Clear Sky Science · de
Optimierung eines institutionsübergreifenden medizinischen föderierten Lernrahmens unter Nutzung vertraulicher Datenverarbeitung
Warum der Schutz geteilter medizinischer Daten wichtig ist
Moderne Krankenhäuser verlassen sich zunehmend auf Künstliche Intelligenz, um Bildaufnahmen zu lesen, Krankheiten früher zu erkennen und Behandlungen zu steuern. Lebensrettende Algorithmen benötigen jedoch große Mengen an Patientendaten, und das Teilen dieser Daten zwischen Institutionen kann mit strengen Datenschutzvorschriften und realen Sorgen über Hackerangriffe kollidieren. Dieses Papier untersucht, wie Krankenhäuser zusammenarbeiten können, um leistungsfähige KI-Modelle zu trainieren, ohne rohe Patientendaten zu bündeln, und wie man sich gegen subtile Hardware-Angriffe schützen kann, die Geheimnisse auslaugen können, selbst wenn die Daten das Krankenhaus nie verlassen.
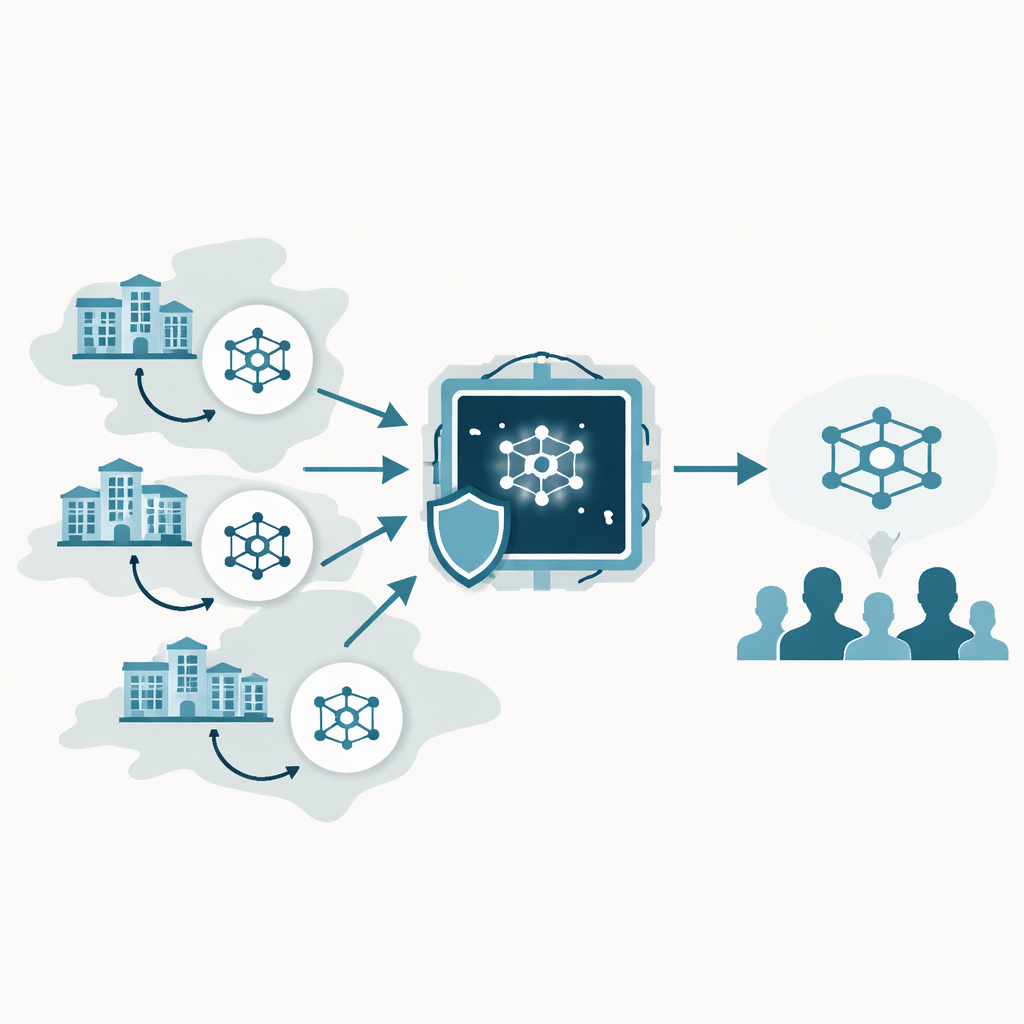
Krankenhäuser arbeiten zusammen, ohne Datensätze zu teilen
Die Studie basiert auf einer Technik namens föderiertes Lernen, bei der jede medizinische Einrichtung eine eigene Kopie eines KI-Modells auf lokalen Patientendaten trainiert. Anstatt Bilder oder Datensätze an einen zentralen Server zu senden, übermitteln die Krankenhäuser nur Modellupdates, die der Server zu einem gemeinsamen Modell kombiniert und anschließend zurücksendet. Über viele Runden kann dieser Prozess ein KI-System hervorbringen, das Wissen aus vielen Krankenhäusern reflektiert, während jede Einrichtung rohe Daten hinter ihrer eigenen Firewall behält. Diese Architektur ist für Gesundheitswesen und Finanzwesen attraktiv, wo Gesetze und Ethik große zentrale Datenpools riskant oder unmöglich machen.
