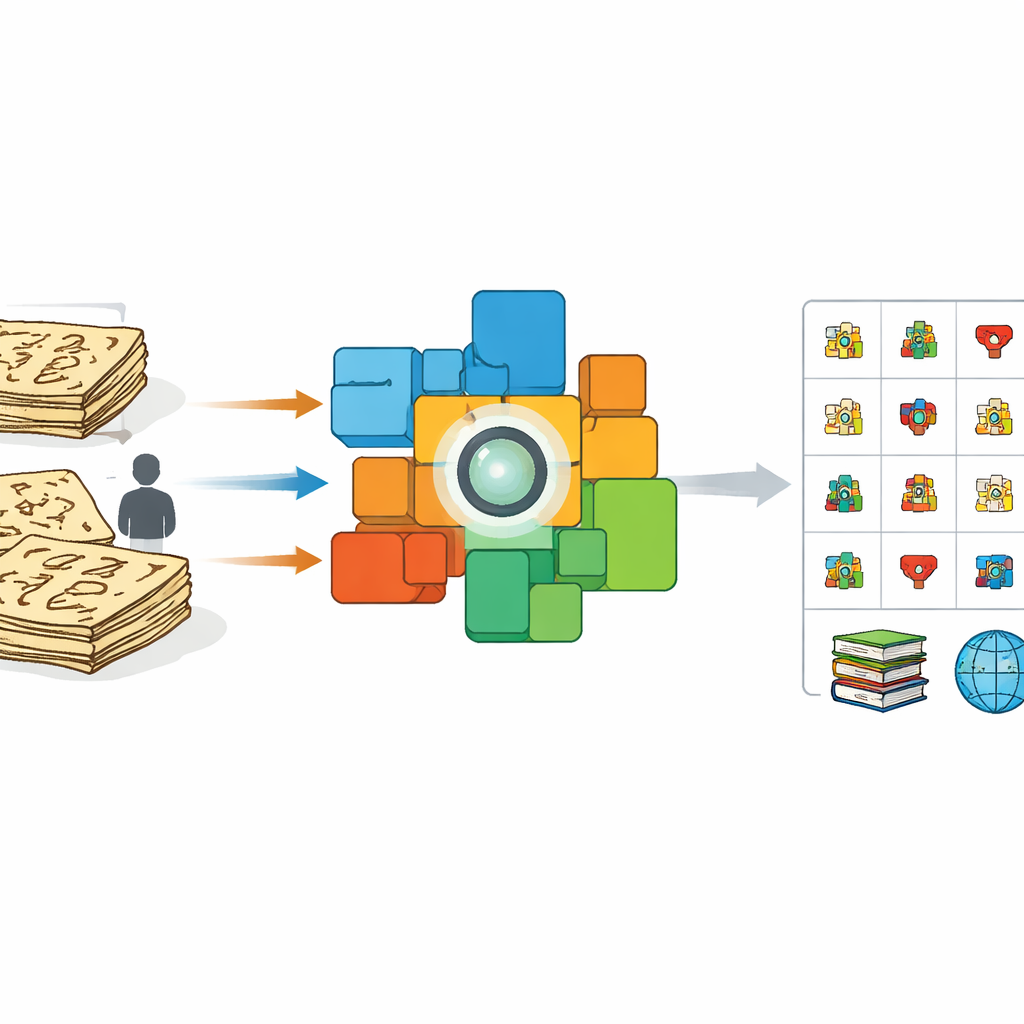
لماذا الصور القديمة صعبة على الحواسيب
قد يبدو تعليم الحاسوب لقراءة دونغبا شبيهًا بتعليمه قراءة أي خط يد آخر. لكن الجهود السابقة اعتمدت في الغالب على متطوعين ينسخون الحروف بأقلام أو أدوات حديثة وعلى عمليات «تمطيط» وتشويه تلقائية لتلك الصور النظيفة. تبدو هذه النسخ المرتبة مختلفة جدًا عن الحروف الحقيقية المكتوبة بالفرشاة أو المنحوتة في الكتب التي تعود لقرون. تتباين كثافة الحبر، وتنقطع الخطوط وتندمج، ويخترع الكتّاب أشكالًا بديلة. نتيجة لذلك، تعمل الأنظمة المدربة على عينات مصطنعة أداءً ضعيفًا على المخطوطات الحقيقية، لا سيما عندما تواجه رموزًا نادرة أو غير موثقة سابقًا. وفي الوقت نفسه، هناك قلة من المتخصصين القادرين على وسم آلاف الأحرف يدويًا، مما يشكل عنق زجاجة للحفظ.
