Clear Sky Science · he
מסגרת למידה חדשנית של תיאום חוצה‑מודאלי לבניית מאגר נתוני תווי‑מזרקה Dongba
שמירת פוסיל חי של הכתיבה
כתב הדונגבה של בני הלאצי בסין מכונה לעתים "פוסיל חי" של הכתיבה: זהו אחד ממערכות הציוריות הבודדות שנותרו בשימוש בטקסטים דתיים. עם זאת, רק מעטים מקרב המומחים המבוגרים מסוגלים לקרוא אותו, ורוב הטקסטים ששרדו קיימים בדפים כתובים בכתב יד שברירי. מחקר זה מציג דרך מונעת‑בינה מלאכותית להפוך כתבי יד מזדקנים למסד נתונים עשיר וחיפוש של תווים בודדים, ובכך לסייע לשמר חלון ייחודי להיסטוריה האנושית.
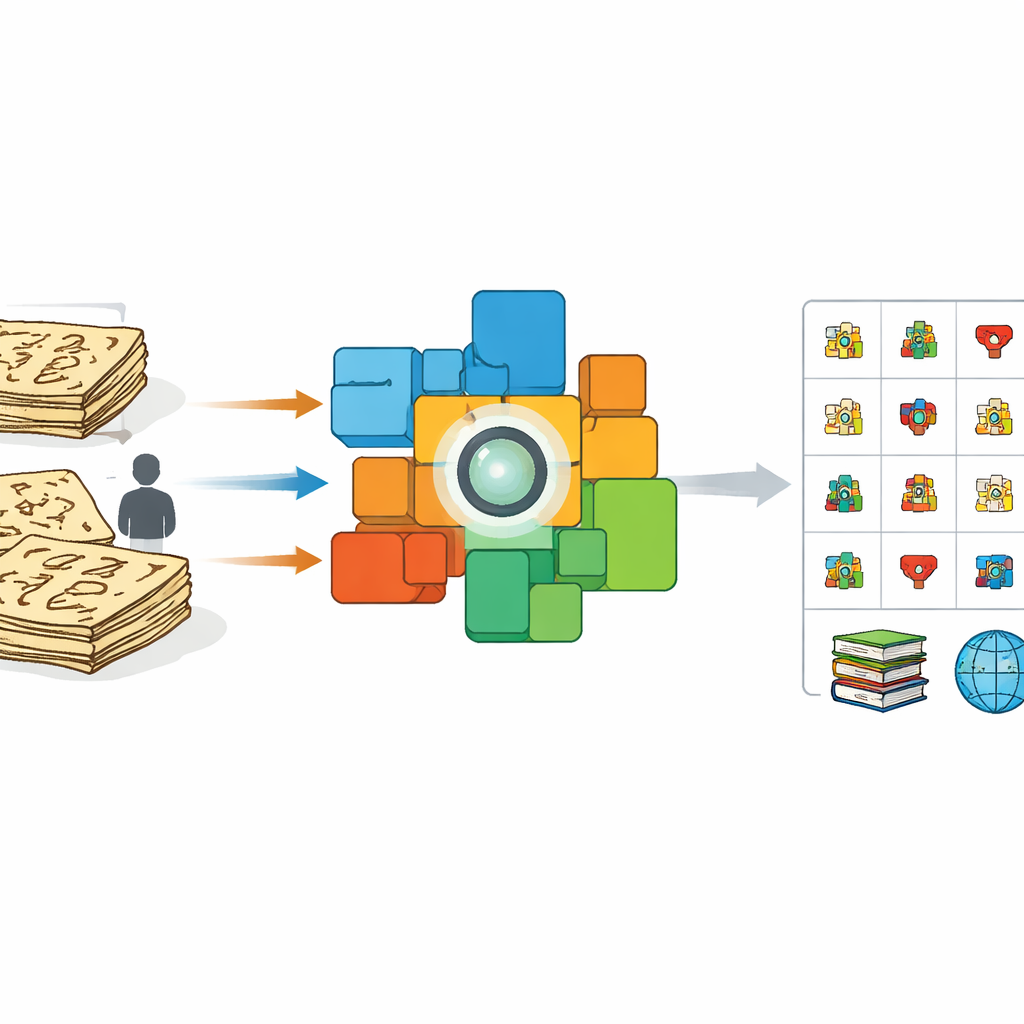
מדוע תמונות עתיקות קשות למחשבים
מבט ראשון עשוי לרמוז שלימוד מחשב לקרוא דונגבה דומה ללימודו לקרוא כתב יד אחר. אך מאמצים קודמים הסתמכו בעיקר על מתנדבים שהעתיקו תווים בעטים מודרניים או סטילוסים ועל עיוותים אוטומטיים של תמונות נקיות אלה. חיקויים מסודרים אלה נראים שונה מאוד מהתווים הכתובים במברשת או החקוקים בספרים בני מאות שנים. צפיפות הדיו משתנה, המהלכים נשברים ונמסים, וכותבים ממציאים צורות. כתוצאה מכך, מערכות שאומנו על דגימות מלאכותיות מתקשות עם כתב היד המקורי, במיוחד מול סמלים נדירים או שלא תועדו בעבר. במקביל, יש מעט מומחים שיכולים לתייג אלפי תווים ידנית, מה שיוצר צוואר בקבוק לשימור.
