Clear Sky Science · pt
Redes adversariais generativas para completude de nuvens de pontos 3D com alta fidelidade
Por que preencher lacunas 3D é importante
Muitas das tecnologias que transformam o dia a dia — desde carros autônomos até robôs domésticos e realidade virtual — dependem de uma compreensão 3D detalhada do mundo. Esses sistemas costumam usar sensores que coletam milhões de pontos no espaço para delinear objetos e ambientes. Mas, na prática, essas “nuvens de pontos” estão cheias de lacunas devido a oclusões, superfícies reflexivas ou pontos de vista limitados. Este artigo apresenta uma nova maneira de preencher essas lacunas de forma inteligente, usando um tipo de inteligência artificial chamado rede adversarial generativa (GAN) para reconstruir estruturas 3D faltantes mesmo quando mais da metade dos dados está ausente.
Ver formas a partir de pontos dispersos
Uma nuvem de pontos 3D assemelha-se a uma constelação de pontos que contorna a superfície de um objeto ou cena. Scanners a laser e câmeras de profundidade tornaram mais fácil capturar esses dados, mas medições do mundo real raramente são completas. Métodos de reparo tradicionais dependem de artifícios locais, como suavizar superfícies próximas ou interpolar entre pontos vizinhos, e funcionam melhor quando só há pequenos buracos. Métodos de aprendizado profundo mais recentes melhoram isso ao aprender padrões de forma, mas geralmente exigem pares de treinamento cuidadosamente preparados que mostram tanto a versão danificada quanto a versão totalmente intacta de cada objeto. Essa exigência é difícil de satisfazer fora de conjuntos de dados curados para pesquisa e limita o desempenho quando se perdem seções inteiras de um objeto — como a carroceria de um carro ou as pernas de uma cadeira.
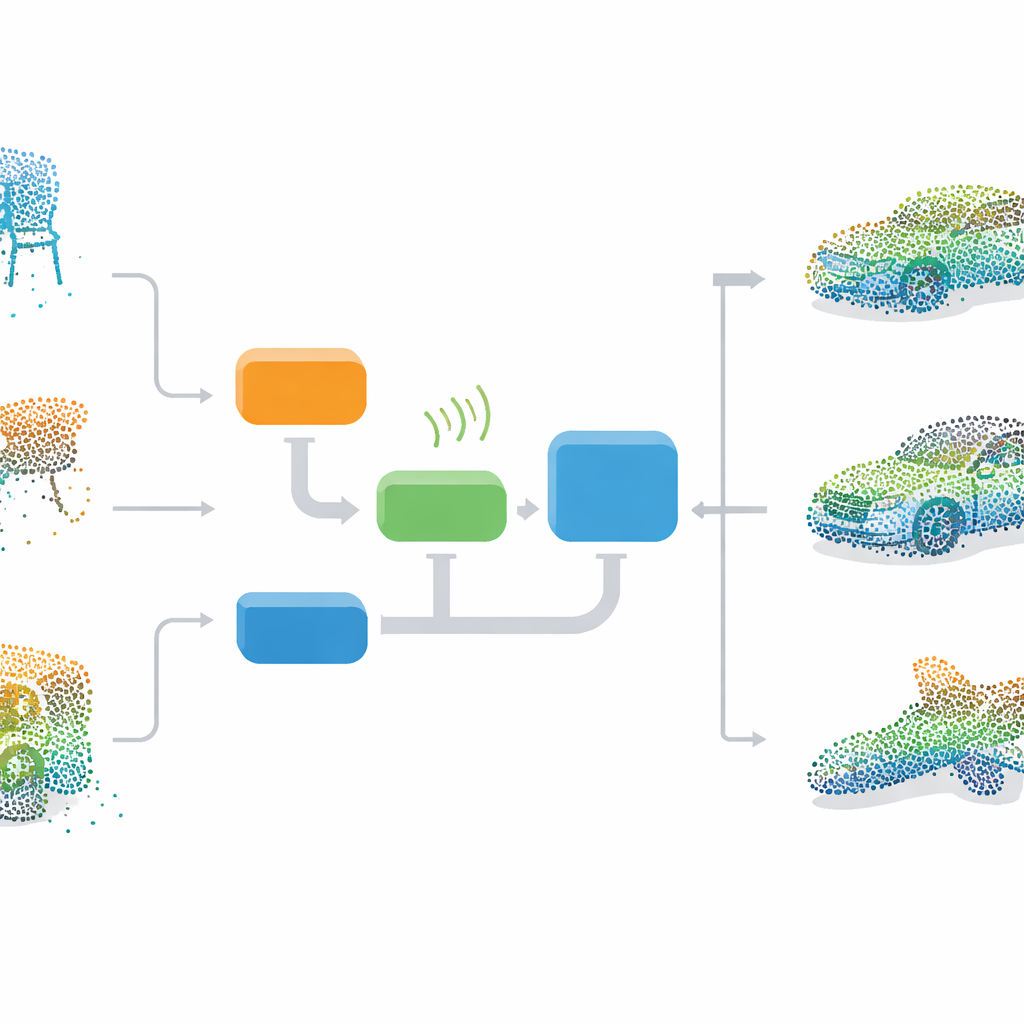
Ensinando uma imaginação 3D