جعل الصور والمعاني تتعلَّم معًا
يتبع المؤلفون نهجًا مختلفًا: بدلاً من مطالبة الخبراء بوضع وسم لكل حرف واحدًا تلو الآخر، يستفيدون من الصفحات الكاملة التي تحتوي بالفعل على ترجمات صينية سطرًا بسطر. من طبعة علمية مكونة من 100 مجلد لنصوص دونغبا، يقومون بمسح صور الجمل وربط كل منها بشرحها الحديث المطابق. ثم يقومون بضبط نموذج قوي للرؤية واللغة معروف باسم CLIP بحيث في فضاء رياضي مشترك، تُقرب صور جمل دونغبا من ترجماتها وتبتعد عن النصوص غير المرتبطة. هذا التدريب العابر للأوضاع يدفع مشفّر الصور للتركيز على التفاصيل البصرية الحاملة للمعنى وتجاهل التباينات العشوائية في ضربات الفرشاة أو توزيع الصفحات.
من الصفحات الكاملة إلى العلامات الفردية
بعد أن يتعلم النموذج كيف ترتبط الجمل الكاملة بشروحاتها، يتجه الفريق إلى الأحرف الفردية. يقومون بقص عشرات الآلاف من الرموز المنفردة مباشرة من المخطوطات، محافظين على مظهرها غير المنتظم والمتآكل بفعل الزمن. وبالتوازي، يبنون «قاموسًا» مرجعيًا لصور الحروف مأخوذًا من كتب متخصصة، كل واحد مربوط بتعريف صيني قصير. باستخدام مشفّر الصور المدرب، يقارنون كل حرف مقصوص من المخطوطات بهذا القاموس. إذا كانت صورة المخطوط مشابهة للغاية لصورة القاموس، تُنسب إلى تلك الفئة المعروفة. وإذا لم تكن كذلك، يعتبرها النظام متغيرًا جديدًا محتملاً، ويضيف ميزتها إلى مجموعة أمثلة المرجع ويعلم الخبراء لمراجعتها. هذا «توسيع للأراشيف» الديناميكي يوسع تدريجيًا نطاق الأشكال المعترف بها ويكشف حتى عن حروف مفقودة من القواميس الحالية.
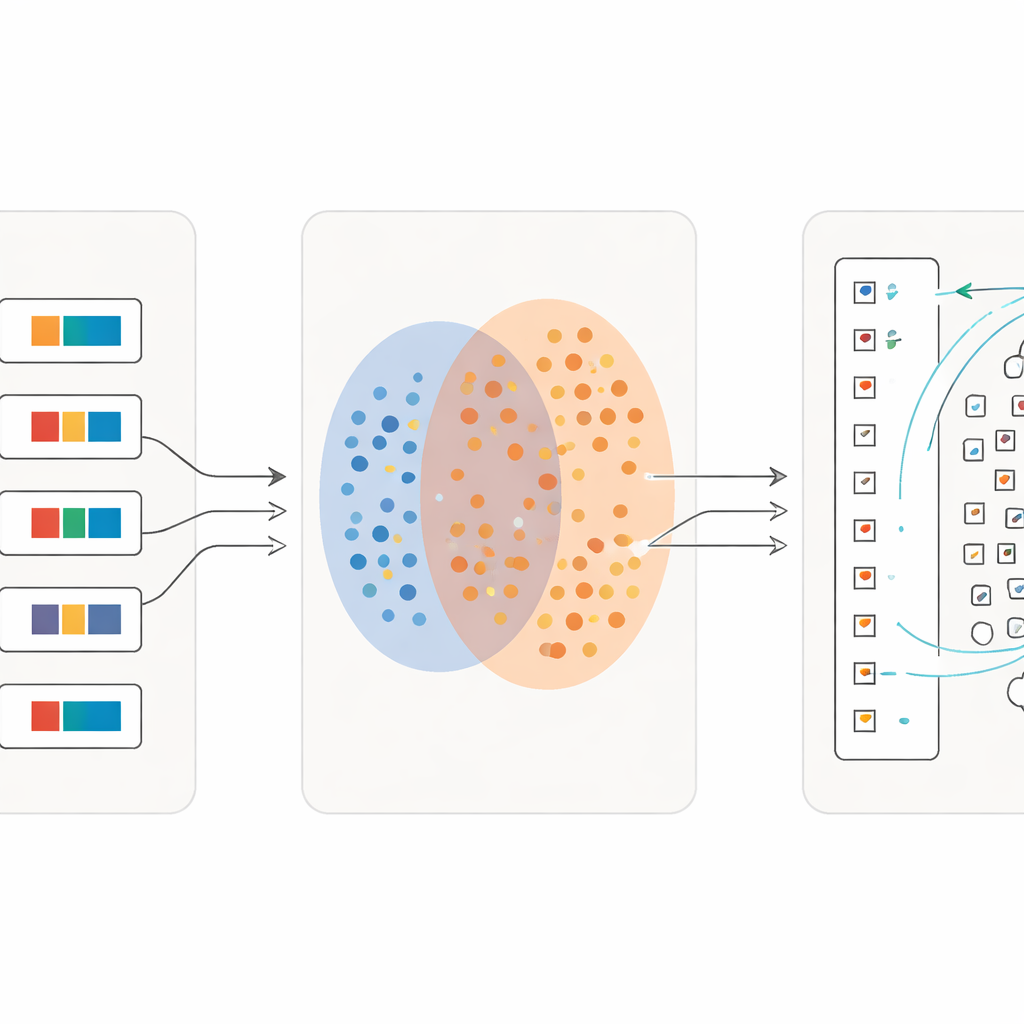
التعلّم بتفاصيل أدق فالأدق
