Clear Sky Science · ru
Оптимизация межучрежденческой федеративной обучающей платформы для медицины с учётом конфиденциальных вычислений
Почему важно защищать совместно используемые медицинские данные
Современные больницы всё чаще полагаются на искусственный интеллект для чтения снимков, раннего обнаружения заболеваний и помощи в выборе лечения. Но для создания таких жизненно важных алгоритмов требуется огромное количество данных о пациентах, а обмен этими данными между учреждениями сталкивается с жёсткими правилами конфиденциальности и реальной угрозой взломов. В этой работе изучается, как больницы могут совместно обучать мощные ИИ-модели, не объединяя сырые медицинские записи, и как защититься от тонких аппаратных атак, которые могут вытекать секреты даже если данные никогда не покидают учреждение.
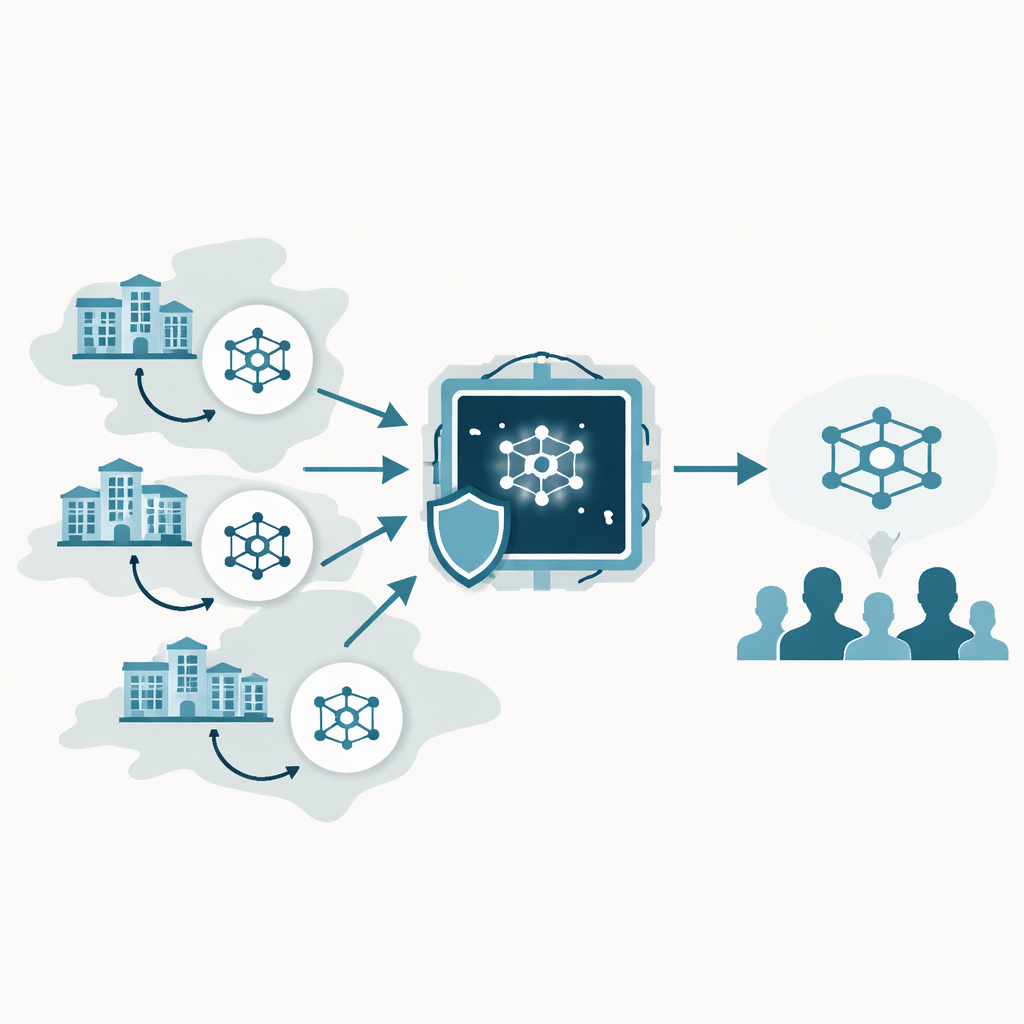
Больницы работают вместе, не передавая записи
Исследование основано на технике, называемой федеративным обучением, при которой каждое медицинское учреждение обучает собственную копию модели ИИ на локальных данных пациентов. Вместо отправки изображений или записей на центральный сервер, больницы пересылают только обновления модели, которые сервер объединяет в единый общий модельный объект и затем рассылает обратно. За несколько итераций этот процесс может дать систему ИИ, учитывающую опыт многих учреждений, при этом каждое хранит исходные данные за собственным файерволом. Такая схема привлекательна для здравоохранения и финансов, где законы и этика делают создание крупных централизованных хранилищ данных рискованным или невозможным.
