Clear Sky Science · nl
Een nieuw cross‑modaal alignement‑leerraamwerk voor de constructie van een Dongba‑eenkarakterdataset
Het bewaren van een levend fossiel van schrift
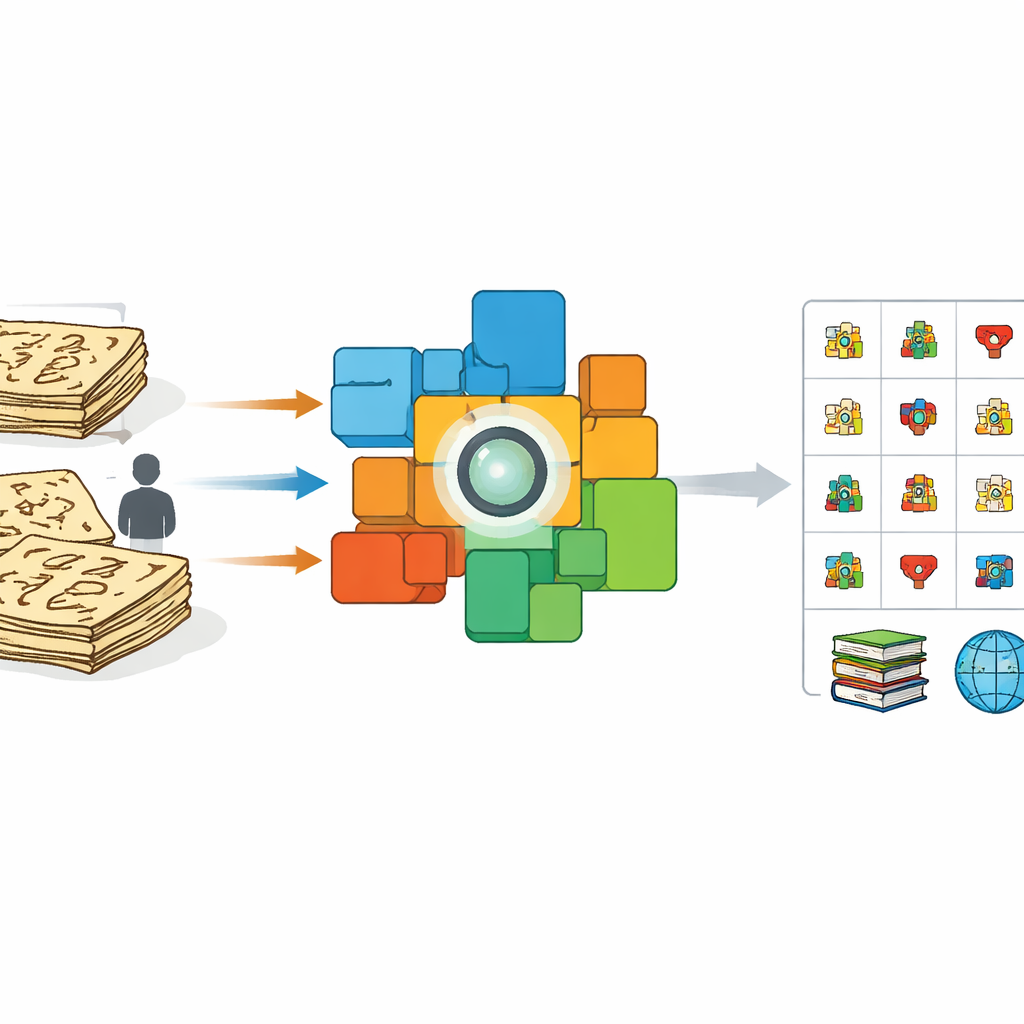
Het Dongba‑schrift van het Naxi‑volk in China wordt vaak een “levend fossiel” van schrift genoemd: het is een van de laatste pictografische systemen die nog gebruikt worden in religieuze manuscripten. Slechts een klein aantal oudere rituele specialisten kan het lezen, en de meeste overgebleven teksten bestaan alleen als kwetsbare handgeschreven pagina’s. Deze studie introduceert een nieuwe door kunstmatige intelligentie aangedreven methode om die verouderende manuscripten om te zetten in een rijke, doorzoekbare database van individuele tekens, waarmee een uniek venster op de menselijke geschiedenis wordt veiliggesteld.