ابتكار رئيسي هو أن العملية لا تتوقف بعد مرور واحد. بعد موجة أولى من الأحرف تم مطابقتها بثقة، يحول الباحثون هذه المطابقات إلى مادة تدريب جديدة: لكل رمز منفرد، ينشئون عبارة وصفية قصيرة باستخدام معناه في القاموس. ثم يعيدون تدريب النموذج على مزيج من الجمل الكاملة وهذه الأوصاف الدقيقة للحروف. مع كل تكرار، يصبح النظام أكثر حساسية للفروق الطفيفة بين العلامات المتشابهة بصريًا بينما يظل قويًا تجاه الكتابة السائبة. على مدار عدة جولات، ترتفع دقة التصنيف من أكثر بقليل من نصف الحروف المسترجعة بشكل صحيح إلى أكثر من 97 بالمئة، حتى بالنسبة للعديد من الرموز النادرة التي لها عدد قليل فقط من الأمثلة.
أرشيف رقمي جديد للمستقبل
في النهاية، ينتج الفريق Dongba_1512، مجموعة بيانات ضخمة تضم 705,058 صورة لحرف واحد مجمعة في 1,512 فئة، كلها مأخوذة من مخطوطات تاريخية أصلية. تتضمن المجموعة 252 حرفًا لا تظهر في الأعمال المرجعية الحالية، مما يوفر مادة جديدة للغويين والمؤرخين. الأنظمة الحديثة للتعرف على الصور المدربة على هذه المجموعة تحقق دقة عالية، بينما تفشل النماذج المدربة فقط على كتابة يدوية مصطنعة فشلًا ذريعًا عند مواجهة صفحات حقيقية. تُظهر الدراسة أنه من خلال ترك الصور والمعاني يوجّه كل منهما الآخر، يمكن للذكاء الاصطناعي أن يساعد في إنقاذ خطوط مهددة بالاندثار التي تفتقر إلى وسم واسع، ويمكن تكييف نفس الاستراتيجية مع تقاليد تصويرية أخرى مثل شوِي ويي. في نهاية المطاف، يحول هذا العمل الكتب الطقسية الهشة إلى مورد رقمي قوي للتراث الثقافي والاكتشاف العلمي.
الاستشهاد: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
الكلمات المفتاحية: خط دونغبا, الكتابة القديمة, الحفظ الرقمي, نماذج الرؤية واللغة, التعرف على الحروف