Clear Sky Science · fr
Réseaux antagonistes génératifs pour la complétion fidèle de nuages de points 3D
Pourquoi combler les vides 3D est important
Beaucoup des technologies qui transforment notre quotidien — des voitures autonomes aux robots domestiques en passant par la réalité virtuelle — reposent sur une compréhension 3D détaillée du monde. Ces systèmes utilisent souvent des capteurs qui recueillent des millions de points dans l’espace pour décrire des objets et des pièces. Mais en pratique, ces « nuages de points » sont truffés de lacunes à cause d’occultations, de surfaces brillantes ou de points de vue limités. Cet article présente une nouvelle méthode pour combler intelligemment ces vides, en utilisant un type d’intelligence artificielle appelé réseau antagoniste génératif (GAN) pour reconstruire des structures 3D manquantes même lorsque plus de la moitié des données est absente.
Voir les formes à partir de points épars
Un nuage de points 3D ressemble à une constellation de points qui esquisse la surface d’un objet ou d’une scène. Les scanners laser et les caméras de profondeur ont facilité la capture de ces données, mais les mesures réelles sont rarement complètes. Les méthodes classiques de réparation s’appuient sur des astuces locales, comme lisser les surfaces voisines ou interpoler entre points adjacents, et elles fonctionnent mieux lorsque seuls des petits trous sont présents. Les approches récentes en apprentissage profond améliorent cela en apprenant des motifs de forme, mais elles exigent généralement des paires d’entraînement soigneusement préparées montrant à la fois la version endommagée et la version complète de chaque objet. Cette exigence est difficile à satisfaire en dehors des jeux de données curatés et limite les performances lorsque des sections entières d’un objet — comme la carrosserie d’une voiture ou les pieds d’une chaise — sont manquantes.
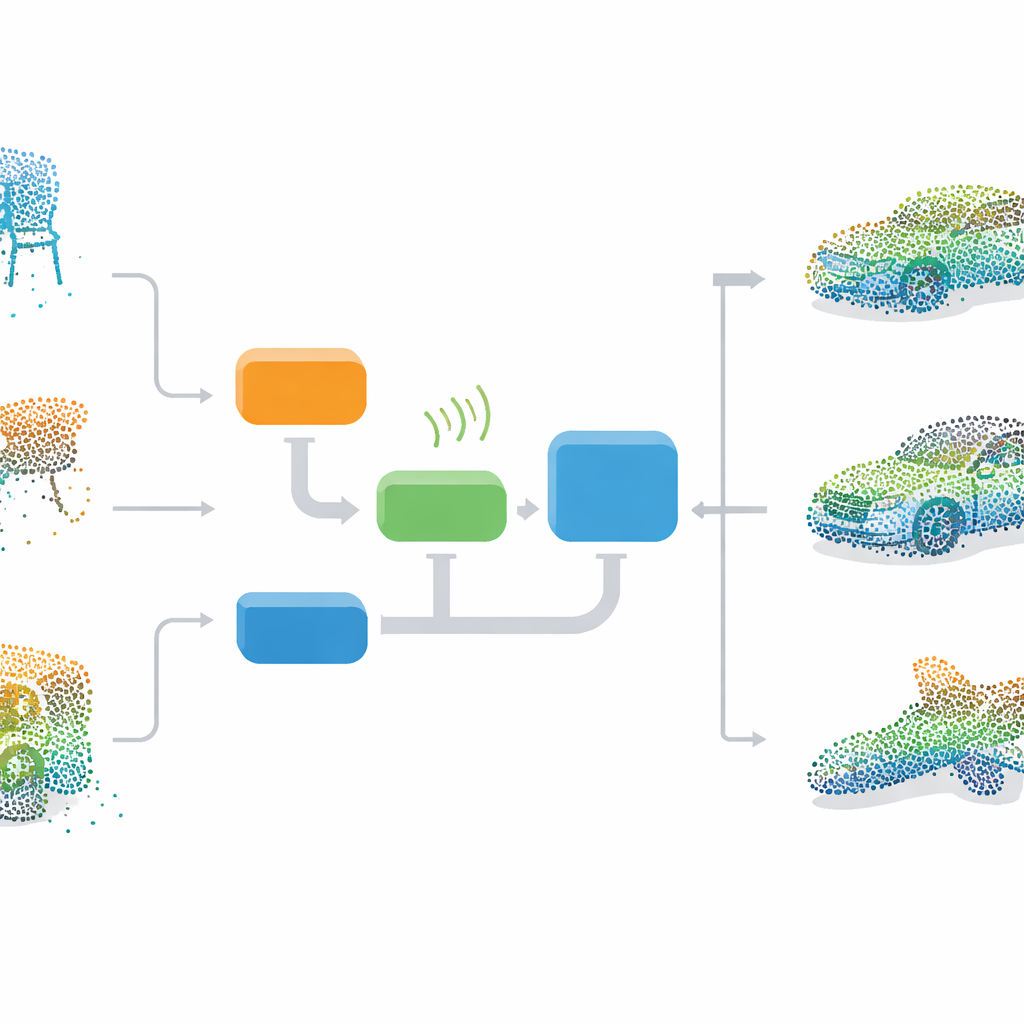
Apprendre une imagination 3D