Waarom oude afbeeldingen moeilijk zijn voor computers
Op het eerste gezicht lijkt het een computer leren Dongba te lezen op het leren van elk ander handschrift: maar eerdere pogingen vertrouwden vooral op vrijwilligers die tekens met moderne pennen of stylussen kopieerden en op automatische “stretching” en vervorming van die schone beelden. Die nette imitaties zien er heel anders uit dan de echte met een penseel geschreven of gekerfde tekens in eeuwenoude boeken. De inktdichtheid varieert, lijnen breken en vloeien in elkaar over, en schrijvers improviseren vormen. Daardoor presteren systemen die op kunstmatige voorbeelden zijn getraind slecht op echte manuscripten, vooral bij zeldzame of eerder niet‑gedocumenteerde symbolen. Tegelijkertijd zijn er maar weinig specialisten die duizenden tekens met de hand kunnen labelen, wat een knelpunt vormt voor behoud.
Beelden en betekenissen samen laten leren
De auteurs volgen een andere benadering: in plaats van experts elk teken één voor één te laten labelen, benutten ze volledige pagina’s die al regel‑voor‑regel Chinese vertalingen bevatten. Uit een 100‑delige wetenschappelijke editie van Dongba‑teksten scannen ze zinbeelden en koppelen elk beeld aan de bijbehorende moderne uitleg. Ze fine‑tunen vervolgens een krachtig vision‑language‑model bekend als CLIP zodat afbeeldingen van Dongba‑zinnen en hun vertalingen in een gedeelde wiskundige ruimte naar elkaar toe worden getrokken en van niet‑gerelateerde tekst worden weggeduwd. Deze cross‑modale training stuurt de beeldencoder ertoe zich te concentreren op visuele details die betekenis dragen en rommelige variaties in penseelstreken of layout te negeren.
Van volledige pagina’s naar individuele tekens
Zodra het model heeft geleerd hoe volledige zinnen zich verhouden tot hun verklaringen, richten de onderzoekers zich op individuele tekens. Ze knippen tienduizenden losse symbolen direct uit de manuscripten, waarbij ze hun onregelmatige, verweerde verschijning behouden. Parallel daaraan bouwen ze een referentie"woordenboek" van karakterafbeeldingen uit specialistische werken, elk gekoppeld aan een korte Chinese definitie. Met de getrainde beeldencoder vergelijken ze elk geknipt manuscriptteken met dit woordenboek. Als een manuscriptafbeelding extreem veel lijkt op een woordenboekafbeelding, wordt deze aan die bekende categorie toegewezen. Zo niet, dan behandelt het systeem het als een mogelijke nieuwe variant, voegt de feature toe aan de pool van referentievoorbeelden en markeert het voor deskundige controle. Deze dynamische "anchor expansion" vergroot geleidelijk het bereik van herkende vormen en ontdekt zelfs tekens die ontbreken in bestaande woordenboeken.
