Clear Sky Science · sv
Generativa adversariella nätverk för högkvalitativ komplettering av 3D-punktmoln
Varför det spelar roll att fylla i 3D-gap
Många av de tekniker som förändrar vardagslivet—från självkörande bilar till hemrobotar och virtuell verklighet—är beroende av en detaljerad 3D-förståelse av omvärlden. Dessa system använder ofta sensorer som samlar miljontals punkter i rummet för att beskriva föremål och rum. I praktiken är sådana ”punktmoln” dock fulla av luckor på grund av ocklusioner, blanka ytor eller begränsade vyer. Denna artikel presenterar ett nytt sätt att intelligent fylla igen dessa luckor, genom att använda en typ av artificiell intelligens kallad generativt adversariellt nätverk (GAN) för att rekonstruera saknade 3D-strukturer även när mer än halva datan saknas.
Se former från spridda prickar
Ett 3D-punktmoln är som en stjärnbild av prickar som skissar ytan på ett objekt eller en scen. Laserskannrar och djupkameror har gjort det enkelt att fånga sådan data, men verkliga mätningar är sällan kompletta. Traditionella reparationsmetoder förlitar sig på lokala knep, som att jämna ut närliggande ytor eller interpolera mellan närliggande punkter, och de fungerar bäst när hålen är små. Nyare metoder med djupinlärning förbättrar detta genom att lära sig formmönster, men de behöver vanligtvis noggrant förberedda träningspar som visar både den skadade och den fullständiga versionen av varje objekt. Detta krav är svårt att uppfylla utanför noga kurerade forskningsdataset och begränsar prestandan när hela delar av ett objekt—som bilens kaross eller en stolens ben—saknas.
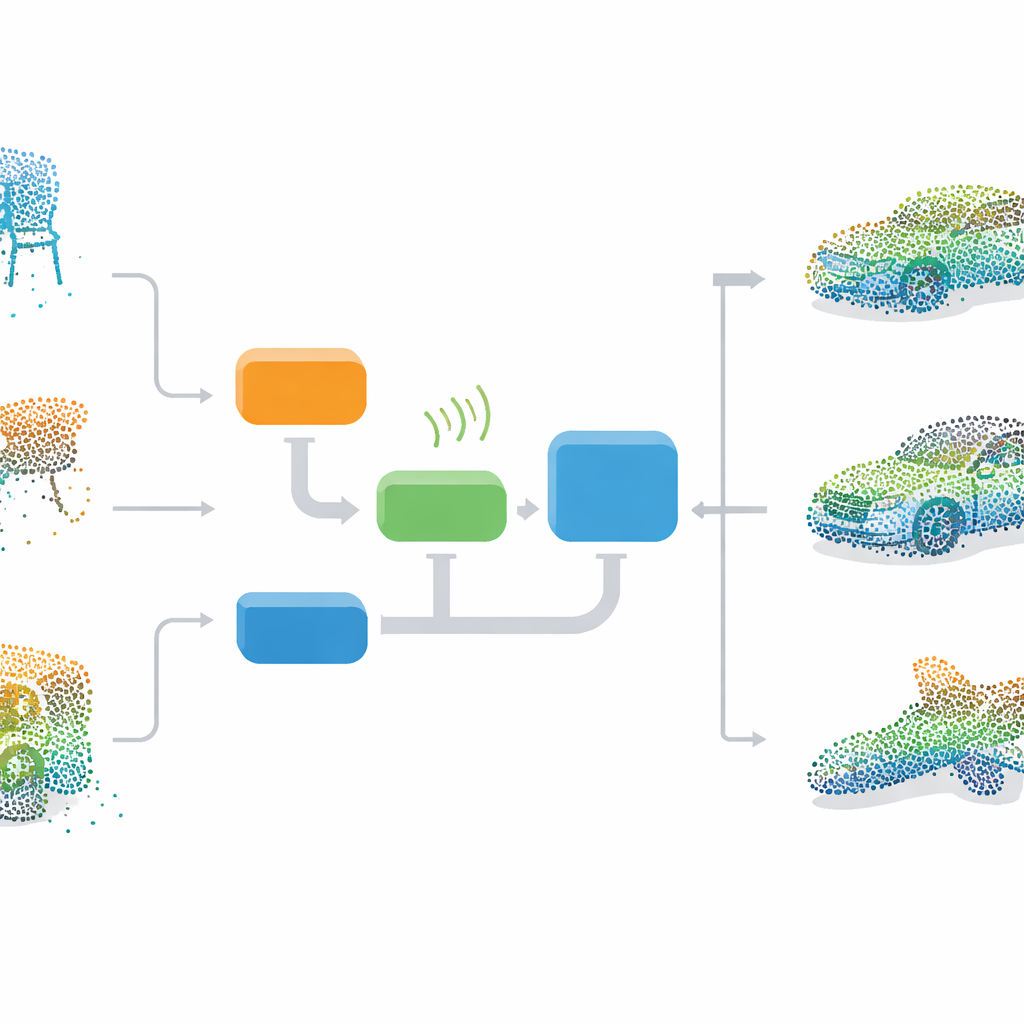
Lära en 3D-föreställningsförmåga
Författarna föreslår ett helintegrerat ramverk som lär ett neuralt nätverk att föreställa sig kompletta 3D-objekt från grunden och sedan använder den föreställningen för att reparera skadade punktmoln. I kärnan finns ett GAN, en tvådelad modell där en generator lär sig skapa realistiska 3D-punktmoln medan en discriminator lär sig skilja