Clear Sky Science · pt
Um novo quadro de aprendizado de alinhamento cross-modal para construção de um conjunto de dados de caracteres únicos Dongba
Salvando um fóssil vivo da escrita
O sistema Dongba do povo Naxi, na China, é frequentemente chamado de um “fóssil vivo” da escrita: é um dos últimos sistemas pictográficos ainda usados em manuscritos religiosos. Contudo, apenas um pequeno número de especialistas ritualísticos idosos consegue lê‑lo, e a maioria dos textos sobreviventes existe somente como páginas manuscritas frágeis. Este estudo apresenta uma nova abordagem orientada por inteligência artificial para transformar esses manuscritos envelhecidos em um banco de dados rico e pesquisável de caracteres individuais, ajudando a proteger uma janela única para a história humana.
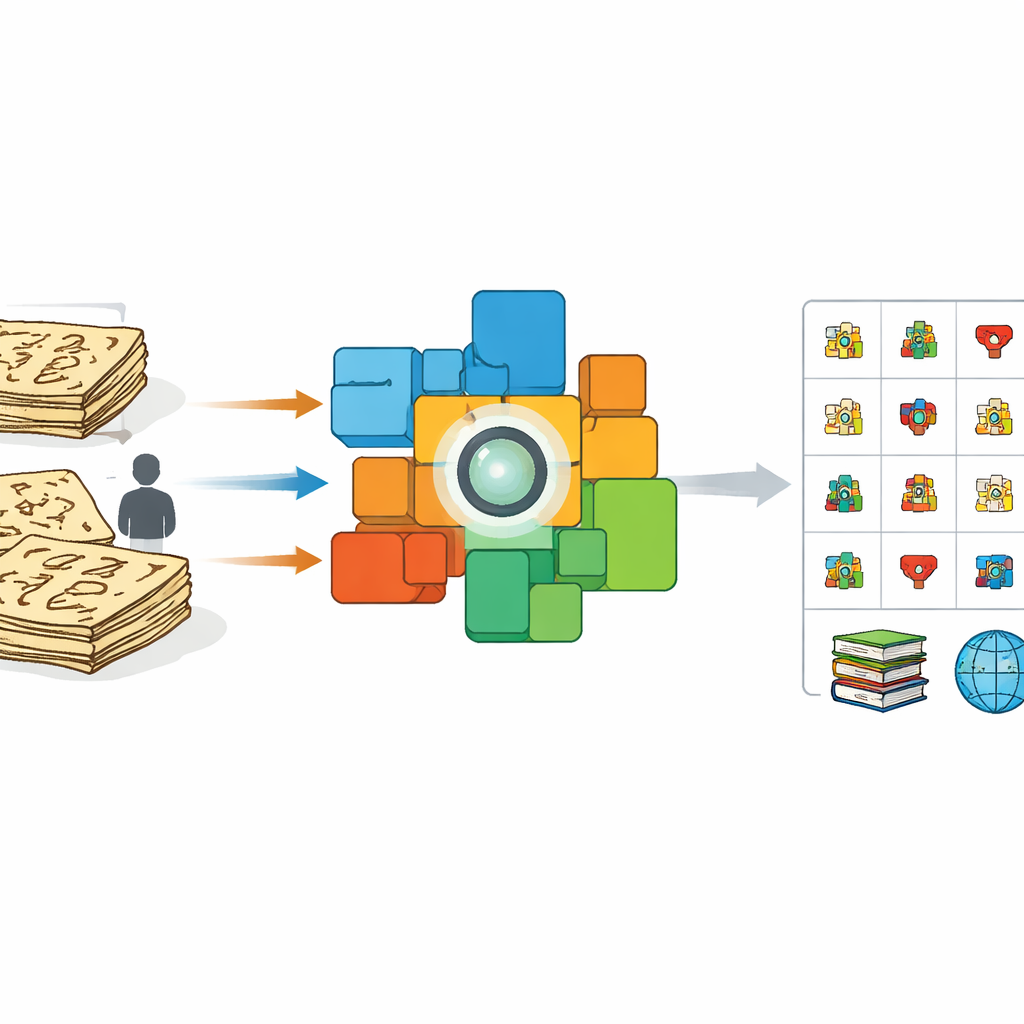
Por que imagens antigas são difíceis para computadores
À primeira vista, ensinar um computador a ler Dongba pode parecer o mesmo que ensiná‑lo a ler qualquer outra caligrafia. Mas esforços anteriores dependeram principalmente de voluntários que copiavam caracteres com canetas modernas ou stylus e de “esticamentos” e deformações automáticas dessas imagens limpas. Essas imitações bem comportadas parecem muito diferentes dos caracteres reais escritos a pincel ou gravados em livros com séculos de idade. A densidade da tinta varia, traços se quebram e se fundem, e os escribas improvisam formas. Como resultado, sistemas treinados em amostras artificiais têm desempenho ruim em manuscritos reais, especialmente quando encontram símbolos raros ou anteriormente não documentados. Ao mesmo tempo, há muito poucos especialistas capazes de rotular milhares de caracteres manualmente, criando um gargalo para a preservação.
