Clear Sky Science · de
Ein neuartiges cross-modales Alignierungslern‑Framework zur Erstellung eines Dongba‑Einzelzeichen‑Datensatzes
Ein lebendiges Fossil der Schrift bewahren
Die Dongba‑Schrift der Naxi in China wird oft als ein „lebendiges Fossil“ der Schrift bezeichnet: Sie ist eines der letzten noch in religiösen Manuskripten verwendeten bildhaften Schriftsysteme. Nur eine kleine Zahl älterer Ritualspezialisten kann sie lesen, und die meisten erhaltenen Texte liegen nur als zerbrechliche handschriftliche Seiten vor. Diese Studie stellt einen neuen, KI‑gestützten Weg vor, um diese alternden Manuskripte in eine reichhaltige, durchsuchbare Datenbank einzelner Zeichen zu überführen und so ein einzigartiges Fenster in die Menschheitsgeschichte zu sichern.
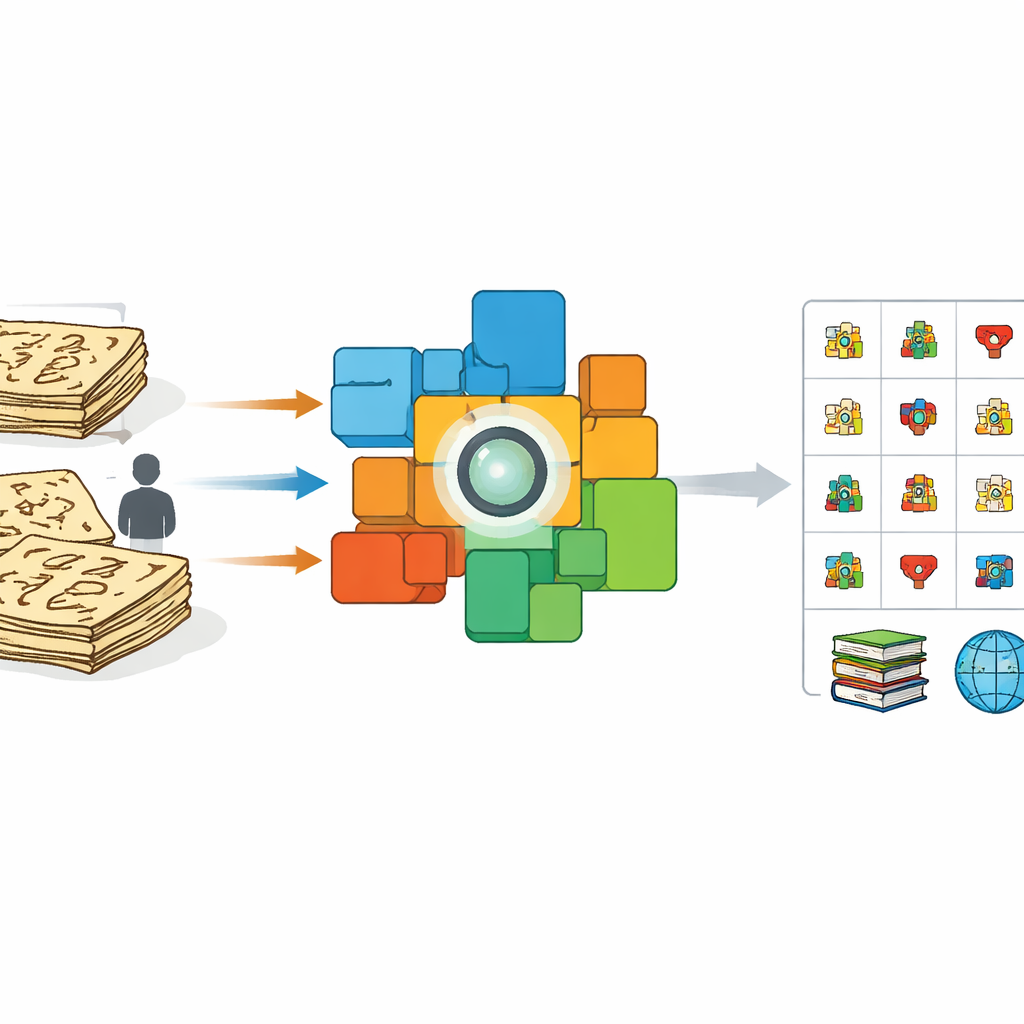
Warum alte Bilder für Computer schwierig sind
Auf den ersten Blick klingt es, als ließe sich einem Computer das Lesen von Dongba ähnlich beibringen wie andere Handschriften. Frühere Ansätze beruhen jedoch größtenteils auf Freiwilligen, die Zeichen mit modernen Stiften oder Stylus nachzeichnen, und auf automatischem „Dehnen“ und Verformen dieser sauberen Bilder. Solche sauberen Imitationen sehen sehr anders aus als die echten, mit Pinsel geschriebenen oder eingeritzten Zeichen in jahrhundertealten Büchern. Die Tintenstärke variiert, Striche brechen oder verschmelzen, und Schreibende improvisieren Formen. Folglich schneiden Systeme, die auf künstlichen Proben trainiert wurden, bei realen Manuskripten schlecht ab, besonders bei seltenen oder bislang nicht dokumentierten Symbolen. Gleichzeitig gibt es nur sehr wenige Spezialisten, die tausende Zeichen von Hand annotieren können, was die Bewahrung ausbremst.
