Clear Sky Science · pt
Uma rede de atenção leve e multiescala para detecção de riscos geológicos em robótica de resgate
Robôs mais inteligentes para terrenos perigosos
Quando terremotos, chuvas fortes ou cortes nas estradas provocam quedas de rochas e deslizamentos, muitas vezes é arriscado demais para pessoas inspecionarem encostas e vias danificadas. Este estudo mostra como um novo sistema de visão “leve” pode ajudar pequenos robôs de resgate a identificar rapidamente obstáculos perigosos e falhas do solo em cenas caóticas, mesmo quando os robôs dispõem apenas de capacidade de processamento limitada a bordo.
Por que localizar riscos é tão difícil
Riscos geológicos no mundo real apresentam muitas formas e tamanhos: uma única pedra solta, a borda de uma estrada desmoronada, um talude cedendo ou uma árvore caída sobre a pista. Cores e texturas frequentemente se confundem com o terreno circundante, e mau tempo, poeira e vegetação tornam a cena ainda mais confusa. Robôs de resgate trabalham com computadores e baterias compactos, de modo que não podem executar modelos de inteligência artificial grandes e consumidores de energia. Sistemas de detecção existentes ou deixam passar alvos pequenos ou ambíguos, ou são pesados demais para rodar eficientemente em um robô em campo.

Uma nova forma de focalizar a visão do robô
Os pesquisadores se baseiam em uma família popular de detectores de objetos em tempo real conhecidos como YOLO, amplamente usados para localizar objetos em imagens e vídeo. Eles introduzem um novo bloco de construção chamado módulo Depthwise Separable Selective Kernel Attention (DSSKA), que é então integrado a uma rede compacta YOLOv8n para criar o modelo DSSKA-YOLOv8n. Em termos simples, esse módulo permite que a rede observe a mesma cena por meio de várias “janelas” de tamanhos diferentes e, em seguida, decida automaticamente qual tamanho de janela é mais relevante em cada ponto da imagem. Ao usar uma forma enxuta de cálculo, mantém o número de parâmetros treináveis pequeno enquanto aprimora a capacidade do modelo de notar tanto pequenas rochas quanto grandes falhas de talude.
Treinamento em cenas reais de montanha
Para testar a abordagem, a equipe montou uma coleção de imagens personalizada a partir de estradas montanhosas propensas a perigos na Província de Sichuan, China. O conjunto de dados contém quatro tipos principais de perigo: quedas de rochas, árvores caídas, deslizamentos e colapsos de estrada. Eles ampliaram e equilibraram essa coleção com processamento cuidadoso de imagem, como rotação de vistas, alteração de iluminação e simulação de desfoque ou bloqueio parcial, para imitar mau tempo e cenas poluídas. O modelo foi então treinado e avaliado em condições controladas, usando medidas padrão de quão frequentemente encontra riscos corretamente e quão precisamente os contorna.
Desempenho do novo modelo
Em comparação com a rede YOLOv8n original, o DSSKA-YOLOv8n eleva a qualidade geral de detecção aumentando o tamanho do modelo apenas marginalmente. Também supera outra versão que usa um módulo de atenção mais tradicional, mas com cerca de 61% a menos de parâmetros. Nos quatro tipos de risco, o novo modelo alcança alta precisão e boas pontuações em testes exigentes que premia a detecção precisa em vários níveis de sobreposição entre predições e verdade de campo. Mostra-se especialmente eficaz para padrões mais evidentes, como estradas desabadas e grandes deslizamentos, embora quedas de rocha muito irregulares e troncos de árvores que se confundem com o fundo permaneçam mais difíceis. Inspeções visuais mostram que a rede melhorada foca com mais precisão nos contornos e nas texturas dos riscos reais, gerando menos falsos positivos e menos perda de alvos pequenos do que a baseline.
