Clear Sky Science · de
Generative adversariale Netze zur hochauflösenden Vervollständigung von 3D-Punktwolken
Warum das Schließen von 3D-Lücken wichtig ist
Viele der Technologien, die unseren Alltag verändern – von selbstfahrenden Autos über Haushaltsroboter bis hin zu Virtual Reality – basieren auf einem detaillierten 3D-Verständnis der Umgebung. Diese Systeme nutzen häufig Sensoren, die Millionen von Punkten im Raum erfassen, um Objekte und Räume abzubilden. In der Praxis sind solche „Punktwolken“ jedoch voller Lücken, verursacht durch Verdeckungen, spiegelnde Oberflächen oder begrenzte Blickwinkel. Dieses Paper stellt eine neue Methode vor, um solche Lücken intelligent zu füllen: Ein spezieller Typ künstlicher Intelligenz, ein generatives adversariales Netz (GAN), rekonstruiert fehlende 3D-Strukturen selbst dann, wenn mehr als die Hälfte der Daten fehlt.
Formen aus verstreuten Punkten erkennen
Eine 3D-Punktwolke ähnelt einer Sternkarte aus Punkten, die die Oberfläche eines Objekts oder einer Szene skizzieren. Laserscanner und Tiefenkameras haben das Erfassen solcher Daten vereinfacht, doch reale Messungen sind selten vollständig. Traditionelle Reparaturmethoden setzen auf lokale Tricks wie das Glätten benachbarter Flächen oder die Interpolation zwischen Punkten und funktionieren am besten bei kleinen Löchern. Neuere Deep-Learning-Methoden lernen zwar Formmuster, benötigen aber meist sorgfältig vorbereitete Trainingspaare, die sowohl die beschädigte als auch die vollständige Version jedes Objekts zeigen. Diese Voraussetzung ist außerhalb kuratierter Forschungsdatensätze schwer zu erfüllen und limitiert die Leistung, wenn ganze Bereiche eines Objekts – etwa die Karosserie eines Autos oder die Beine eines Stuhls – fehlen.
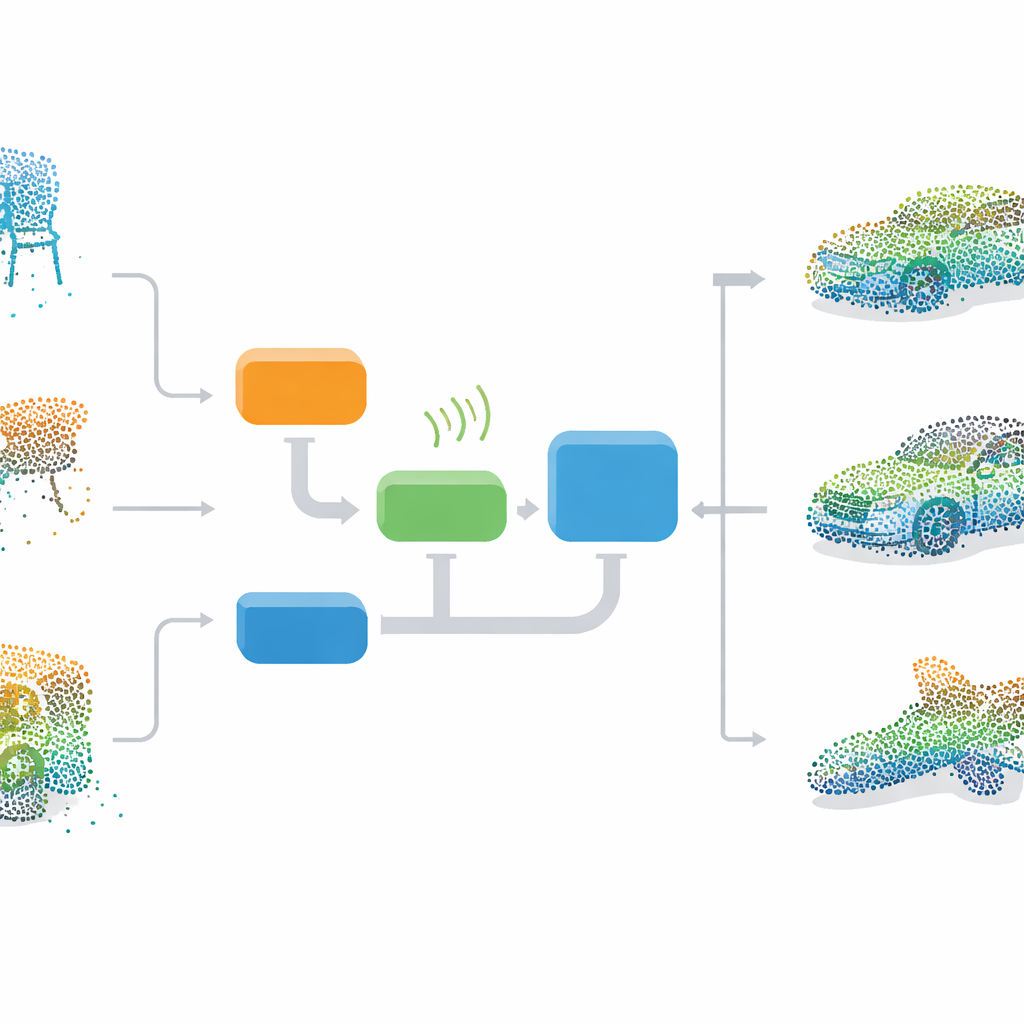
Eine 3D-Vorstellung beibringen
Die Autoren schlagen einen End-to-End-Ansatz vor, der ein neuronales Netz darin schult, komplette 3D-Objekte „aus der Vorstellung heraus“ zu erzeugen, und diese Vorstellung dann zur Reparatur beschädigter Punktwolken nutzt. Im Zentrum steht ein GAN, ein zweiteiliges Modell, bei dem ein Generator lernt, realistische 3D-Punktwolken zu erzeugen, während ein Diskriminator echte Formen von künstlichen unterscheidet. Während