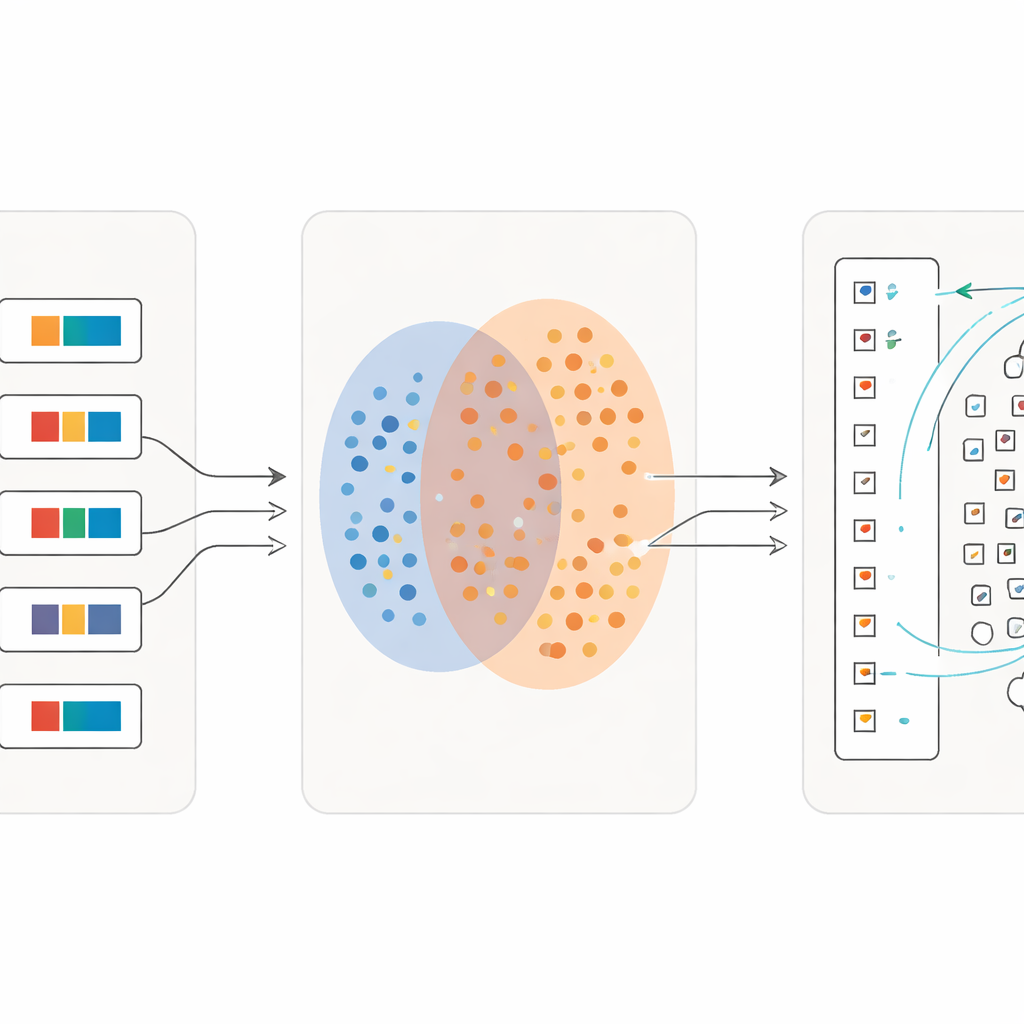
Leren in steeds fijnere details
Een belangrijke innovatie is dat het proces niet stopt na één ronde. Zodra een eerste golf tekens betrouwbaar is gekoppeld, gebruiken de onderzoekers die matches als nieuw trainingsmateriaal: voor elk enkel symbool maken ze een korte beschrijvende zin op basis van de woordenboekbetekenis. Ze hertrainen het model vervolgens op een mengeling van volledige zinnen en deze fijnmazige karakterbeschrijvingen. Met elke iteratie wordt het systeem gevoeliger voor subtiele verschillen tussen visueel vergelijkbare tekens, terwijl het robuust blijft tegen slordig schrift. Over meerdere rondes stijgt de classificatie‑nauwkeurigheid van net boven de helft correct teruggevonden tekens tot meer dan 97 procent, zelfs voor veel zeldzame symbolen met slechts een paar voorbeelden.
Een nieuw digitaal archief voor de toekomst
Uiteindelijk levert het team Dongba_1512 op, een grootschalige dataset van 705.058 afbeeldingen van enkele tekens gegroepeerd in 1.512 categorieën, allemaal afkomstig uit authentieke historische manuscripten. De collectie bevat 252 tekens die niet in huidige naslagwerken voorkomen, wat nieuw materiaal biedt voor taalkundigen en historici. Moderne beeldherkenningssystemen getraind op deze dataset bereiken een hoge nauwkeurigheid, terwijl modellen die alleen op kunstmatig handschrift zijn getraind slecht presteren bij echte pagina’s. De studie toont aan dat door beelden en betekenissen elkaar te laten sturen, AI kan helpen bedreigde schriften zonder uitgebreide annotaties te redden, en dat dezelfde strategie kan worden aangepast aan andere pictografische tradities zoals Shui en Yi. Uiteindelijk verandert dit werk fragiele rituele boeken in een robuuste digitale bron voor cultureel erfgoed en wetenschappelijke ontdekking.
Bronvermelding: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Trefwoorden: Dongba‑schrift, oud schrift, digitale bewaring, vision‑language‑modellen, karakterherkenning