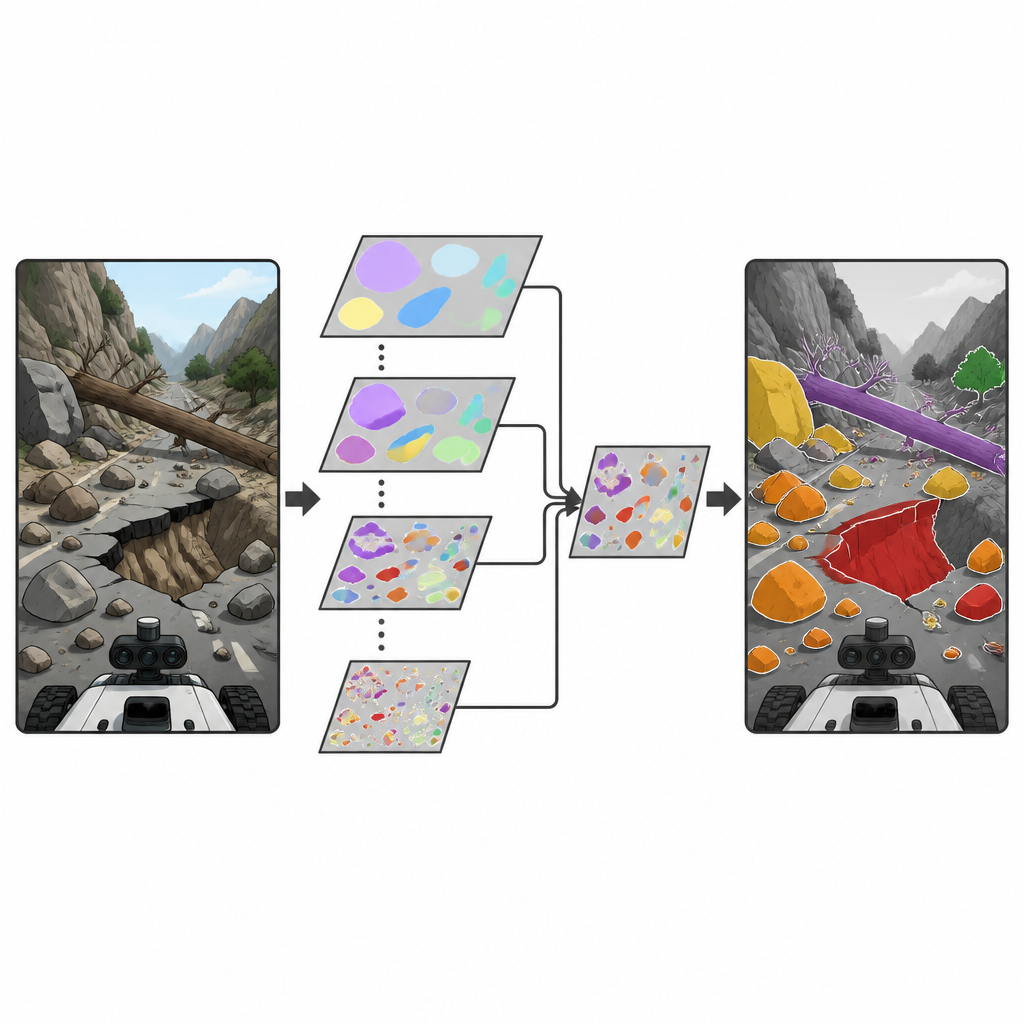
Limites e próximos passos
Apesar desses ganhos, os autores identificam vários problemas em aberto. O sistema atual ainda tem dificuldades com objetos extremamente pequenos e limites confusos, por exemplo onde rochas e sombras se encontram, ou onde marcas viárias e águas de enchente se assemelham a pilhas de pedras. Ele também presta atenção limitada ao contexto mais amplo da cena, como se a abertura de um túnel realmente sinaliza um colapso. O conjunto de dados vem de uma única região, de modo que o desempenho em climas e paisagens muito diferentes é incerto, e o modelo ainda não foi testado em um robô em movimento, onde velocidade, consumo de energia e confiabilidade sob vibração e poeira são cruciais.
O que isso significa para futuros resgates
No geral, o estudo apresenta uma ferramenta de visão compacta que ajuda robôs de resgate a identificar melhor características de terreno perigosas sem precisar de computadores pesados. Ao combinar visões multiescala da cena com uma estratégia de atenção eficiente, o modelo DSSKA-YOLOv8n aproxima-se da precisão de detectores grandes mantendo-se adequado a máquinas pequenas e com energia limitada. Com dados de treinamento mais amplos, maior consciência do contexto da cena e testes em plataformas robóticas no mundo real, sistemas assim podem um dia fornecer a equipes de resgate informações mais rápidas e seguras sobre taludes instáveis e estradas danificadas nas horas cruciais após um desastre.
Citação: Ren, K., Xiao, X., Ma, J. et al. A lightweight and cross-scale attention network for geological hazard detection in rescue robotics. Sci Rep 16, 14916 (2026). https://doi.org/10.1038/s41598-026-45112-0
Palavras-chave: riscos geológicos, robôs de resgate, detecção de objetos, redes de atenção, monitoramento de deslizamentos