Pondo imagens e significados para aprenderem juntos
Os autores adotam uma abordagem diferente: em vez de pedir aos especialistas que rotulem cada caractere um a um, eles aproveitam páginas completas que já vêm com traduções linha a linha em chinês moderno. A partir de uma edição acadêmica de 100 volumes dos textos Dongba, digitalizam imagens de sentenças e emparelham cada uma com sua explicação correspondente. Em seguida, eles refinam um poderoso modelo visão‑linguagem conhecido como CLIP para que, em um espaço matemático compartilhado, imagens de sentenças Dongba sejam aproximadas de suas traduções e afastadas de textos não relacionados. Esse treinamento cross‑modal incentiva o codificador de imagem a concentrar‑se nos detalhes visuais que carregam significado e a ignorar variações desordenadas em traços de pincel ou layout.
De páginas inteiras a sinais individuais
Depois que o modelo aprende como sentenças inteiras se relacionam com suas explicações, a equipe volta sua atenção aos caracteres individuais. Eles recortam dezenas de milhares de símbolos únicos diretamente dos manuscritos, preservando sua aparência irregular e desgastada pelo tempo. Paralelamente, constroem um “dicionário” de referência com imagens de caracteres retiradas de livros especializados, cada uma ligada a uma breve definição em chinês. Usando o codificador de imagem treinado, comparam cada caractere recortado do manuscrito com esse dicionário. Se uma imagem do manuscrito for extremamente semelhante a uma imagem do dicionário, ela é atribuída a essa categoria conhecida. Caso contrário, o sistema a trata como uma possível nova variante, adiciona sua representação de características ao conjunto de exemplos de referência e a sinaliza para verificação por especialistas. Essa “expansão de âncoras” dinâmica amplia gradualmente o alcance das formas reconhecidas e até descobre caracteres ausentes nos dicionários existentes.
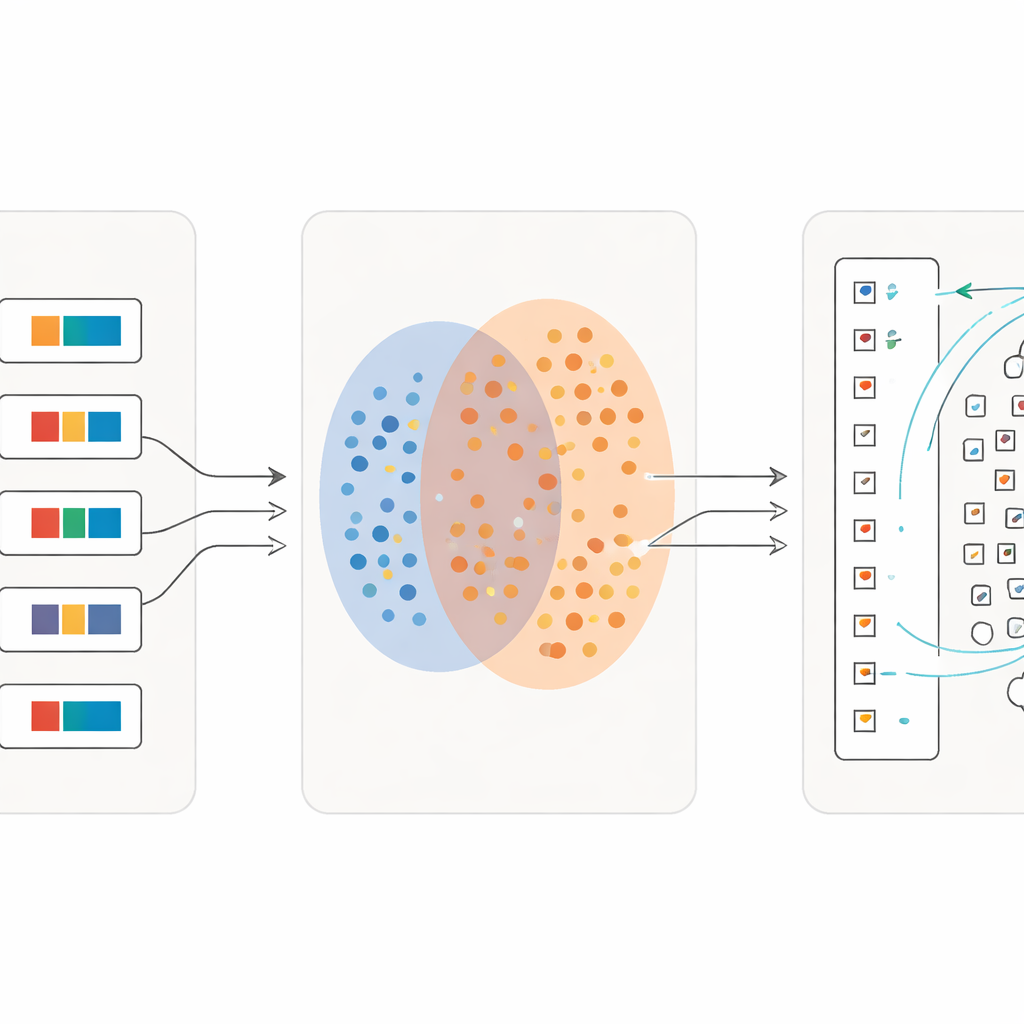
Aprendendo em detalhes cada vez mais finos
