Clear Sky Science · es
Redes generativas antagónicas para la completación de nubes de puntos 3D de alta fidelidad
Por qué importa rellenar huecos en 3D
Muchas de las tecnologías que están transformando la vida cotidiana —desde coches autónomos hasta robots domésticos y realidad virtual— dependen de una comprensión 3D detallada del entorno. Estos sistemas suelen usar sensores que recogen millones de puntos en el espacio para perfilar objetos y habitaciones. Pero en la práctica, esas “nubes de puntos” están llenas de huecos debido a oclusiones, superficies reflectantes o puntos de vista limitados. Este artículo presenta una nueva manera de rellenar esos huecos de forma inteligente, usando un tipo de inteligencia artificial llamada red generativa antagónica (GAN) para reconstruir estructuras 3D faltantes incluso cuando más de la mitad de los datos se ha perdido.
Ver formas a partir de puntos dispersos
Una nube de puntos 3D es como una constelación de puntos que dibujan la superficie de un objeto o una escena. Los escáneres láser y las cámaras de profundidad han facilitado la captura de este tipo de datos, pero las mediciones del mundo real rara vez están completas. Los métodos tradicionales de reparación se basan en trucos locales, como suavizar superficies cercanas o interpolar entre puntos vecinos, y funcionan mejor cuando sólo hay pequeños agujeros. Métodos más recientes de aprendizaje profundo mejoran esto aprendiendo patrones de forma, pero normalmente requieren pares de entrenamiento cuidadosamente preparados que muestren tanto la versión dañada como la íntegra de cada objeto. Este requisito es difícil de cumplir fuera de conjuntos de datos de investigación curados y limita el rendimiento cuando faltan secciones enteras de un objeto —como la carrocería de un coche o las patas de una silla—.
Enseñar una imaginación 3D
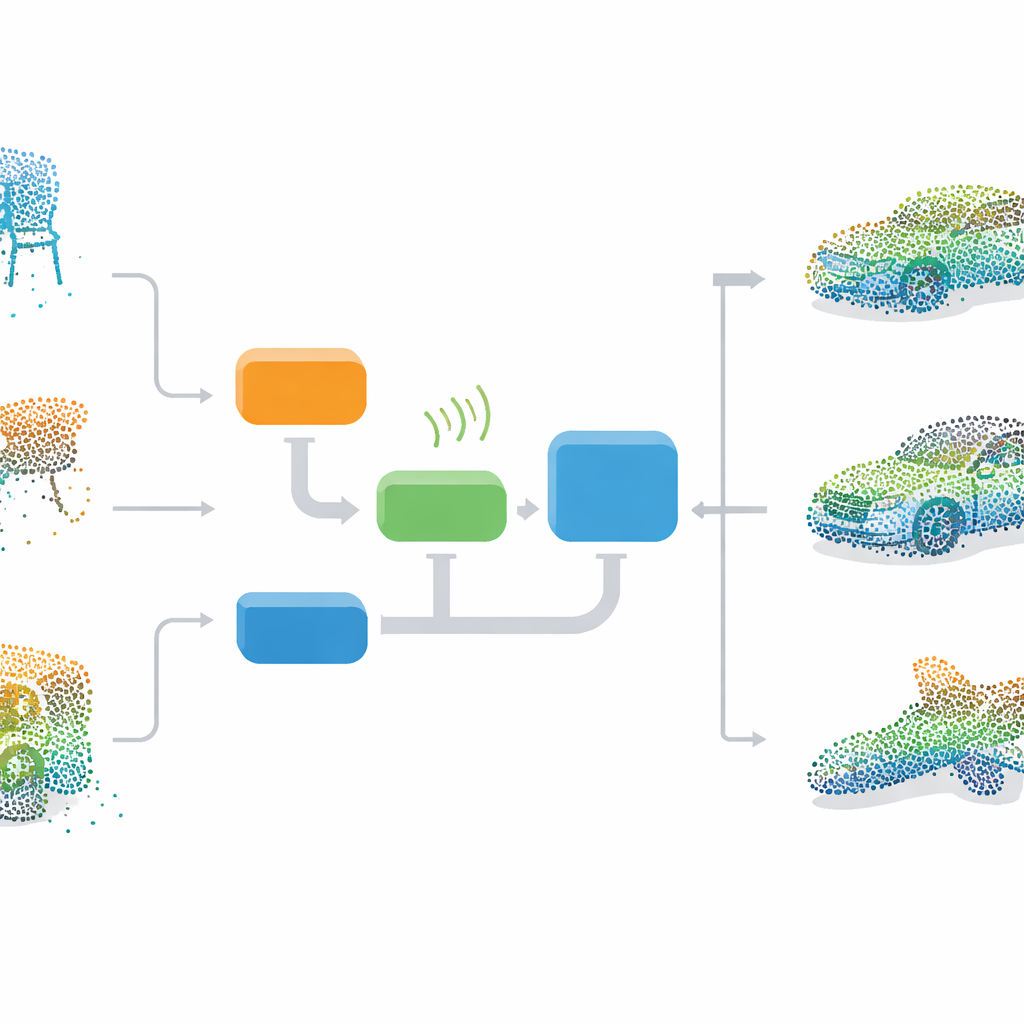
Los autores proponen un marco de extremo a extremo que enseña a una red neuronal a imaginar objetos 3D completos desde cero y luego usar esa imaginación para reparar nubes de puntos dañadas. En su núcleo está una GAN, un modelo de dos partes en el que un generador aprende a crear nubes de puntos 3D realistas mientras un discriminador aprende a