Clear Sky Science · fr
Un nouveau cadre d’apprentissage d’alignement cross-modal pour la construction d’un ensemble de données de caractères isolés Dongba
Sauvegarder un fossile vivant de l’écriture
L’écriture Dongba du peuple Naxi en Chine est souvent qualifiée de « fossile vivant » de l’écriture : c’est l’un des derniers systèmes pictographiques encore utilisés dans des manuscrits religieux. Pourtant, seuls quelques spécialistes rituels âgés savent le lire, et la plupart des textes survivants n’existent que sous forme de pages manuscrites fragiles. Cette étude présente une nouvelle méthode pilotée par l’intelligence artificielle pour transformer ces manuscrits vieillissants en une base de données riche et interrogeable de caractères individuels, contribuant à préserver une fenêtre unique sur l’histoire humaine.
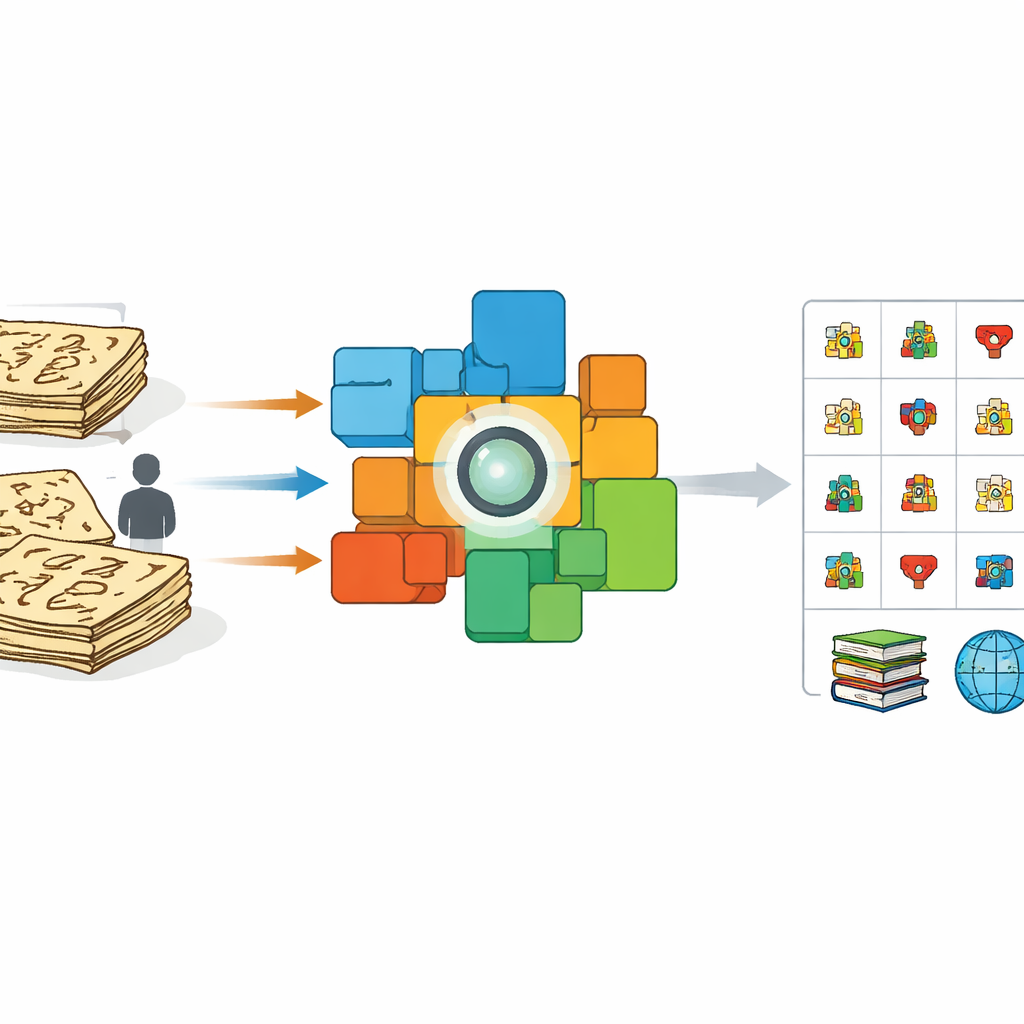
Pourquoi les images anciennes sont difficiles pour les ordinateurs
À première vue, apprendre à un ordinateur à lire le Dongba pourrait sembler identique à l’apprentissage de toute autre écriture manuscrite. Mais les efforts antérieurs reposaient surtout sur des volontaires recopiant des caractères avec des stylos modernes ou des tablettes, et sur des opérations automatiques d’« étirement » et de déformation de ces images propres. Ces imitations nettes paraissent très différentes des vrais caractères tracés au pinceau ou gravés dans des livres vieux de plusieurs siècles. La densité d’encre varie, les traits se cassent ou fusionnent, et les scribes improvisent des formes. En conséquence, les systèmes entraînés sur des échantillons artificiels fonctionnent mal sur des manuscrits réels, surtout face à des symboles rares ou jusqu’alors non documentés. Parallèlement, peu de spécialistes sont capables d’annoter des milliers de caractères à la main, créant un goulet d’étranglement pour la préservation.
