Clear Sky Science · ja
ドンバ単字データセット構築のための新しいクロスモーダル整合学習フレームワーク
生きた化石とも呼ばれる文字を救う
中国ナシ族のドンバ文字は「生きた化石」と称されることが多い。宗教写本で今なお使われる数少ない象形文字体系のひとつだからだ。しかし読めるのは高齢の儀礼専門家がごくわずかであり、残存する本文の多くは壊れやすい手書きの頁としてしか存在しない。本研究は、こうした古い写本を個々の文字の豊富で検索可能なデータベースに変換するための新しい人工知能駆動の手法を提示し、人類史の独特な窓を保護する手助けをする。
古い絵文字がコンピュータにとって難しい理由
一見すると、ドンバをコンピュータに読ませるのは他の手書き文字を学習させるのと同じように思える。しかしこれまでの試みは主にボランティアが現代のペンやスタイラスで文字を模写することや、きれいな画像を自動的に「伸張」や歪変換することに頼っていた。そうして作られた整った模倣は、何世紀も前の筆で書かれたり彫られたりした本物の文字とは大きく異なる。墨の濃淡が変わり、画が切れたりつながったりし、書き手が形を即興で変えることもある。その結果、人工的なサンプルで訓練されたシステムは実際の写本では性能が低く、とくに稀なあるいは未記録の記号に出会うと著しく失敗する。一方で、数千の文字を手作業でラベリングできる専門家は非常に少なく、保存のためのボトルネックになっている。
画像と意味を同時に学習させる
著者らは異なるアプローチを採る。専門家に一字ずつラベル付けを頼む代わりに、行ごとの中国語翻訳が付された完全な頁を活用するのである。ドンバ文献の学術版100巻から、彼らは文の画像をスキャンし、それぞれを対応する現代語の説明と組にする。次に、CLIPとして知られる強力なビジョン・ランゲージモデルを微調整し、共有の数学的空間でドンバ文の画像がその翻訳に近づき、無関係なテキストから遠ざかるようにする。このクロスモーダル学習により、画像エンコーダは意味を担う視覚的細部に注目し、筆致やレイアウトの乱れを無視するよう促される。
全頁から単一の記号へ