Les auteurs proposent un cadre de bout en bout qui apprend à un réseau neuronal à imaginer des objets 3D complets à partir de rien, puis utilise cette imagination pour réparer des nuages de points endommagés. Au cœur du système se trouve un GAN, un modèle en deux parties où un générateur apprend à créer des nuages de points 3D réalistes tandis qu’un discriminateur apprend à distinguer les formes réelles des faux. Pendant l’entraînement, le générateur part d’un bruit aléatoire et apprend progressivement les distributions globales de chaises, lits, voitures et autres objets dans un jeu de données standard appelé ModelNet40. Parce qu’il apprend uniquement à partir d’exemples complets, la méthode n’a pas besoin de paires parfaitement appariées de données incomplètes et complètes, ce qui la rend plus pratique pour une utilisation dans le monde réel.
Comment le système comble les vides
Pour réparer un nuage de points abîmé, le système passe d’abord les données incomplètes dans un encodeur compact qui distille leur forme globale en un court vecteur de caractéristiques. Ce vecteur joue le même rôle que le bruit utilisé pendant l’entraînement et est alimenté dans le générateur entraîné, qui produit une version complète plausible de l’objet, incluant la géométrie et l’orientation des surfaces. La méthode fusionne ensuite les points générés avec les mesures d’origine, combinant ce qui a effectivement été observé avec la meilleure estimation du réseau pour les parties manquantes. Une étape finale de nettoyage supprime les points aberrants à l’aide d’un contrôle des plus proches voisins, puis rééchantillonne le résultat pour répartir les points de manière uniforme, donnant un modèle 3D net et homogène prêt pour des tâches en aval.
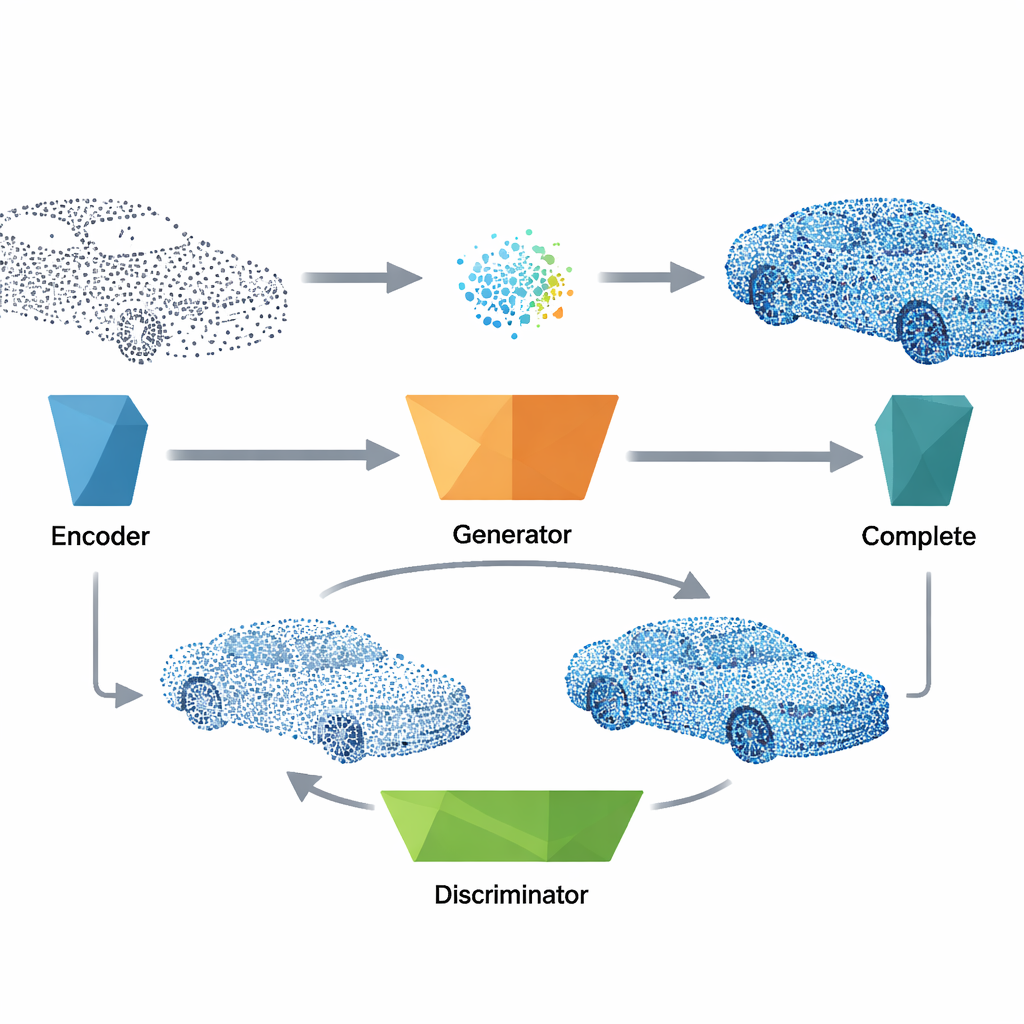
Équilibrer réalisme, détail et efficacité
Pour rendre les reconstructions à la fois cohérentes globalement et lisses localement, les auteurs conçoivent un objectif d’entraînement à plusieurs composantes. Outre le signal antagoniste central qui pousse le générateur à tromper le discriminateur, ils introduisent des termes qui récompensent la cohérence des directions de surface, le bon alignement des points générés avec les formes réelles et un espacement local naturel entre points voisins. Une stratégie de recherche alignée sur les axes rend ces contrôles locaux rapides, même pour de grands ensembles de points. Les expériences montrent que cette combinaison de fonctions de perte est cruciale pour un apprentissage stable : supprimer l’un de ces termes dégrade soit la forme globale soit les détails fins. Malgré cette sophistication, le modèle final est léger et s’exécute en une fraction de seconde sur du matériel moderne, ce qui le rend adapté aux applications quasi temps réel.