Bilder und Bedeutungen gemeinsam lernen lassen
Die Autorinnen und Autoren wählen einen anderen Ansatz: Statt Experten zu bitten, jedes Zeichen einzeln zu beschriften, nutzen sie vollständige Seiten, die bereits zeilenweise chinesische Übersetzungen enthalten. Aus einer 100‑bändigen wissenschaftlichen Edition der Dongba‑Texte scannen sie Satzbilder und paaren jedes mit seiner passenden modernen Erklärung. Anschließend fine‑tunen sie ein leistungsfähiges Vision‑Language‑Modell, bekannt als CLIP, sodass in einem gemeinsamen mathematischen Raum Bilder von Dongba‑Sätzen nahe zu ihren Übersetzungen und fern von nicht zugehörigem Text gezogen werden. Dieses cross‑modale Training bringt den Bildencoder dazu, sich auf die visuellen Details zu konzentrieren, die Bedeutung tragen, und unordentliche Variationen in Pinselstrich oder Layout zu ignorieren.
Von ganzen Seiten zu einzelnen Zeichen
Sobald das Modell gelernt hat, wie ganze Sätze mit ihren Erklärungen zusammenhängen, richtet das Team den Blick auf einzelne Zeichen. Sie schneiden Zehntausende einzelner Symbole direkt aus den Manuskripten aus und bewahren deren unregelmäßiges, gealtertes Erscheinungsbild. Parallel erstellen sie ein Referenz‑„Wörterbuch“ aus Zeichenbildern aus Fachbüchern, jeweils verknüpft mit einer kurzen chinesischen Definition. Mit dem trainierten Bildencoder vergleichen sie jedes ausgeschnittene Manuskriptzeichen mit diesem Wörterbuch. Ist ein Manuskriptbild einem Wörterbucheintrag sehr ähnlich, wird es dieser bekannten Kategorie zugewiesen. Falls nicht, behandelt das System es als möglichen neuen Variantenfall, fügt dessen Merkmalsvektor dem Pool von Referenzbeispielen hinzu und markiert es zur fachlichen Überprüfung. Diese dynamische „Ankererweiterung“ weitet schrittweise die Bandbreite erkannter Formen und entdeckt sogar Zeichen, die in bestehenden Wörterbüchern fehlen.