Faire apprendre ensemble images et sens
Les auteurs adoptent une approche différente : plutôt que de demander aux experts d’annoter chaque caractère un par un, ils exploitent des pages complètes qui disposent déjà de traductions ligne par ligne en chinois moderne. À partir d’une édition savante de Dongba en 100 volumes, ils scannent des images de phrases et associent chacune à son explication correspondante. Ils affinent ensuite un puissant modèle vision‑langage connu sous le nom de CLIP de sorte que, dans un espace mathématique partagé, les images de phrases Dongba soient rapprochées de leurs traductions et éloignées de textes sans rapport. Cet entraînement cross‑modal incite l’encodeur d’images à se concentrer sur les détails visuels porteurs de sens et à ignorer les variations désordonnées de traits ou de mise en page.
Des pages entières aux signes individuels
Une fois que le modèle a appris comment des phrases entières se relient à leurs explications, l’équipe passe aux caractères isolés. Ils découpent des dizaines de milliers de symboles uniques directement à partir des manuscrits, en préservant leur apparence irrégulière et patinée par le temps. En parallèle, ils construisent un « dictionnaire » de référence d’images de caractères tirées d’ouvrages spécialisés, chacune liée à une courte définition en chinois. En utilisant l’encodeur d’images entraîné, ils comparent chaque caractère extrait des manuscrits à ce dictionnaire. Si une image de manuscrit est extrêmement similaire à une image du dictionnaire, elle est assignée à cette catégorie connue. Sinon, le système la traite comme une variante potentielle, ajoute sa représentation de caractéristiques au pool d’exemples de référence et la signale pour vérification experte. Cette « expansion d’ancres » dynamique élargit progressivement la gamme de formes reconnues et met même au jour des caractères absents des dictionnaires existants.
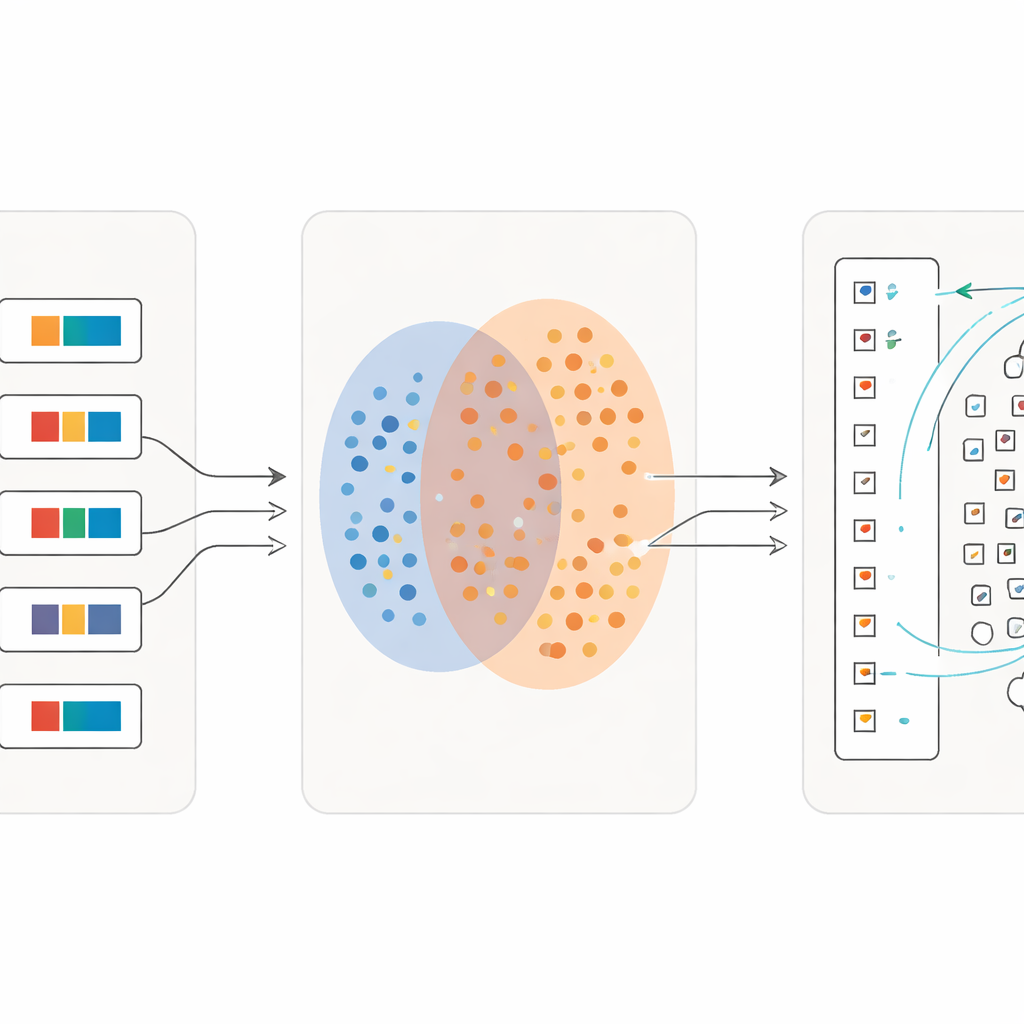
Apprendre avec des détails toujours plus fins