Скрытые утечки внутри «защищённого» оборудования
Чтобы сделать такое сотрудничество безопаснее, многие системы используют конфиденциальные вычисления: специальные аппаратные области, называемые доверенными вычислительными окружениями, которые изолируют чувствительные вычисления от остальной части компьютера. В теории эти анклавы защищают процесс обучения модели от любопытных инсайдеров или скомпрометированных операционных систем. На практике они не совершенны. Атакующие иногда могут выводить секреты, наблюдая временные характеристики, использование кеша или другие побочные эффекты вычислений. Существующие методы федеративного обучения редко явно моделируют такие утечки. Они также склонны рассматривать приватность, точность модели и сетевые расходы как отдельные параметры проектирования, хотя на практике больницы вынуждены одновременно балансировать все три фактора.
Баланс между точностью, приватностью и сетевой нагрузкой
Авторы предлагают новый метод обучения под названием Confidential Computing-Aware Projected Gradient Descent (CC-PGD). Вместо того чтобы фокусироваться только на ошибке предсказания, CC-PGD одновременно оптимизирует три аспекта: насколько хорошо модель аппроксимирует данные, сколько информации может быть раскрыто через побочные каналы в защищённом оборудовании, и сколько коммуникации требуется между больницами и центральным сервером. Риск приватности измеряется «формой» градиентов, генерируемых моделью: если доминирует лишь несколько параметров, атакующий может узнать больше о конкретных пациентах; если информация распределена более равномерно, можно вывести меньше. Метод также включает индикатор, показывающий, когда известные аппаратные уязвимости более вероятно могут быть использованы, и член стоимости, учитывающий размер обновлений модели и время их передачи по сети.
Управляемый способ настройки параметров безопасности
Под капотом CC-PGD работает как аккуратно ограниченная версия обычного градиентного спуска, стандартного инструмента современного обучения ИИ. В статье доказано, что даже с дополнительными штрафами за приватность и коммуникации их оптимизатор по-прежнему сходится надёжно при широком наборе условий. Важно, что CC-PGD предоставляет два настраиваемых «регулятора», которыми могут управлять разработчики системы: один усиливает защиту приватности, другой ограничивает сетевые затраты. Изменяя эти регуляторы, операторы могут, например, предпочесть максимально возможную точность для исследовательского проекта или более жёсткую приватность и меньшую пропускную способность для сельской клиники с медленным интернетом.
Что показывают эксперименты
Для проверки идеи авторы смоделировали обучение моделей распознавания изображений в нескольких медицинских учреждениях на общеизвестных публичных наборах данных (MNIST и CIFAR-10). Они сравнили CC-PGD с популярными методами федеративного обучения, включая стандартное федеративное усреднение, метод с добавлением случайного шума для приватности и вариант, разработанный для неравномерного распределения данных между участниками. Во всех задачах — как простых, так и более сложных, и при равномерном и неравномерном разбиении данных — CC-PGD сохраняет точность близкой к той, которая была бы достигнута при централизации всех данных. При этом он снижает меры утечек приватности примерно на четверть-треть и уменьшает стоимость коммуникации примерно на пятую часть по сравнению с базовыми методами.
Что это означает для реального медицинского ИИ
Проще говоря, эта работа показывает, что больницы не обязаны жёстко выбирать между качеством модели, приватностью и практичностью при совместном обучении ИИ. Явно моделируя пути возможной утечки информации из предположительно безопасного оборудования и включая затраты на приватность и пропускную способность непосредственно в процесс обучения, CC-PGD предлагает принципиальный способ проектирования более безопасных совместных систем. Хотя в экспериментах использовались эталонные изображения, а не реальные обследования, рамки метода универсальны и могут применяться к большим моделям, включая генеративные ИИ-инструменты и языковые модели, анализирующие медицинские записи или журналы кибербезопасности. При дальнейшем подтверждении на реальных данных из больниц подобные подходы могут лечь в основу надёжных сетей ИИ, которые учатся на данных многих учреждений, сохраняя при этом данные каждого пациента надёжно локально.
Цитирование: Xu, F., Wei, X., Zhao, Z. et al. Optimization of cross-institutional medical federated learning framework driven by confidential computing. Sci Rep 16, 14323 (2026). https://doi.org/10.1038/s41598-026-44843-4
Ключевые слова: федеративное обучение, конфиденциальные вычисления, медицинский ИИ, обучение с сохранением приватности, доверенные вычислительные окружения