verkliga former från förfalskningar. Under träningen börjar generatorn från slumpmässigt brus och lär sig successivt de övergripande fördelningarna för stolar, sängar, bilar och andra objekt i ett standarddataset kallat ModelNet40. Eftersom den lär sig endast från fullständiga exempel behöver metoden inte prydligt matchade par av ofullständig och komplett data, vilket gör den mer praktisk för användning i verkliga miljöer.
Hur systemet fyller luckorna
För att reparera ett trasigt punktmoln passerar systemet först den ofullständiga datan genom en kompakt encoder som destillerar dess övergripande form till en kort funktionsvektor. Denna vektor spelar samma roll som det brus som användes under träningen och matas in i den tränade generatorn, som producerar en rimlig komplett version av objektet, inklusive geometri och ytans orienteringsinformation. Metoden fusionerar sedan de genererade punkterna med de ursprungliga mätningarna, kombinerar vad som faktiskt observerades med nätverkets bästa gissning för de saknade delarna. Ett sista städsteg tar bort avvikande punkter med en närmsta granne-kontroll och återprovtar sedan resultatet så att prickarna fördelas jämnt, vilket ger en prydlig, enhetlig 3D-modell redo för efterföljande uppgifter.
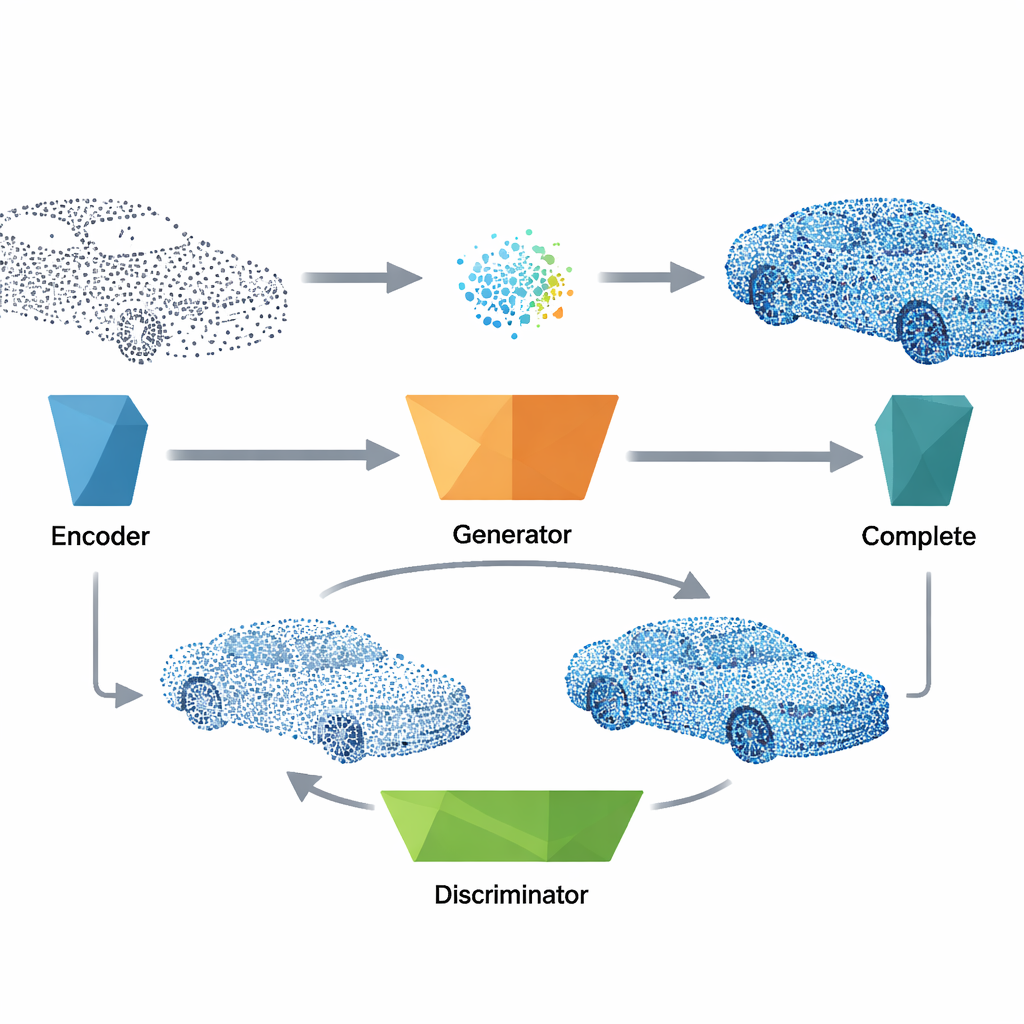
Balans mellan realism, detalj och effektivitet
För att göra rekonstruktionerna både globalt sammanhängande och lokalt släta designar författarna ett flerparts träningsmål. Förutom den centrala adversariella signalen som pressar generatorn att lura discriminatoren, introducerar de termer som belönar konsekventa ytriktningar, god anpassning av genererade punkter till verkliga former och naturligt lokalt avstånd mellan närliggande punkter. En effektiv axeljusterad sökstrategi håller dessa lokala kontroller snabba även för stora punktmängder. Experiment visar att denna kombination av förluster är avgörande för stabil inlärning: att ta bort någon av dem skadar antingen den övergripande formen eller finare detaljer. Trots denna sofistikering är den slutliga modellen lättviktig och kör i bråkdelar av en sekund på modern hårdvara, vilket gör den lämpad för nästan realtidsapplikationer.
