Clear Sky Science · en
Generative adversarial networks for high-fidelity 3D point cloud completion
Why filling in 3D gaps matters
Many of the technologies reshaping daily life—from self-driving cars to home robots and virtual reality—rely on a detailed 3D understanding of the world. These systems often use sensors that collect millions of points in space to outline objects and rooms. But in practice, such "point clouds" are full of gaps because of occlusions, shiny surfaces, or limited viewpoints. This paper presents a new way to intelligently fill in those gaps, using a type of artificial intelligence called a generative adversarial network (GAN) to reconstruct missing 3D structures even when more than half the data is gone.
Seeing shapes from scattered dots
A 3D point cloud is like a constellation of dots that sketch the surface of an object or a scene. Laser scanners and depth cameras have made it easy to capture such data, but real-world measurements are rarely complete. Traditional repair methods rely on local tricks, such as smoothing nearby surfaces or interpolating between neighboring points, and they work best when only small holes are present. More recent deep learning methods improve on this by learning shape patterns, but they usually need carefully prepared training pairs that show both the broken and the fully intact version of each object. This requirement is hard to meet outside curated research datasets, and it limits performance when whole sections of an object—like the body of a car or the legs of a chair—are missing.
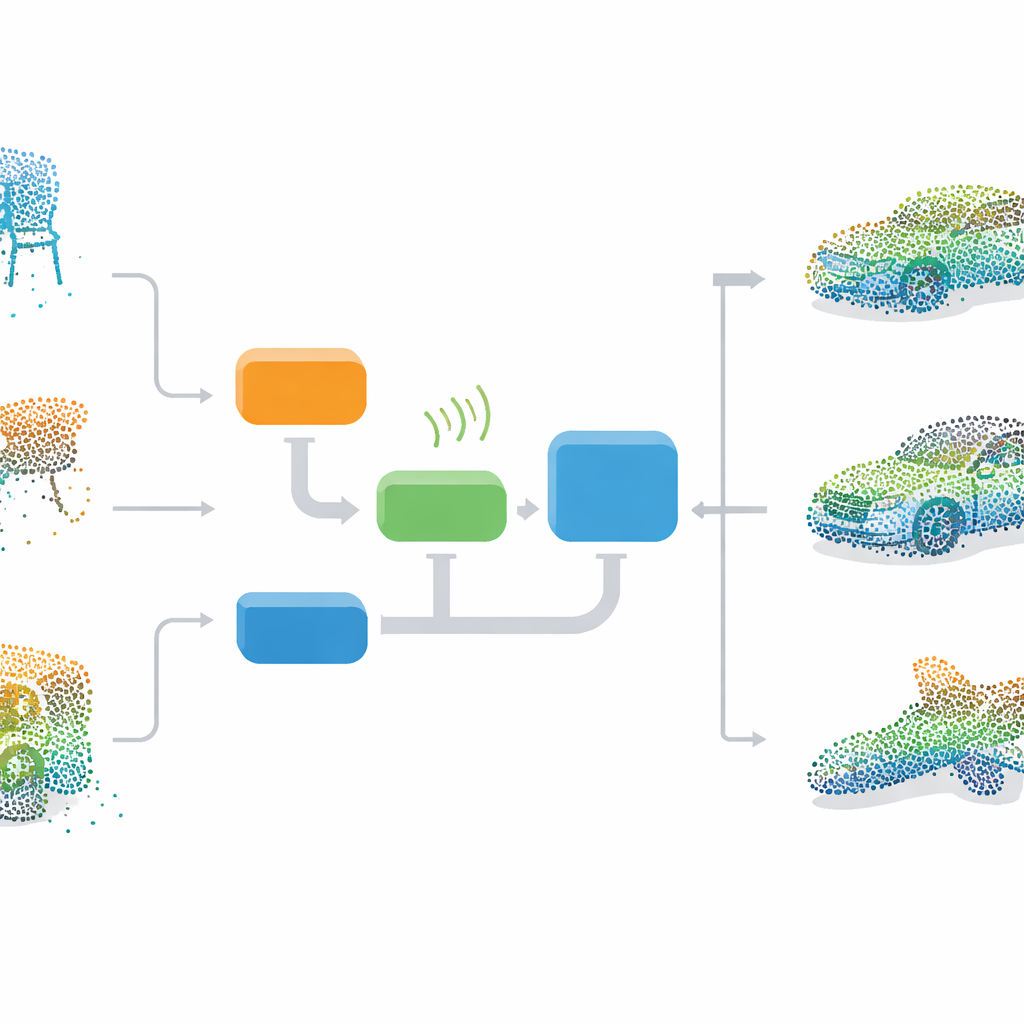
Teaching a 3D imagination
The authors propose an end-to-end framework that teaches a neural network to imagine complete 3D objects from scratch, and then use that imagination to repair damaged point clouds. At its heart is a GAN, a two-part model in which a generator learns to create realistic 3D point clouds while a discriminator learns to tell real shapes from fakes. During training, the generator starts from random noise and gradually learns the overall distributions of chairs, beds, cars, and other objects in a standard dataset called ModelNet40. Because it learns from full examples alone, the method does not need neatly matched pairs of incomplete and complete data, making it more practical for real-world use.
How the system fills the gaps
To repair a broken point cloud, the system first passes the incomplete data through a compact encoder that distills its overall shape into a short feature vector. This vector plays the same role as the noise used during training and is fed into the trained generator, which produces a plausible complete version of the object, including geometry and surface orientation information. The method then fuses the generated points with the original measurements, combining what was actually observed with the network’s best guess for the missing parts. A final clean-up step removes outlier points using a nearest-neighbor check and then resamples the result so the dots are evenly spread, yielding a tidy, uniform 3D model ready for downstream tasks.