distinguir formas reales de las falsas. Durante el entrenamiento, el generador parte de ruido aleatorio y aprende gradualmente las distribuciones generales de sillas, camas, coches y otros objetos en un conjunto de datos estándar llamado ModelNet40. Debido a que aprende solo a partir de ejemplos completos, el método no necesita pares perfectamente emparejados de datos incompletos y completos, lo que lo hace más práctico para uso en el mundo real.
Cómo el sistema rellena los huecos
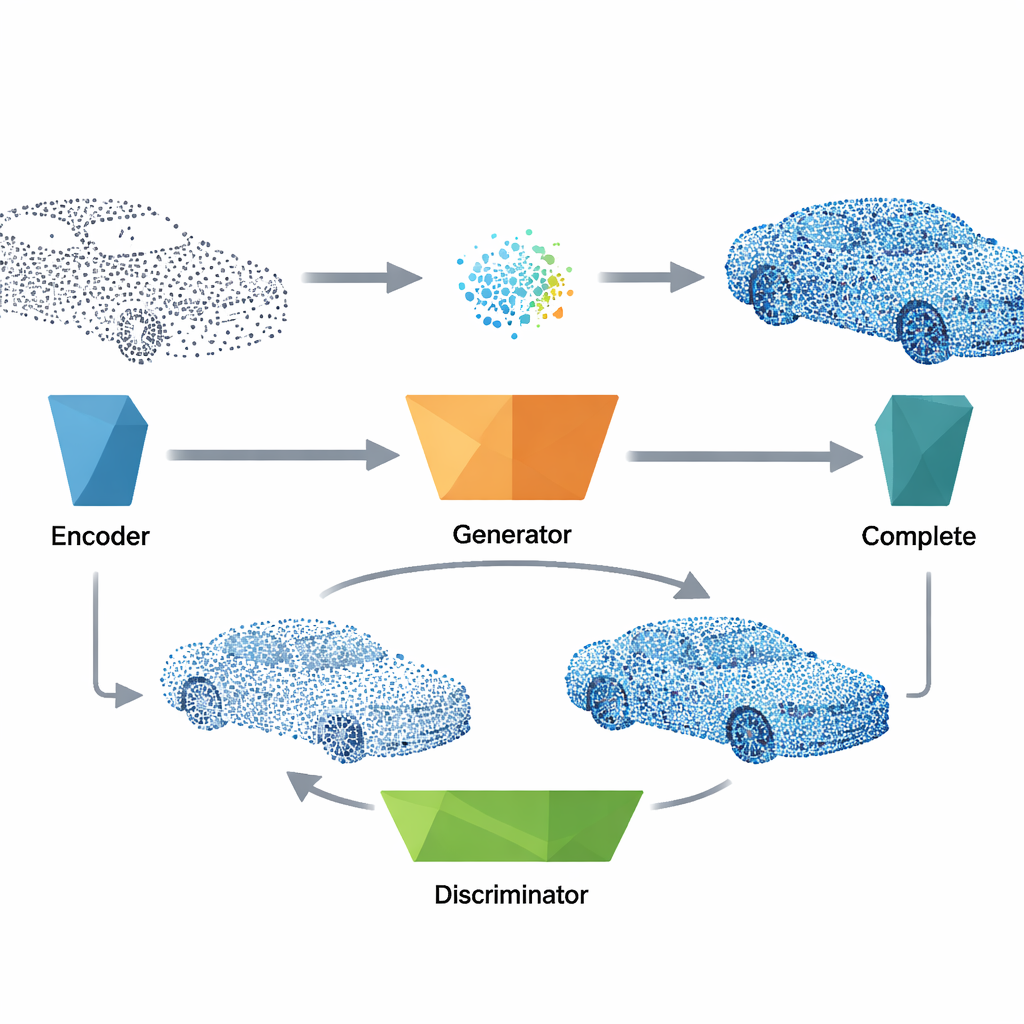
Para reparar una nube de puntos rota, el sistema primero pasa los datos incompletos por un codificador compacto que destila su forma global en un vector de características breve. Este vector desempeña el mismo papel que el ruido usado durante el entrenamiento y se introduce en el generador entrenado, que produce una versión completa plausible del objeto, incluyendo la geometría y la orientación de la superficie. El método fusiona luego los puntos generados con las mediciones originales, combinando lo que se observó realmente con la mejor conjetura de la red para las partes faltantes. Un paso final de limpieza elimina puntos atípicos mediante una comprobación de vecinos más cercanos y, a continuación, vuelve a muestrear el resultado para que los puntos queden distribuidos de forma uniforme, generando un modelo 3D ordenado y homogéneo listo para tareas posteriores.
Equilibrar realismo, detalle y eficiencia
Para que las reconstrucciones sean coherentes a escala global y suaves a escala local, los autores diseñan un objetivo de entrenamiento multipartito. Además de la señal adversarial central que empuja al generador a engañar al discriminador, introducen términos que recompensan direcciones de superficie consistentes, buena alineación de los puntos generados con las formas reales y un espaciado local natural entre puntos vecinos. Una estrategia de búsqueda eficiente alineada con los ejes mantiene estas comprobaciones locales rápidas incluso para grandes conjuntos de puntos. Los experimentos muestran que esta combinación de pérdidas es crucial para un aprendizaje estable: eliminar cualquiera de ellas perjudica ya sea la forma global o los detalles finos. A pesar de esta sofisticación, el modelo final es ligero y funciona en fracciones de segundo en hardware moderno, lo que lo hace adecuado para aplicaciones casi en tiempo real.