Une innovation clé est que le processus ne s’arrête pas après une seule passe. Une fois qu’une première vague de caractères a été appariée de manière fiable, les chercheurs transforment ces appariements en nouveau matériel d’entraînement : pour chaque symbole isolé, ils créent une courte phrase descriptive à partir de sa définition du dictionnaire. Ils réentraînent ensuite le modèle sur un mélange de phrases complètes et de ces descriptions fines de caractères. À chaque itération, le système devient plus sensible aux différences subtiles entre signes visuellement similaires tout en restant robuste face à une écriture approximative. Sur plusieurs cycles, la précision de classification passe d’un peu plus de la moitié des caractères correctement retrouvés à plus de 97 %, y compris pour de nombreux symboles rares disposant de seulement quelques exemples.
Une nouvelle archive numérique pour l’avenir
Au final, l’équipe produit Dongba_1512, un jeu de données à grande échelle de 705 058 images de caractères isolés regroupées en 1 512 catégories, toutes issues de manuscrits historiques authentiques. La collection comprend 252 caractères qui n’apparaissent pas dans les ouvrages de référence actuels, offrant un matériau inédit pour les linguistes et les historiens. Les systèmes modernes de reconnaissance d’images entraînés sur ce jeu de données atteignent une grande précision, tandis que les modèles entraînés uniquement sur des écritures artificielles échouent lourdement face à de véritables pages. L’étude montre qu’en laissant s’éclairer mutuellement images et sens, l’IA peut aider à sauver des écritures menacées qui manquent d’annotations étendues, et que la même stratégie peut être adaptée à d’autres traditions pictographiques comme le Shui et le Yi. En définitive, ce travail transforme des livres rituels fragiles en une ressource numérique robuste pour l’héritage culturel et la découverte savante.
Citation: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Mots-clés: écriture dongba, écriture ancienne, préservation numérique, modèles vision‑langage, reconnaissance de caractères