Clear Sky Science · it
Un nuovo framework di apprendimento per l’allineamento cross‑modale per la costruzione di un dataset di caratteri singoli Dongba
Salvare un fossile vivente della scrittura
La scrittura Dongba del popolo Naxi in Cina è spesso definita un «fossile vivente» della scrittura: è uno degli ultimi sistemi pittografici ancora impiegati nei manoscritti religiosi. Tuttavia solo un piccolo numero di anziani specialisti rituali è in grado di leggerla, e la maggior parte dei testi sopravvissuti esiste solo come fragili pagine manoscritte. Questo studio presenta un nuovo approccio guidato dall’intelligenza artificiale per trasformare quei manoscritti in un ricco database ricercabile di singoli caratteri, contribuendo a salvaguardare una finestra unica sulla storia umana.
Perché le immagini antiche sono difficili per i computer
A prima vista, insegnare a un computer a leggere il Dongba potrebbe sembrare simile a insegnargli a leggere qualsiasi altra scrittura a mano. Ma i tentativi precedenti si sono basati soprattutto su volontari che copiavano i caratteri con penne moderne o stilo e su una «distorsione» automatica di quelle immagini pulite. Queste imitazioni ordinate appaiono molto diverse dai veri segni tracciati a pennello o incisi nei libri secolari. La densità dell’inchiostro varia, i tratti si spezzano e si fondono, e gli scribi improvvisano le forme. Di conseguenza, i sistemi addestrati su campioni artificiali funzionano male sui manoscritti reali, specialmente quando incontrano simboli rari o non documentati. Allo stesso tempo, ci sono pochissimi specialisti in grado di etichettare manualmente migliaia di caratteri, creando un collo di bottiglia per la conservazione.
Lasciare che immagini e significati imparino insieme
Gli autori adottano un approccio diverso: invece di chiedere agli esperti di etichettare ogni carattere uno per uno, sfruttano pagine complete che già sono accompagnate da traduzioni cinesi riga per riga. Da un’edizione scientifica di 100 volumi dei testi Dongba, digitalizzano le immagini delle frasi e le associano alle corrispondenti spiegazioni moderne. Quindi mettono a punto un potente modello visione‑linguaggio noto come CLIP in modo che, in uno spazio matematico condiviso, le immagini delle frasi Dongba vengano avvicinate alle loro traduzioni e allontanate da testi non correlati. Questo addestramento cross‑modale spinge l’encoder delle immagini a concentrarsi sui dettagli visivi portatori di significato e a ignorare le variazioni disordinate nei tratti del pennello o nell’impaginazione.
Dalle pagine intere ai segni individuali
Una volta che il modello ha imparato come intere frasi si relazionano alle loro spiegazioni, il team passa ai singoli caratteri. Ritagliano decine di migliaia di simboli singoli direttamente dai manoscritti, preservandone l’aspetto irregolare e segnato dal tempo. Parallelamente, costruiscono un «dizionario» di riferimento composto da immagini di caratteri tratte da libri specialistici, ognuna collegata a una breve definizione in cinese. Usando l’encoder delle immagini addestrato, confrontano ogni carattere ritagliato dal manoscritto con questo dizionario. Se un’immagine del manoscritto è estremamente simile a un’immagine del dizionario, le viene assegnata quella categoria nota. Altrimenti, il sistema la tratta come una possibile nuova variante, aggiunge la sua rappresentazione alle esempi di riferimento e la segnala per la verifica da parte di esperti. Questa «espansione di ancore» dinamica amplia gradualmente la gamma di forme riconosciute e porta persino alla scoperta di caratteri assenti nei dizionari esistenti.