des Trainings startet der Generator aus Zufallsrauschen und lernt schrittweise die Verteilungen von Stühlen, Betten, Autos und anderen Objekten eines Standarddatensatzes namens ModelNet40. Da das Modell nur aus vollständigen Beispielen lernt, benötigt die Methode keine sorgfältig abgestimmten Paare aus unvollständigen und kompletten Daten und ist damit praxisnäher für Anwendungen außerhalb idealisierter Datensätze.
Wie das System die Lücken füllt
Um eine beschädigte Punktwolke zu reparieren, leitet das System zunächst die unvollständigen Daten durch einen kompakten Encoder, der die Gesamtform in einen kurzen Merkmalsvektor destilliert. Dieser Vektor übernimmt dieselbe Rolle wie das Rauschen während des Trainings und wird in den trainierten Generator eingespeist, der eine plausible, vollständige Version des Objekts erzeugt, inklusive Geometrie und Oberflächenorientierung. Anschließend fusioniert die Methode die generierten Punkte mit den ursprünglichen Messungen und kombiniert so das tatsächlich Beobachtete mit der besten Schätzung des Netzes für die fehlenden Teile. Ein abschließender Bereinigungsschritt entfernt Ausreißer mittels einer nächstnachbarbasierten Prüfung und resampelt das Ergebnis, sodass die Punkte gleichmäßig verteilt sind; so entsteht ein sauberes, homogenes 3D-Modell, das für nachfolgende Aufgaben bereit ist.
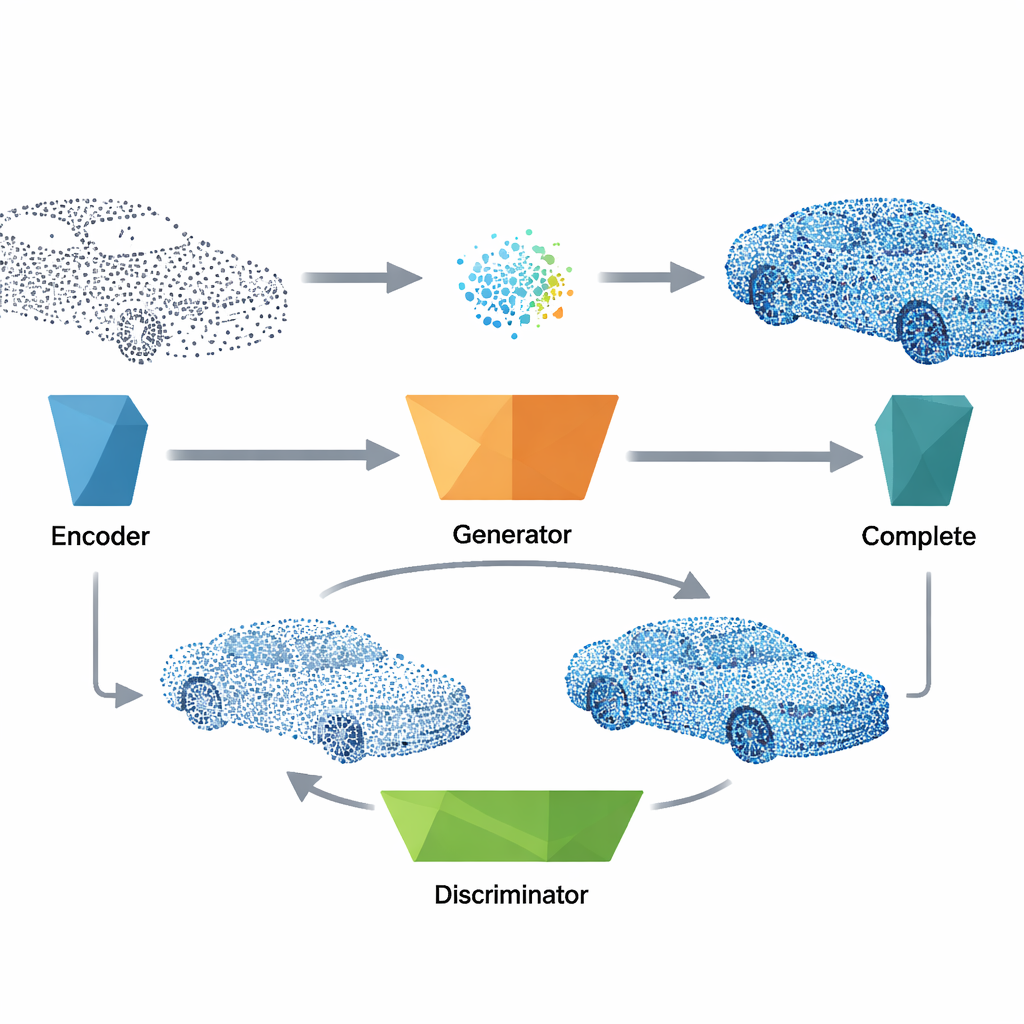
Realismus, Details und Effizienz ausbalancieren
Damit die Rekonstruktionen sowohl global stimmig als auch lokal glatt sind, entwerfen die Autoren eine mehrteilige Trainingszielsetzung. Neben dem zentralen adversarialen Signal, das den Generator dazu antreibt, den Diskriminator zu täuschen, fügen sie Terme hinzu, die konsistente Oberflächennormalen belohnen, eine gute Ausrichtung der generierten Punkte an realen Formen fördern und eine natürliche lokale Punktverteilung sicherstellen. Eine effiziente achsenorientierte Suchstrategie hält diese lokalen Prüfungen auch bei großen Punktmengen schnell. Experimente zeigen, dass diese Kombination von Verlusten für stabiles Lernen entscheidend ist: Das Weglassen eines einzelnen Terms beeinträchtigt entweder die Gesamtform oder die feinen Details. Trotz dieser Ausdifferenzierung ist das finale Modell schlank und läuft in Bruchteilen einer Sekunde auf moderner Hardware, was es für nahezu echtzeitfähige Anwendungen tauglich macht.