לאפשר לתמונות ולמשמעויות ללמוד יחד
המחברים נוקטים בגישה שונה: במקום לבקש מהמומחים לתייג כל תו בנפרד, הם מנצלים דפים שלמים שמגיעים כבר עם תרגומים שורה‑אחר‑שורה לסינית מודרנית. מתוך מהדורה מדעית בת 100 כרכים של טקסטי דונגבה, הם סורקים תמונות של משפטים ומזווגים כל אחת להסבר המתאים. אחר כך הם כיווננו עדין מודל ראייה‑שפה חזק הידוע בשם CLIP, כך שבתוך מרחב מתמטי משותף, תמונות של משפטי דונגבה נמשכות לעבר תרגומיהן ומודדות הרחק מטקסט לא קשור. אימון חוצה‑מודאלי זה מחדד את מקודד התמונה להתמקד בפרטי הוויזואל שמעניקים משמעות ולהתעלם מהשינויים הקודרים במהלכי המברשת או בפריסת הדף.
מעמודים שלמים אל סימנים בודדים
לאחר שהמודל למד כיצד משפטים שלמים מתקשרים להסבריהם, הצוות עובר לעבודת התווים הבודדים. הם גוזרים עשרות אלפי סמלים יחידים ישירות מהכתבי יד, ושומרים על המראה הלא‑סדיר והשחוק שלהם. במקביל בונים הם "מילון" התייחסות של תמונות תווים מתוך ספרים של מומחים, כל אחת מקושרת להגדרה קצרה בסינית. באמצעות מקודד התמונה המאומן הם משווים כל תו מגזור מהכתבי יד אל אותו מילון. אם תמונת הכתבי יד דומה מאוד לתמונת מילון, היא משויכת לאותה קטגוריה ידועה. אם לא, המערכת מתייחסת אליה כאפשרות לווריאנט חדש, מוסיפה את התכונה שלה אל בריכת דגימות ההתייחסות ומסמנת אותה לבדיקת מומחה. "הרחבת עוגן" דינמית זו מרחיבה בהדרגה את טווח הצורות המזוהות ואף חושפת תווים חסרים במילונים קיימים.
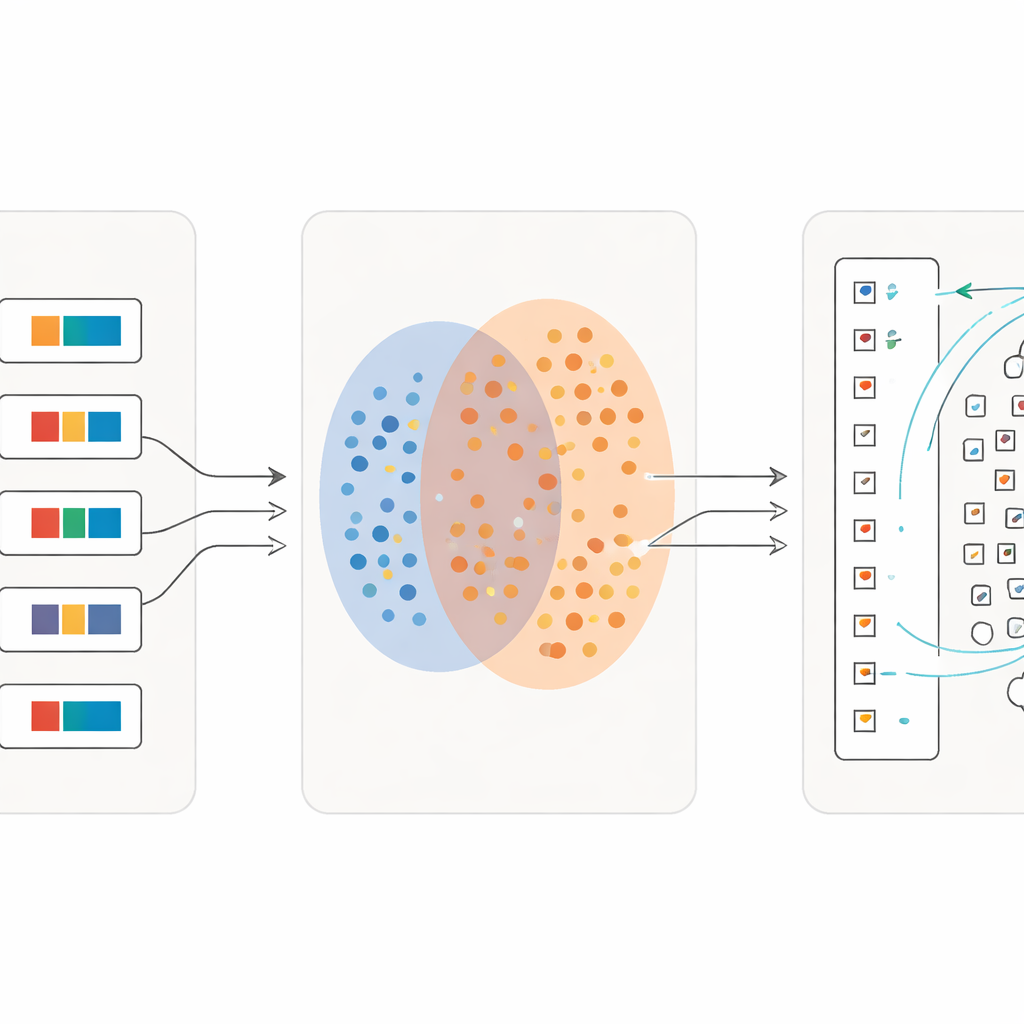
למידה בפרטים עדינים יותר