モデルが文全体とその説明の関係を学んだ後、研究チームは個々の文字へと向かう。写本から数万の単一記号を切り出し、時代を経た不均一な外観をそのまま保つ。同時に、専門書から採った文字画像を短い中国語定義に結び付けた参照「辞書」を構築する。訓練済みの画像エンコーダを用いて、切り出した写本文字を辞書の各画像と比較する。写本画像が辞書画像と非常に類似する場合は既知のカテゴリに割り当てられる。類似しない場合は新しいバリアントの候補として扱われ、その特徴を参照例のプールに追加し、専門家の確認のためにフラグを立てる。この動的な「アンカー拡張」により、認識可能な形態の幅が段階的に広がり、既存の辞書に欠けていた文字さえも発見されることがある。
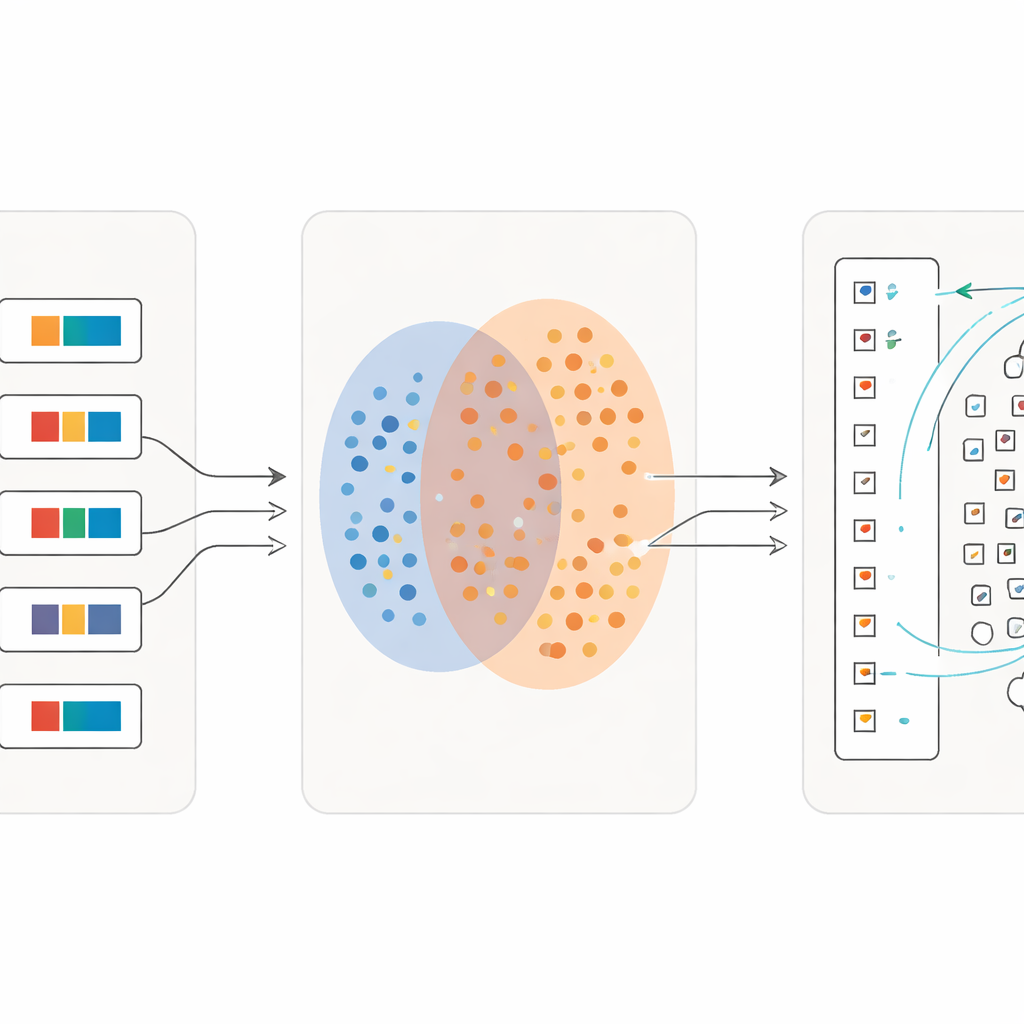
より細部へと学習を進める
重要な革新は、このプロセスが一巡で終わらない点にある。最初の波で信頼できる一致が得られると、研究者らはこれらの一致を新たな訓練素材に変える。各単字について、辞書の意味を用いて短い記述句を作成し、文全体のデータとこれら細粒度の文字記述の混合でモデルを再訓練する。反復ごとに、システムは視覚的に似た記号間の微妙な違いに対してより敏感になり、同時に乱雑な筆致には頑健なままである。数回のラウンドを経て、分類精度は最初の約半数から、例がごく少数しかない稀な記号に対しても97パーセント以上へと向上する。
未来のための新しいデジタルアーカイブ
最終的に、チームはDongba_1512という大規模データセットを作成した。これは本物の歴史的写本から抽出された705,058枚の単字画像を1,512カテゴリに分類したものである。コレクションには現行の参考文献に載っていない252字が含まれ、言語学者や歴史家に新たな資料を提供する。現代の画像認識システムはこのデータセットで高精度を達成する一方、人工的な手書きのみで訓練したモデルは実際の頁に直面すると大きく失敗する。本研究は、画像と意味を相互に導くことで、注釈が十分でない危機に瀕した文字体系を救う手助けができることを示しており、同じ戦略は水族(Shui)やイー(Yi)など他の象形的伝統にも応用できる。最終的に、この仕事は壊れやすい儀礼書を文化的継承と学術発見のための堅牢なデジタル資源へと変える。
引用: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
キーワード: トンバ文字, 古代の筆記, デジタル保存, ビジョン・ランゲージモデル, 文字認識