Clear Sky Science · en
A novel cross-modal alignment learning framework for Dongba single-character dataset construction
Saving a Living Fossil of Writing
The Dongba script of China’s Naxi people is often called a “living fossil” of writing: it is one of the last pictographic systems still used in religious manuscripts. Yet only a small number of elderly ritual specialists can read it, and most surviving texts exist only as fragile handwritten pages. This study introduces a new artificial‑intelligence–driven way to turn those aging manuscripts into a rich, searchable database of individual characters, helping safeguard a unique window into human history.
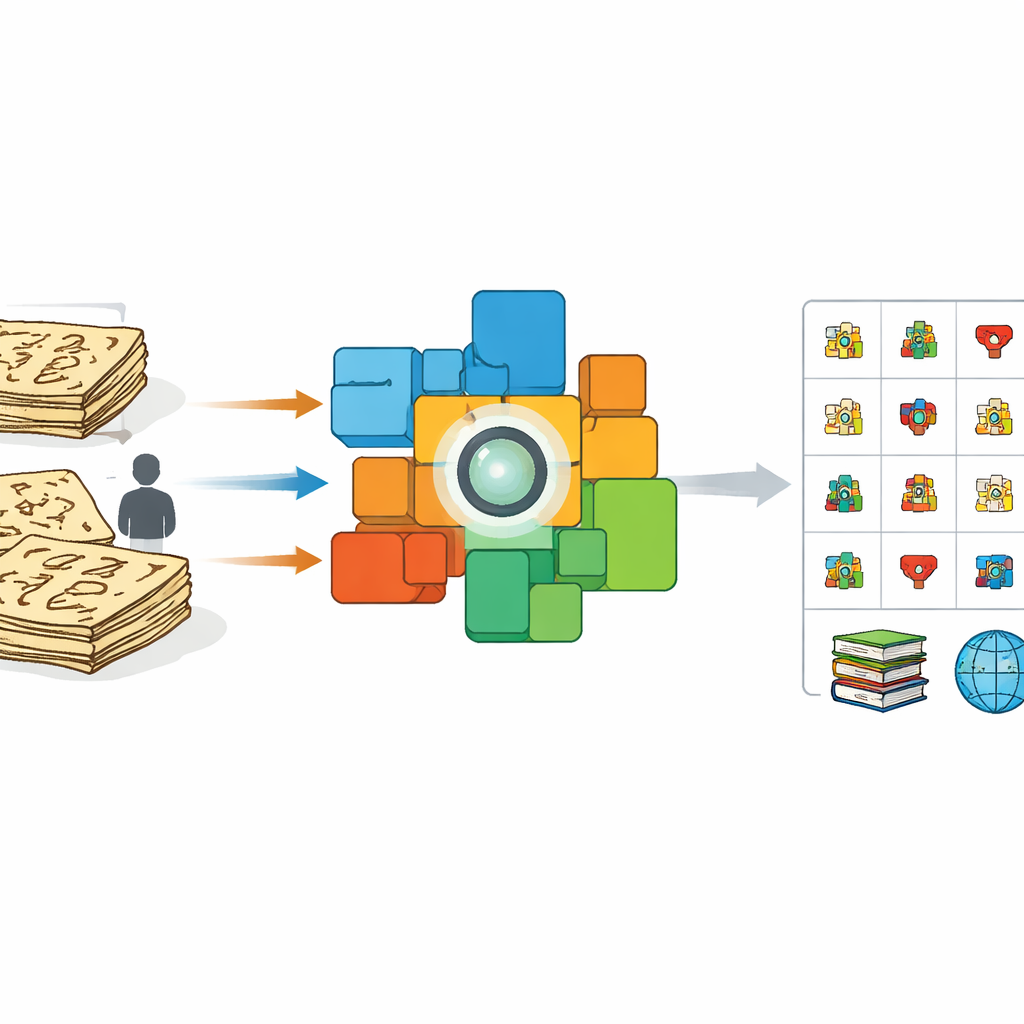
Why Ancient Pictures Are Hard for Computers
At first glance, teaching a computer to read Dongba might sound like teaching it to read any other handwriting. But past efforts relied mostly on volunteers copying characters with modern pens or styluses and on automatic “stretching” and warping of those clean images. These neat imitations look very different from the real brush‑written or carved characters in centuries‑old books. Ink density varies, strokes break and merge, and writers improvise shapes. As a result, systems trained on artificial samples perform poorly on real manuscripts, especially when they meet rare or previously undocumented symbols. At the same time, there are very few specialists able to label thousands of characters by hand, creating a bottleneck for preservation.
Letting Images and Meanings Learn Together
The authors take a different approach: instead of asking experts to label each character one by one, they exploit complete pages that already come with line‑by‑line Chinese translations. From a 100‑volume scholarly edition of Dongba texts, they scan sentence images and pair each with its matching modern explanation. They then fine‑tune a powerful vision‑language model known as CLIP so that, in a shared mathematical space, pictures of Dongba sentences are pulled close to their translations and pushed away from unrelated text. This cross‑modal training nudges the image encoder to focus on the visual details that carry meaning and to ignore messy variations in brush strokes or layout.