חידוש מרכזי הוא שהתהליך אינו נעצר לאחר מעבר אחד. אחרי גל ראשון של התאמות אמינות, החוקרים הופכים התאמות אלה לחומר אימון חדש: עבור כל סמל בודד הם יוצרים ביטוי תיאורי קצר באמצעות משמעותו במילון. לאחר מכן הם מאמנים מחדש את המודל על תערובת של משפטים שלמים ותיאורים עד‑דקיקים של תווים. בכל איטרציה המערכת נהיית רגישה יותר להבדלים זעירים בין סמלים דומים חזותית בעוד שהיא נשארת חסינה לכתיבה מרושלת. לאורך מספר סבבים דיוק המיון עולה ממעט מעל מחצית התווים שנשלפו נכון ליותר מ‑97 אחוזים, אפילו עבור רבים מהסמלים הנדירים שיש להם רק מספר מועט של דוגמאות.
ארכיון דיגיטלי חדש לעתיד
בסופו של דבר, הצוות מייצר Dongba_1512, מאגר נתונים בקנה מידה גדול של 705,058 תמונות תווים בודדים מקובצות ל‑1,512 קטגוריות, כלן מצויות בכתבי יד היסטוריים אותנטיים. האוסף כולל 252 תווים שאינם מופיעים בעבודות ההתייחסות הנוכחיות, ומספק חומר חדש ללשונאים והיסטוריונים. מערכות זיהוי תמונה מודרניות שאולפו על מאגר זה משיגות דיוק גבוה, בעוד שמודלים שאולפו רק על כתב יד מלאכותי נכשלים קשות מול דפים אמיתיים. המחקר מראה שבעזרת הדרכה הדדית של תמונות ומשמעויות, הבינה המלאכותית יכולה לסייע להציל כתבי־יד בסכנת הכחדה שמחסור ההסברים שלהם גדול, ואותה אסטרטגיה ניתנת להתאמה למסורות ציוריות אחרות כמו Shui ו‑Yi. בסופו של דבר, עבודה זו הופכת ספרי פולחן שבירים למשאב דיגיטלי יציב למורשת תרבותית ולגילוי מדעי.
ציטוט: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
מילות מפתח: כתב דונגבה, כתיבה עתיקה, שימור דיגיטלי, מודלים ראייה‑שפה, זיהוי תווים