Verborgene Lecks in „sicherer“ Hardware
Um diese Zusammenarbeit sicherer zu machen, verwenden viele Systeme vertrauliche Datenverarbeitung: spezielle Hardware-Bereiche, sogenannte vertrauenswürdige Ausführungsumgebungen (TEEs), die sensible Berechnungen vom Rest des Computers isolieren. Theoretisch schützen diese Enklaven das Modelltraining vor neugierigen Insidern oder kompromittierten Betriebssystemen. In der Praxis sind sie nicht perfekt. Angreifer können manchmal Geheimnisse ableiten, indem sie Timing, Cache-Nutzung oder andere Seiteneffekte der Berechnung beobachten. Bestehende föderierte Lernmethoden modellieren diese Lecks selten explizit. Sie neigen außerdem dazu, Datenschutz, Modellgenauigkeit und Netzwerkkosten als getrennte Designentscheidungen zu behandeln, obwohl in realen Einsätzen Krankenhäuser alle drei Aspekte gleichzeitig ausbalancieren müssen.
Balance zwischen Genauigkeit, Datenschutz und Netzwerkbelastung
Die Autoren schlagen eine neue Trainingsmethode vor, genannt Confidential Computing-Aware Projected Gradient Descent (CC-PGD). Anstatt sich nur auf den Vorhersagefehler zu konzentrieren, optimiert CC-PGD gleichzeitig drei Dinge: wie gut das Modell zu den Daten passt, wie viel Information durch Seitenkanäle in der sicheren Hardware preisgegeben werden könnte, und wie viel Kommunikation zwischen Krankenhäusern und dem zentralen Server erforderlich ist. Das Datenschutzrisiko wird anhand der »Form« der vom Modell erzeugten Gradienten gemessen: Dominieren nur wenige Parameter, kann ein Angreifer mehr über einzelne Patienten erfahren; ist die Information gleichmäßiger verteilt, lässt sich weniger ableiten. Die Methode enthält außerdem einen Indikator dafür, wann bekannte Hardware-Schwächen eher ausnutzbar sind, sowie einen Kostenfaktor, der erfasst, wie groß die Modellupdates sind und wie lange deren Übertragung über Netzwerke dauert.
Eine geführte Möglichkeit, Sicherheitseinstellungen anzupassen
Im Kern funktioniert CC-PGD wie eine sorgfältig eingeschränkte Version des gewöhnlichen Gradientenabstiegs, dem Standardverfahren des modernen KI-Trainings. Das Papier beweist, dass ihr Optimierer selbst mit den zusätzlichen Datenschutz- und Kommunikationsstrafen unter breiten Bedingungen zuverlässig konvergiert. Wichtig ist, dass CC-PGD zwei einstellbare »Regler« offenlegt, die Systemdesigner drehen können: einen, der den Datenschutz stärkt, und einen, der die Kommunikationskosten begrenzt. Durch das Hoch- oder Runterdrehen dieser Regler können Betreiber beispielsweise entscheiden, ob sie maximale Genauigkeit für eine Studie bevorzugen oder stärkeren Datenschutz und geringere Bandbreite für eine ländliche Klinik mit langsamer Internetverbindung.
Was die Experimente zeigen
Zur Prüfung der Idee simulieren die Autoren mehrere medizinische Institutionen, die Bilderkennungsmodelle auf bekannten öffentlichen Datensätzen (MNIST und CIFAR-10) trainieren. Sie vergleichen CC-PGD mit verbreiteten föderierten Lernmethoden, darunter standardmäßiges föderiertes Averaging, eine Technik, die zufälliges Rauschen zum Datenschutz hinzufügt, und eine Variante, die für unausgewogene Daten über Clients ausgelegt ist. Sowohl bei einfachen als auch bei komplexeren Bildaufgaben und bei gleichmäßig wie ungleich verteilten Daten hält CC-PGD die Genauigkeit nahe an dem Niveau, das erreicht würde, wenn alle Daten zentralisiert wären. Gleichzeitig reduziert es Maße für Datenschutzlecks um ungefähr ein Viertel bis ein Drittel und senkt die Kommunikationskosten im Vergleich zu den Baselines um etwa ein Fünftel.
Welche Bedeutung das für reale Gesundheits-KI hat
Kurz gesagt zeigt diese Arbeit, dass Krankenhäuser bei gemeinsamem KI-Training nicht strikt zwischen Modellqualität, Datenschutz und Praktikabilität wählen müssen. Indem explizit modelliert wird, wie Informationen aus vermeintlich sicherer Hardware entweichen könnten, und indem Datenschutz- und Bandbreitenkosten direkt in den Trainingsprozess eingebaut werden, bietet CC-PGD einen fundierten Weg, sicherere kollaborative Systeme zu entwerfen. Während die Experimente Benchmark-Bilder statt realer Scans verwenden, ist der Rahmen allgemein und könnte auf größere Modelle angewandt werden, einschließlich generativer KI-Werkzeuge und Sprachmodelle, die medizinische Notizen oder Sicherheitsprotokolle analysieren. Mit weiterer Validierung an echten Krankenhausdaten könnten Ansätze wie dieser vertrauenswürdige KI‑Netzwerke ermöglichen, die von vielen Institutionen lernen und gleichzeitig die Daten jedes Patienten sicher vor Ort belassen.
Zitation: Xu, F., Wei, X., Zhao, Z. et al. Optimization of cross-institutional medical federated learning framework driven by confidential computing. Sci Rep 16, 14323 (2026). https://doi.org/10.1038/s41598-026-44843-4
Schlüsselwörter: föderiertes Lernen, vertrauliche Datenverarbeitung, medizinische KI, datenschutzschonendes Training, vertrauenswürdige Ausführungsumgebungen