Clear Sky Science · sv
En ny tvärmodal inlärningsram för upprättandet av Dongba-datasetet med enstaka tecken
Rädda en levande fossil av skrift
Dongba-skriften hos Kinas Naxi-folk kallas ofta en ”levande fossil” inom skrift: det är ett av de sista piktografiska systemen som fortfarande används i religiösa manuskript. Endast ett fåtal äldre rituella specialister kan läsa det, och de flesta bevarade texter finns enbart som sköra handskrivna sidor. Denna studie presenterar ett nytt artificiellt intelligensdrivet sätt att förvandla dessa åldrande manuskript till en rik, sökbar databas av enstaka tecken, vilket hjälper till att skydda ett unikt fönster in i mänsklighetens historia.
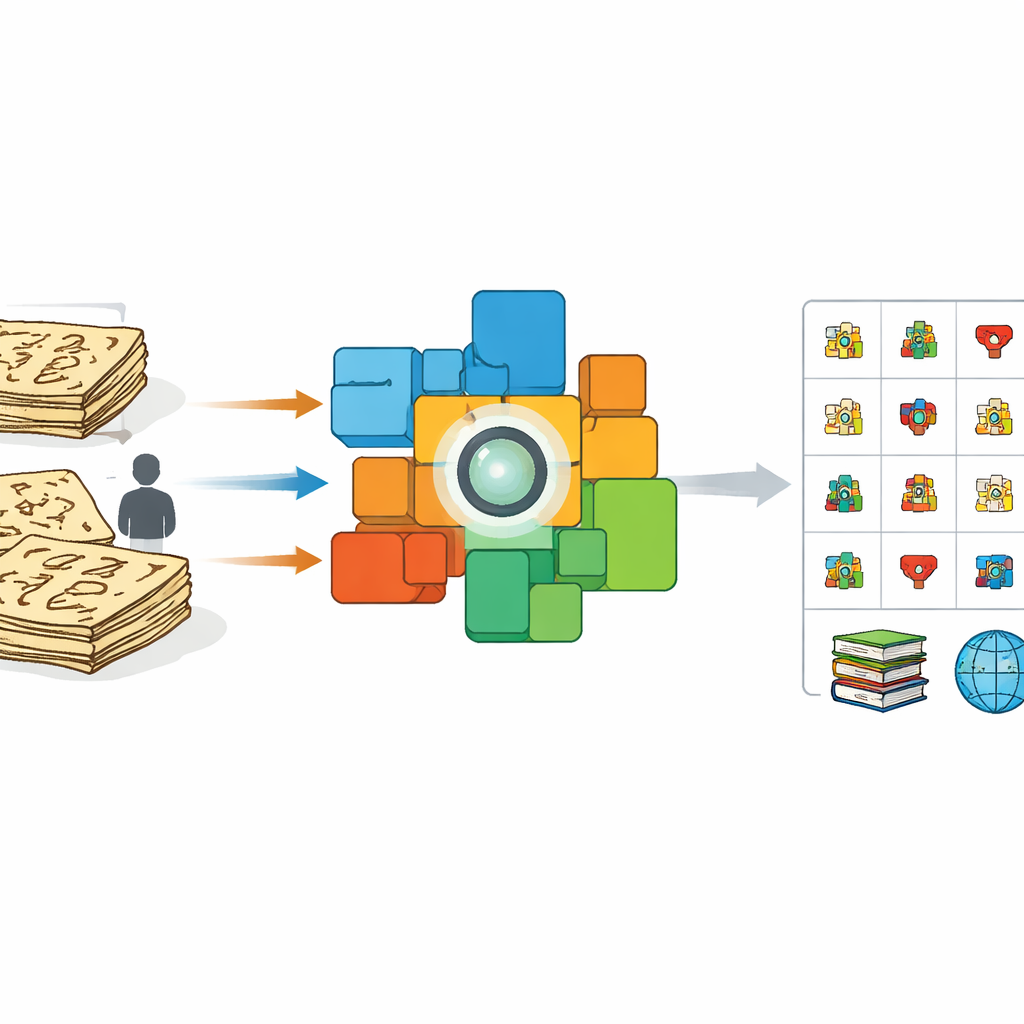
Varför forntida bilder är svåra för datorer
Vid första anblick kan det verka som att lära en dator läsa Dongba är som att lära den läsa annan handstil. Tidigare försök förlitade sig dock mest på volontärer som kopierade tecken med moderna pennor eller stylusar och på automatisk ”stretching” och warping av dessa rena bilder. Dessa prydliga imitationer ser mycket annorlunda ut än de verkliga borstskrivna eller inhuggna tecknen i århundraden gamla böcker. Bläckets täthet varierar, streck bryts och smälter samman, och skribenter improviserar former. Som ett resultat presterar system som tränats på konstgjorda exempel dåligt på riktiga manuskript, särskilt när de möter sällsynta eller tidigare odokumenterade symboler. Samtidigt finns det mycket få specialister som kan märka tusentals tecken för hand, vilket skapar en flaskhals för bevarandet.