Des bancs d’essai de laboratoire aux scènes réelles
Sur le benchmark ModelNet40, l’approche proposée surpasse à la fois les algorithmes classiques basés sur la géométrie et plusieurs méthodes d’apprentissage profond de pointe selon les mesures d’erreur standard. Elle reconstruit voitures, chaises et lits avec une plus grande fidélité, en particulier lorsque plus de la moitié des points d’origine manquent. Les comparaisons visuelles montrent que la méthode restaure des composants structurels clés — comme les toits de voiture et les dossiers de chaise — que d’autres méthodes ratent souvent. Les auteurs testent aussi le système sur des scans réels d’intérieurs et des scènes de conduite simulées, où les occultations et le bruit sont bien plus sévères que dans les jeux de données propres. Dans les deux cas, les nuages de points complétés fournissent des cartes 3D plus précises et permettent une meilleure planification de trajectoire : avec la géométrie reconstituée, les algorithmes de planification peuvent prédire les obstacles cachés et choisir des trajectoires plus lisses et plus sûres.
Une vision 3D plus nette
En résumé, ce travail montre qu’un GAN bien conçu peut apprendre un puissant a priori 3D et l’utiliser pour compléter des nuages de points fortement endommagés sans dépendre de données d’entraînement appariées. En combinant un encodeur simple, un générateur performant, un discriminateur exigeant et une fonction de perte pensée, le système produit des formes 3D complètes, lisses et structurellement cohérentes à partir d’entrées rares et bruitées. Pour les non-spécialistes, le message clé est que les algorithmes peuvent désormais « deviner » l’information 3D manquante d’une manière à la fois réaliste et pratique, aidant robots, véhicules et systèmes de réalité virtuelle à percevoir une image plus complète du monde qui les entoure.
Citation: Zhao, D., Mao, S., Shao, J. et al. Generative adversarial networks for high-fidelity 3D point cloud completion. Sci Rep 16, 14076 (2026). https://doi.org/10.1038/s41598-026-44111-5
Mots-clés: nuages de points 3D, complétion de formes, réseaux antagonistes génératifs, navigation autonome, perception robotique