Uma inovação chave é que o processo não para após uma única passagem. Uma vez que uma primeira leva de caracteres foi correspondida de forma confiável, os pesquisadores transformam essas correspondências em novo material de treinamento: para cada símbolo único, eles criam uma frase descritiva curta usando seu significado do dicionário. Em seguida, reentram o modelo com uma mistura de sentenças completas e essas descrições de caracteres em nível fino. A cada iteração, o sistema torna‑se mais sensível a diferenças sutis entre sinais visualmente semelhantes, mantendo robustez frente à escrita descuidada. Ao longo de várias rodadas, a acurácia de classificação sobe de pouco mais da metade dos caracteres recuperados corretamente para mais de 97 por cento, mesmo para muitos símbolos raros com apenas alguns exemplares.
Um novo arquivo digital para o futuro
No final, a equipe produz o Dongba_1512, um conjunto de dados em grande escala com 705.058 imagens de caracteres únicos agrupadas em 1.512 categorias, todas extraídas de manuscritos históricos autênticos. A coleção inclui 252 caracteres que não aparecem em obras de referência atuais, oferecendo material novo para linguistas e historiadores. Sistemas modernos de reconhecimento de imagem treinados neste conjunto alcançam alta precisão, enquanto modelos treinados apenas em caligrafia artificial falham severamente ao serem confrontados com páginas reais. O estudo mostra que, ao permitir que imagens e significados se orientem mutuamente, a IA pode ajudar a resgatar escritas ameaçadas que carecem de anotações extensas, e a mesma estratégia pode ser adaptada a outras tradições pictográficas, como Shui e Yi. Em última análise, este trabalho transforma livros rituais frágeis em um recurso digital robusto para a herança cultural e a descoberta acadêmica.
Citação: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Palavras-chave: escrita Dongba, escrita antiga, preservação digital, modelos visão-linguagem, reconhecimento de caracteres