Os autores propõem uma estrutura de ponta a ponta que ensina uma rede neural a imaginar objetos 3D completos do zero e, em seguida, usa essa imaginação para reparar nuvens de pontos danificadas. No núcleo está uma GAN, um modelo de duas partes em que um gerador aprende a criar nuvens de pontos 3D realistas enquanto um discriminador aprende a distinguir formas reais de falsificações. Durante o treinamento, o gerador parte de ruído aleatório e gradualmente aprende as distribuições gerais de cadeiras, camas, carros e outros objetos em um conjunto de dados padrão chamado ModelNet40. Como aprende apenas a partir de exemplos completos, o método não precisa de pares ordenados de dados incompletos e completos, tornando-o mais prático para uso no mundo real.
Como o sistema preenche as lacunas
Para reparar uma nuvem de pontos danificada, o sistema primeiro passa os dados incompletos por um codificador compacto que destila sua forma geral em um vetor de características curto. Esse vetor desempenha o mesmo papel do ruído usado durante o treinamento e é alimentado no gerador treinado, que produz uma versão plausível e completa do objeto, incluindo geometria e informações de orientação de superfície. O método então funde os pontos gerados com as medições originais, combinando o que foi realmente observado com a melhor suposição da rede para as partes faltantes. Uma etapa final de limpeza remove pontos discrepantes usando uma verificação de vizinho mais próximo e, em seguida, reamostra o resultado para que os pontos fiquem distribuídos de forma uniforme, produzindo um modelo 3D limpo e homogêneo pronto para tarefas posteriores.
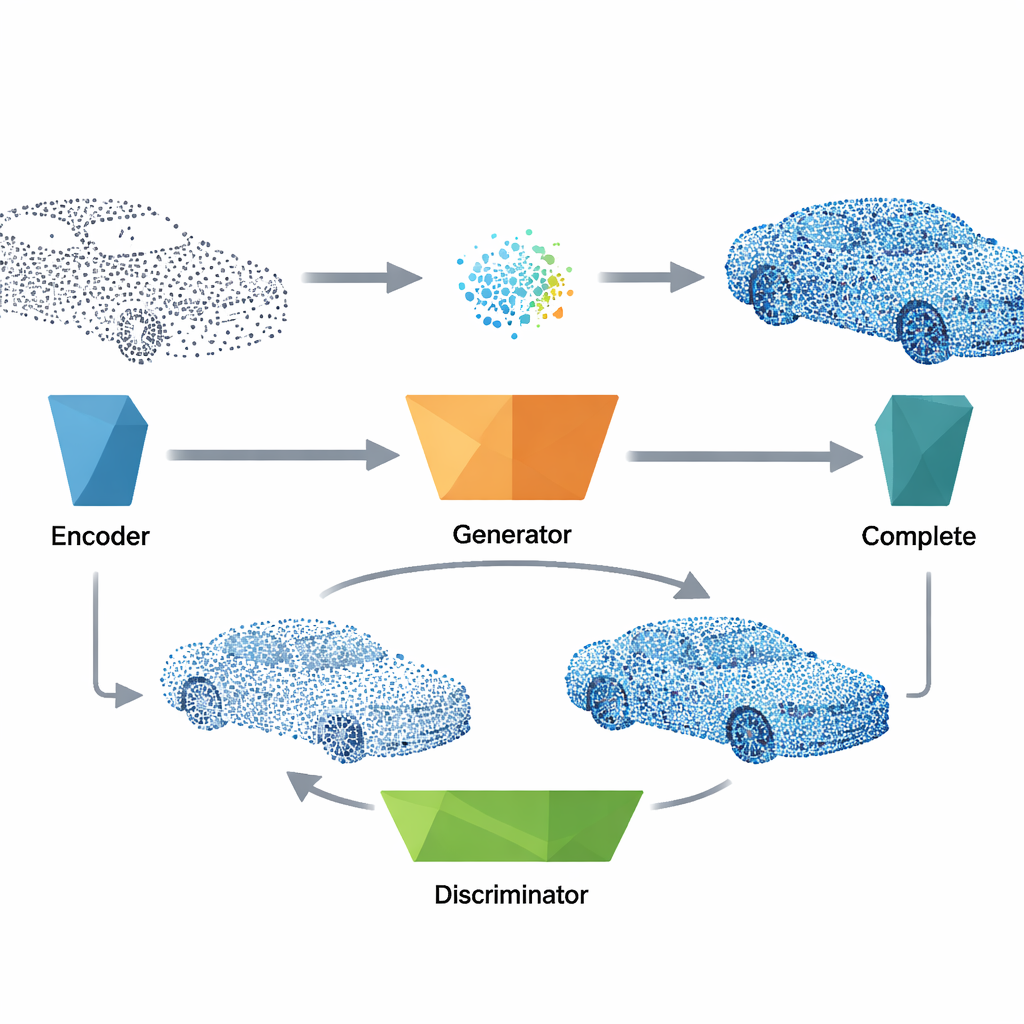
Equilibrando realismo, detalhe e eficiência
Para tornar as reconstruções ao mesmo tempo coerentes globalmente e suaves localmente, os autores projetam um objetivo de treinamento composto. Além do sinal adversarial central que força o gerador a enganar o discriminador, eles introduzem termos que recompensam direções de superfície consistentes, bom alinhamento dos pontos gerados com as formas reais e espaçamento local natural entre pontos vizinhos. Uma estratégia de busca eficiente alinhada aos eixos mantém essas verificações locais rápidas mesmo para grandes conjuntos de pontos. Experimentos mostram que essa combinação de perdas é crucial para um aprendizado estável: remover qualquer uma delas prejudica ou a forma geral ou os detalhes finos. Apesar dessa sofisticação, o modelo final é leve, executando em frações de segundo em hardware moderno, o que o torna adequado para aplicações quase em tempo real.