From Whole Pages to Individual Signs
Once the model has learned how entire sentences relate to their explanations, the team turns to individual characters. They crop tens of thousands of single symbols directly from the manuscripts, preserving their irregular, time‑worn appearance. In parallel, they build a reference “dictionary” of character images taken from specialist books, each linked to a short Chinese definition. Using the trained image encoder, they compare every cropped manuscript character to this dictionary. If a manuscript image is extremely similar to a dictionary image, it is assigned to that known category. If not, the system treats it as a possible new variant, adds its feature to the pool of reference examples, and flags it for expert checking. This dynamic “anchor expansion” gradually broadens the range of recognized forms and even uncovers characters missing from existing dictionaries.
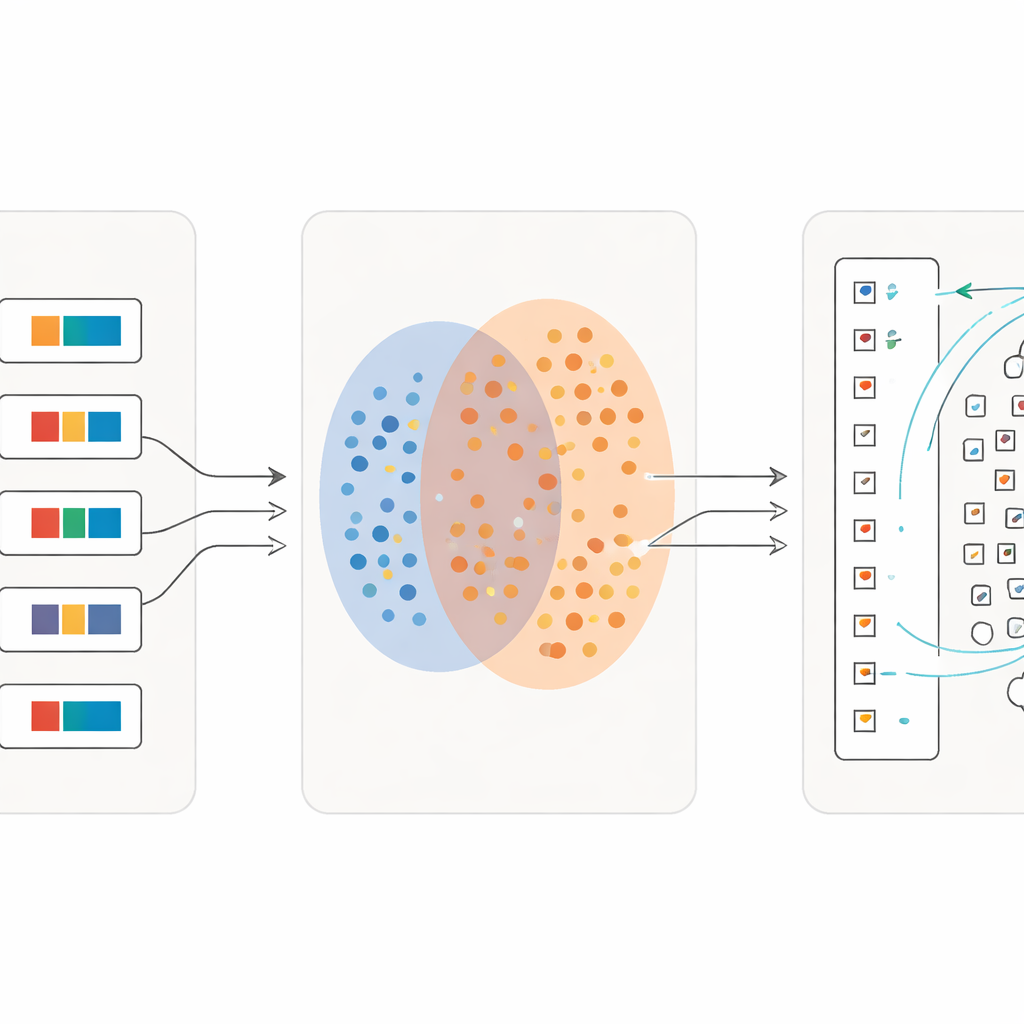
Learning in Ever Finer Detail
A key innovation is that the process does not stop after one pass. Once a first wave of characters has been reliably matched, the researchers turn these matches into new training material: for each single symbol, they create a short descriptive phrase using its dictionary meaning. They then retrain the model on a mixture of full sentences and these fine‑grained character descriptions. With every iteration, the system becomes more sensitive to subtle differences between visually similar signs while remaining robust to sloppy writing. Over several rounds, classification accuracy climbs from just over half of characters correctly retrieved to more than 97 percent, even for many rare symbols with only a handful of examples.
A New Digital Archive for the Future
In the end, the team produces Dongba_1512, a large‑scale dataset of 705,058 single‑character images grouped into 1,512 categories, all drawn from authentic historical manuscripts. The collection includes 252 characters that do not appear in current reference works, offering fresh material for linguists and historians. Modern image‑recognition systems trained on this dataset achieve high accuracy, while models trained only on artificial handwriting fail badly when faced with real pages. The study shows that by letting pictures and meanings guide each other, AI can help rescue endangered scripts that lack extensive annotations, and the same strategy can be adapted to other pictographic traditions such as Shui and Yi. Ultimately, this work turns fragile ritual books into a robust digital resource for cultural inheritance and scholarly discovery.
Citation: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Keywords: Dongba script, ancient writing, digital preservation, vision-language models, character recognition