Von Laborbenchmarks zu realen Szenen
Auf dem ModelNet40-Benchmark übertrifft der vorgeschlagene Ansatz klassische geometriebasierte Algorithmen sowie mehrere führende Deep-Learning-Methoden bei gängigen Fehlermaßen. Er rekonstruiert Autos, Stühle und Betten mit höherer Treue, insbesondere wenn mehr als die Hälfte der ursprünglichen Punkte fehlt. Visuelle Vergleiche zeigen, dass die Methode zentrale Strukturkomponenten – etwa Autodächer oder Stuhllehnen – wiederherstellt, die bei anderen Verfahren oft verloren gehen. Die Autoren testen das System außerdem an realen Innenraumszenen und simulierten Fahrszenen, in denen Verdeckungen und Rauschen deutlich ausgeprägter sind als in sauberen Datensätzen. In beiden Fällen führen die vervollständigten Punktwolken zu genaueren 3D-Karten und unterstützen eine verbesserte Wegplanung: Mit der ergänzten Geometrie können Planungsalgorithmen versteckte Hindernisse besser vorhersagen und glattere, sicherere Routen wählen.
Ein klareres Bild von 3D-Welten
Zusammengefasst zeigt diese Arbeit, dass ein sorgfältig entwickeltes GAN ein starkes 3D-Prior lernen und nutzen kann, um stark beschädigte Punktwolken zu vervollständigen, ohne auf gepaarte Trainingsdaten angewiesen zu sein. Durch die Kombination eines einfachen Encoders, eines leistungsfähigen Generators, eines scharfsinnigen Diskriminators und einer wohlüberlegten Verlustfunktion erzeugt das System vollständige, glatte und strukturell stimmige 3D-Formen aus spärlichen und verrauschten Eingaben. Für Nicht-Expertinnen und Nicht-Experten ist die Kernbotschaft: Algorithmen können fehlende 3D-Informationen heute so „erraten“, dass das Ergebnis sowohl realistisch als auch praktikabel ist und Robotern, Fahrzeugen und Virtual-Reality-Systemen hilft, die Welt um sie herum vollständiger zu erkennen.
Zitation: Zhao, D., Mao, S., Shao, J. et al. Generative adversarial networks for high-fidelity 3D point cloud completion. Sci Rep 16, 14076 (2026). https://doi.org/10.1038/s41598-026-44111-5
Schlüsselwörter: 3D-Punktwolken, Formvervollständigung, generative adversariale Netze, autonomes Fahren, Roboterwahrnehmung