De benchmarks de laboratório a cenas do mundo real
No benchmark ModelNet40, a abordagem proposta supera tanto algoritmos clássicos baseados em geometria quanto vários métodos de ponta em aprendizado profundo nas medidas de erro padrão. Reconstrói carros, cadeiras e camas com maior fidelidade, especialmente quando mais da metade dos pontos originais está faltando. Comparações visuais revelam que o método restaura componentes estruturais-chave — como tetos de carros e encostos de cadeiras — que outros métodos frequentemente perdem. Os autores também testam o sistema em varreduras internas reais e cenas simuladas de direção, onde as oclusões e o ruído são muito mais severos do que em conjuntos de dados limpos. Em ambos os cenários, as nuvens de pontos completadas produzem mapas 3D mais precisos e suportam melhor o planejamento de trajetórias: com a geometria preenchida, os algoritmos de planejamento conseguem prever obstáculos ocultos e escolher rotas mais suaves e seguras.
Uma imagem mais clara dos mundos 3D
Em resumo, este trabalho mostra que uma GAN cuidadosamente projetada pode aprender um forte prior 3D e usá-lo para completar nuvens de pontos fortemente danificadas sem depender de dados de treinamento pareados. Ao combinar um codificador simples, um gerador poderoso, um discriminador criterioso e uma função de perda bem concebida, o sistema produz formas 3D completas, suaves e estruturalmente sólidas a partir de entradas esparsas e ruidosas. Para não especialistas, a mensagem principal é que algoritmos agora podem “adivinhar” informações 3D faltantes de uma forma que é ao mesmo tempo realista e prática, ajudando robôs, veículos e sistemas de realidade virtual a verem uma imagem mais completa do mundo ao seu redor.
Citação: Zhao, D., Mao, S., Shao, J. et al. Generative adversarial networks for high-fidelity 3D point cloud completion. Sci Rep 16, 14076 (2026). https://doi.org/10.1038/s41598-026-44111-5
Palavras-chave: Nuvens de pontos 3D, completação de forma, redes adversariais generativas, navegação autônoma, percepção robótica