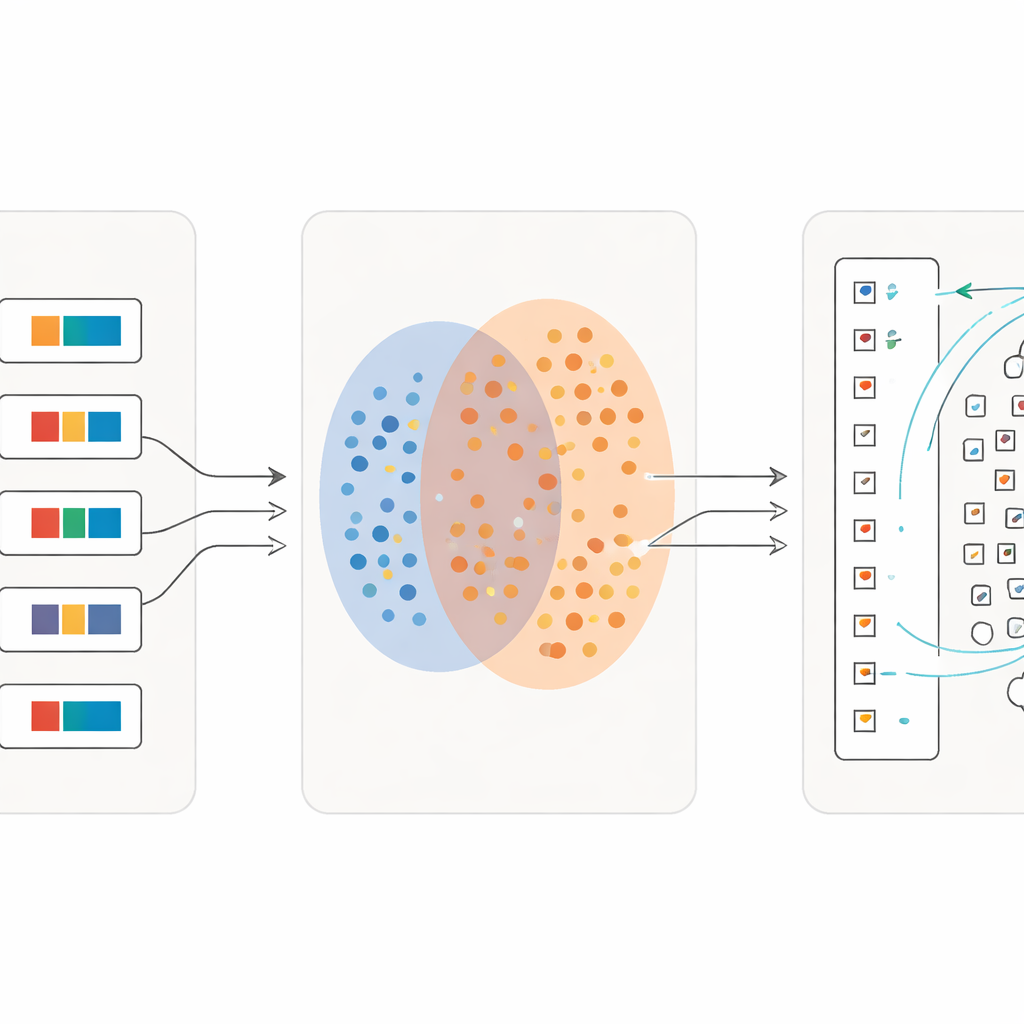
Apprendere in dettagli sempre più fini
Un’innovazione chiave è che il processo non si ferma dopo una sola iterazione. Una volta che una prima ondata di caratteri è stata abbinata con affidabilità, i ricercatori trasformano queste corrispondenze in nuovo materiale di addestramento: per ogni simbolo singolo creano una breve frase descrittiva usando il suo significato nel dizionario. Poi riaddestrano il modello su una miscela di frasi complete e queste descrizioni di caratteri a gran dettaglio. Ad ogni iterazione, il sistema diventa più sensibile alle sottili differenze tra segni visivamente simili pur restando robusto verso una scrittura imprecisa. Nel corso di più cicli, l’accuratezza di classificazione sale da poco più della metà dei caratteri correttamente recuperati a oltre il 97 percento, anche per molti simboli rari con solo pochi esempi.
Un nuovo archivio digitale per il futuro
Alla fine, il team produce Dongba_1512, un dataset su larga scala di 705.058 immagini di singoli caratteri raggruppate in 1.512 categorie, tutte tratte da manoscritti storici autentici. La collezione include 252 caratteri che non compaiono nelle opere di riferimento attuali, offrendo nuovo materiale per linguisti e storici. I moderni sistemi di riconoscimento delle immagini addestrati su questo dataset raggiungono alta accuratezza, mentre i modelli addestrati solo su scritture artificiali falliscono clamorosamente quando si trovano di fronte a pagine reali. Lo studio dimostra che lasciando che immagini e significati si guidino a vicenda, l’IA può contribuire a salvare scritture in pericolo che mancano di estese annotazioni, e la stessa strategia può essere adattata ad altre tradizioni pittografiche come Shui e Yi. In definitiva, questo lavoro trasforma fragili libri rituali in una solida risorsa digitale per l’eredità culturale e la scoperta accademica.
Citazione: Xing, J., Bi, X. & Qiao, W. A novel cross-modal alignment learning framework for Dongba single-character dataset construction. npj Herit. Sci. 14, 208 (2026). https://doi.org/10.1038/s40494-026-02494-8
Parole chiave: scrittura Dongba, scrittura antica, conservazione digitale, modelli visione‑linguaggio, riconoscimento dei caratteri