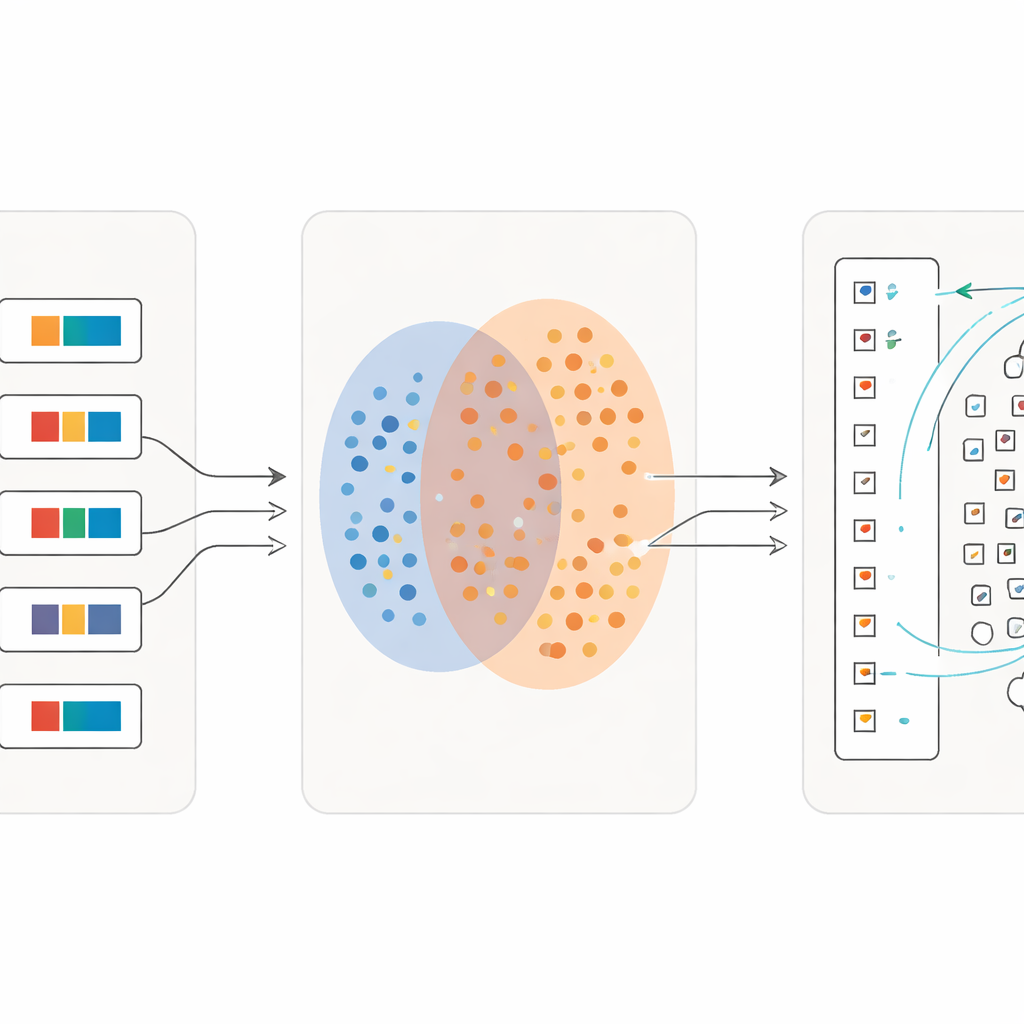
Feinere Lernstufen
Eine zentrale Innovation besteht darin, dass der Prozess nicht nach einem Durchgang stoppt. Sobald eine erste Welle von Zeichen zuverlässig zugeordnet ist, verwandeln die Forschenden diese Zuordnungen in neues Trainingsmaterial: Für jedes Einzelzeichen erstellen sie eine kurze beschreibende Phrase basierend auf seiner Wörterbuchbedeutung. Dann trainieren sie das Modell erneut an einer Mischung aus ganzen Sätzen und diesen fein granularen Zeichenbeschreibungen. Mit jeder Iteration wird das System empfindlicher für subtile Unterschiede zwischen visuell ähnlichen Zeichen und bleibt zugleich robust gegenüber schlampiger Handschrift. Über mehrere Runden steigt die Klassifikationsgenauigkeit von etwas über der Hälfte korrekt wiedergefundener Zeichen auf mehr als 97 Prozent, selbst für viele seltene Symbole mit nur wenigen Beispielen.
Ein neues digitales Archiv für die Zukunft
Am Ende erzeugt das Team Dongba_1512, einen groß angelegten Datensatz mit 705.058 Einzelzeichenbildern, gruppiert in 1.512 Kategorien, allesamt aus authentischen historischen Manuskripten entnommen. Die Sammlung umfasst 252 Zeichen, die in aktuellen Referenzwerken nicht auftauchen, und bietet damit neues Material für Linguisten und Historiker. Moderne Bilderkennungsmodelle, die mit diesem Datensatz trainiert wurden, erreichen hohe Genauigkeiten, während Modelle, die nur auf künstlicher Handschrift beruhen, bei echten Seiten stark versagen. Die Studie zeigt, dass durch das gegenseitige Leiten von Bildern und Bedeutungen KI helfen kann, bedrohte Schriftsysteme ohne umfangreiche Annotationen zu retten; dieselbe Strategie lässt sich auf andere bildhafte Traditionen wie Shui und Yi übertragen. Letztlich verwandelt diese Arbeit fragile Ritualbücher in eine robuste digitale Ressource für kulturelles Erbe und wissenschaftliche Entdeckung.
Zitation: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Schlüsselwörter: Dongba‑Schrift, alte Schrift, digitale Bewahrung, Vision‑Language‑Modelle, Zeichenerkennung