De los benchmarks de laboratorio a escenas del mundo real
En el benchmark ModelNet40, el enfoque propuesto supera tanto a algoritmos clásicos basados en geometría como a varios métodos de aprendizaje profundo líderes según medidas de error estándar. Reconstruye coches, sillas y camas con mayor fidelidad, especialmente cuando más de la mitad de los puntos originales faltan. Comparaciones visuales revelan que el método restaura componentes estructurales clave —como los techos de los coches y los respaldos de las sillas— que otros métodos suelen pasar por alto. Los autores también prueban el sistema en escaneos interiores reales y en escenas de conducción simulada, donde las oclusiones y el ruido son mucho más severos que en conjuntos de datos limpios. En ambos entornos, las nubes de puntos completadas producen mapas 3D más precisos y permiten una mejor planificación de rutas: con la geometría rellenada, los algoritmos de planificación pueden predecir obstáculos ocultos y elegir trayectorias más suaves y seguras.
Una imagen más clara de los mundos 3D
En resumen, este trabajo muestra que una GAN cuidadosamente diseñada puede aprender una prior 3D potente y usarla para completar nubes de puntos muy dañadas sin depender de datos de entrenamiento pareados. Al combinar un codificador simple, un generador poderoso, un discriminador perspicaz y una función de pérdida bien pensada, el sistema produce formas 3D completas, suaves y estructuralmente sólidas a partir de entradas escasas y ruidosas. Para el público no experto, el mensaje clave es que los algoritmos ahora pueden “adivinar” información 3D faltante de una manera que es a la vez realista y práctica, ayudando a robots, vehículos y sistemas de realidad virtual a ver una imagen más completa del mundo que les rodea.
Cita: Zhao, D., Mao, S., Shao, J. et al. Generative adversarial networks for high-fidelity 3D point cloud completion. Sci Rep 16, 14076 (2026). https://doi.org/10.1038/s41598-026-44111-5
Palabras clave: Nubes de puntos 3D, completado de formas, redes generativas antagónicas, navegación autónoma, percepción robótica