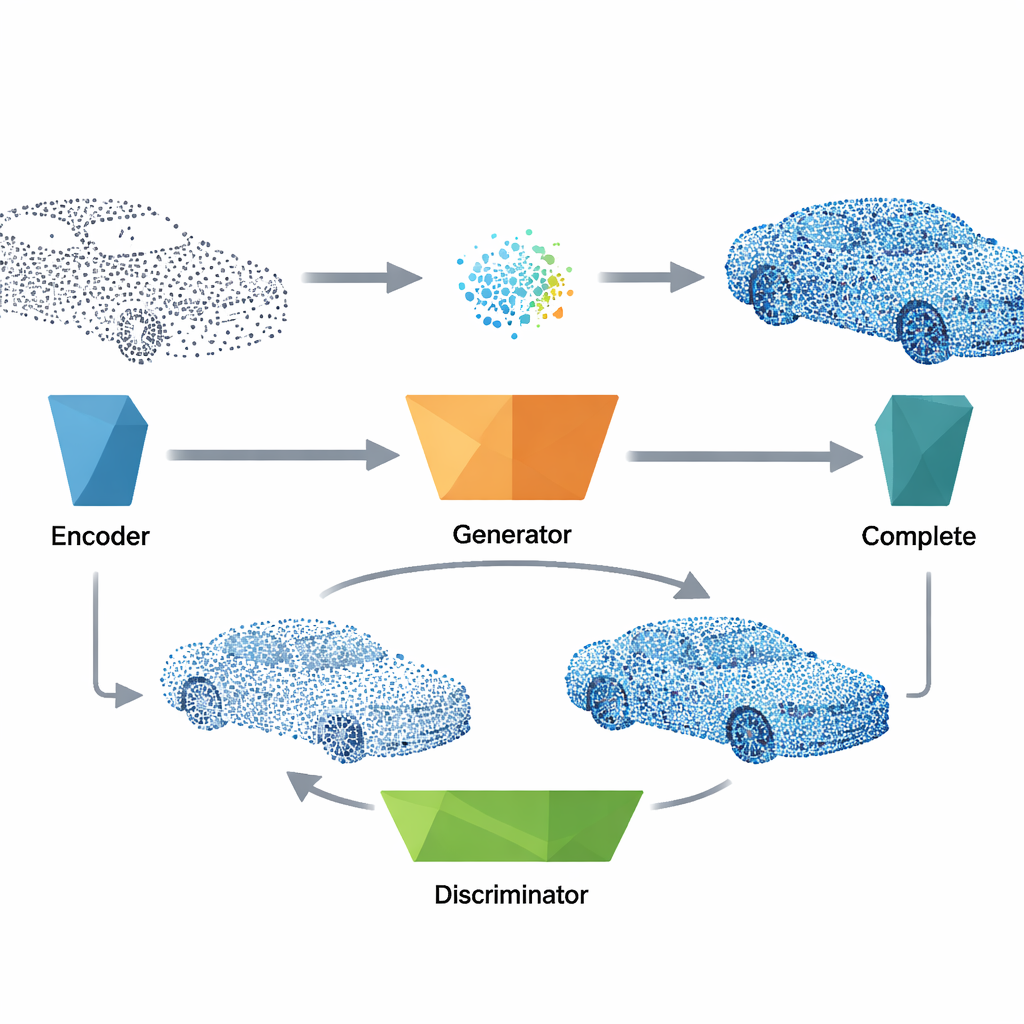
Balancing realism, detail, and efficiency
To make the reconstructions both globally coherent and locally smooth, the authors design a multi-part training objective. Besides the core adversarial signal that pushes the generator to fool the discriminator, they introduce terms that reward consistent surface directions, good alignment of generated points with real shapes, and natural local spacing between neighboring points. An efficient axis-aligned search strategy keeps these local checks fast even for large point sets. Experiments show that this combination of losses is crucial for stable learning: removing any one of them harms either the overall shape or the fine details. Despite this sophistication, the final model is lightweight, running in fractions of a second on modern hardware, which makes it suitable for near real-time applications.
From lab benchmarks to real-world scenes
On the ModelNet40 benchmark, the proposed approach outperforms both classic geometry-based algorithms and several leading deep learning methods across standard error measures. It reconstructs cars, chairs, and beds with higher fidelity, especially when more than half the original points are missing. Visual comparisons reveal that the method restores key structural components—like car roofs and chair backrests—that other methods often miss. The authors also test the system on real indoor scans and simulated driving scenes, where occlusions and noise are far more severe than in clean datasets. In both settings, the completed point clouds yield more accurate 3D maps and support better path planning: with the filled-in geometry, planning algorithms can predict hidden obstacles and choose smoother, safer routes.
A clearer picture of 3D worlds
In summary, this work shows that a carefully designed GAN can learn a strong 3D prior and use it to complete heavily damaged point clouds without relying on paired training data. By combining a simple encoder, a powerful generator, a discerning discriminator, and a thoughtfully crafted loss function, the system produces complete, smooth, and structurally sound 3D shapes from sparse and noisy inputs. For non-experts, the key message is that algorithms can now "guess" missing 3D information in a way that is both realistic and practical, helping robots, vehicles, and virtual reality systems see a more complete picture of the world around them.
Citation: Zhao, D., Mao, S., Shao, J. et al. Generative adversarial networks for high-fidelity 3D point cloud completion. Sci Rep 16, 14076 (2026). https://doi.org/10.1038/s41598-026-44111-5
Keywords: 3D point clouds, shape completion, generative adversarial networks, autonomous navigation, robot perception