Låta bilder och betydelser lära sig tillsammans
Författarna väljer en annan väg: i stället för att be experter märka varje tecken ett efter ett, utnyttjar de kompletta sidor som redan har rad-för-rad-kinesiska översättningar. Ur en 100-volyms vetenskaplig utgåva av Dongba-texter skannar de meningsbilder och parar varje bild med dess matchande moderna förklaring. De finjusterar sedan en kraftfull vision–språkmodell känd som CLIP så att, i ett gemensamt matematiskt rum, bilder av Dongba-meningar dras nära sina översättningar och skjuts ifrån orelaterad text. Denna tvärmodala träning får bildkodaren att fokusera på de visuella detaljer som bär betydelse och att bortse från röriga variationer i borststreck eller layout.
Från helsidor till enskilda tecken
När modellen väl har lärt sig hur hela meningar relaterar till sina förklaringar går teamet vidare till enskilda tecken. De beskär tiotusentals enskilda symboler direkt från manuskripten och bevarar deras oregelbundna, åldrade utseende. Parallellt bygger de ett referens"ordbok" av teckenbilder tagna från fackböcker, där varje bild länkas till en kort kinesisk definition. Med den tränade bildkodaren jämför de varje beskuret manus-tecken med denna ordlista. Om en manusbild är extremt lik en ordlistbild tilldelas den den kända kategorin. Om inte behandlas systemet den som en möjlig ny variant, lägger till dess egenskap i poolen av referensexempel och flaggar den för expertgranskning. Denna dynamiska ”ankarexpansion” breddar successivt utbudet av igenkända former och upptäcker till och med tecken som saknas i befintliga ordböcker.
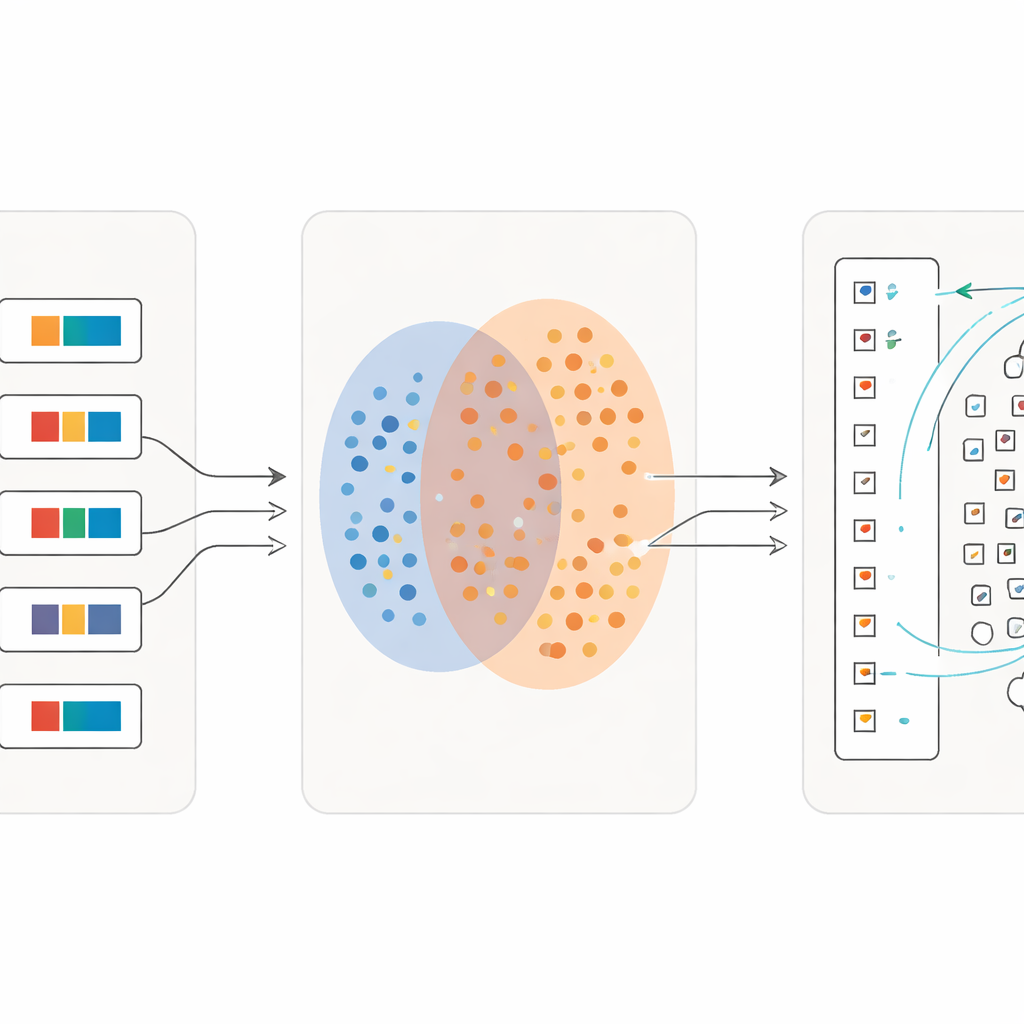
Lära sig i allt finare detaljer