Från laboratoriebenchmarks till verkliga scener
På ModelNet40-benchmarken överträffar den föreslagna metoden både klassiska geometri-baserade algoritmer och flera ledande djupinlärningsmetoder över standardfelmått. Den rekonstruerar bilar, stolar och sängar med högre trohet, särskilt när mer än hälften av de ursprungliga punkterna saknas. Visuella jämförelser visar att metoden återställer viktiga strukturella komponenter—som biltak och stolryggar—som andra metoder ofta missar. Författarna testar också systemet på verkliga inomhusskanningar och simulerade körscener, där ocklusioner och brus är betydligt värre än i rena dataset. I båda miljöerna ger de kompletterade punktmolnen mer exakta 3D-kartor och stödjer bättre banplanering: med den ifyllda geometrin kan planeringsalgoritmer förutsäga dolda hinder och välja jämnare, säkrare rutter.
En tydligare bild av 3D-världar
Sammanfattningsvis visar detta arbete att ett omsorgsfullt utformat GAN kan lära sig en stark 3D-prior och använda den för att komplettera kraftigt skadade punktmoln utan att förlita sig på parade träningsdata. Genom att kombinera en enkel encoder, en kraftfull generator, en krävande discriminator och en genomtänkt förlustfunktion producerar systemet kompletta, släta och strukturellt hållbara 3D-former från glesa och brusiga ingångar. För icke-experter är huvudbudskapet att algoritmer nu kan ”gissa” saknad 3D-information på ett sätt som både är realistiskt och praktiskt, och därigenom hjälpa robotar, fordon och VR-system att se en mer fullständig bild av världen omkring dem.
Citering: Zhao, D., Mao, S., Shao, J. et al. Generative adversarial networks for high-fidelity 3D point cloud completion. Sci Rep 16, 14076 (2026). https://doi.org/10.1038/s41598-026-44111-5
Nyckelord: 3D-punktmoln, formsfyllnad, generativa adversariella nätverk, autonom navigering, robotperception