En viktig innovation är att processen inte slutar efter en genomgång. När en första våg av tecken har matchats pålitligt förvandlar forskarna dessa matchningar till nytt träningsmaterial: för varje enskild symbol skapar de en kort beskrivande fras med hjälp av dess ordboksbetydelse. De tränar sedan om modellen på en blandning av hela meningar och dessa finfördelade teckenbeskrivningar. För varje iteration blir systemet mer känsligt för subtila skillnader mellan visuellt liknande tecken samtidigt som det förblir robust mot slarvig skrift. Över flera omgångar ökar klassificeringsnoggrannheten från strax över hälften korrekt återgivna tecken till mer än 97 procent, även för många sällsynta symboler med endast ett fåtal exempel.
Ett nytt digitalt arkiv för framtiden
I slutändan producerar teamet Dongba_1512, ett storskaligt dataset med 705 058 enskilda teckenbilder grupperade i 1 512 kategorier, alla hämtade från autentiska historiska manuskript. Samlingen inkluderar 252 tecken som inte förekommer i nuvarande referensverk och erbjuder nytt material för lingvister och historiker. Moderna bildigenkänningssystem som tränats på detta dataset uppnår hög noggrannhet, medan modeller som endast tränats på konstgjord handskrift misslyckas när de ställs inför riktiga sidor. Studien visar att genom att låta bilder och betydelser guida varandra kan AI hjälpa till att rädda hotade skriftsystem som saknar omfattande annoteringar, och samma strategi kan anpassas till andra piktografiska traditioner som Shui och Yi. I slutändan förvandlar detta arbete sköra rituella böcker till en robust digital resurs för kulturellt arv och vetenskapliga upptäckter.
Citering: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Nyckelord: Dongba-skrift, forn skrift, digital bevarande, vision-språkmodeller, teckenigenkänning