Clear Sky Science · it
Una rete di attenzione leggera e a scala incrociata per il rilevamento di rischi geologici nella robotica di soccorso
Robot più intelligenti per territori pericolosi
Quando terremoti, piogge intense o lavori stradali provocano cadute di massi e frane, spesso è troppo rischioso che le persone ispezionino i pendii e le strade danneggiate. Questo studio mostra come un nuovo sistema di visione “leggero” possa aiutare piccoli robot di soccorso a individuare rapidamente ostacoli pericolosi e cedimenti del terreno in scene caotiche, anche quando i robot dispongono solo di una capacità di calcolo a bordo limitata.
Perché individuare i pericoli è così difficile
I rischi geologici nel mondo reale assumono molte forme e dimensioni: un singolo masso instabile, il bordo di una strada crollato, il cedimento di un versante o un albero caduto sulla carreggiata. I loro colori e le loro trame spesso si confondono con il terreno circostante, e il maltempo, la polvere e la vegetazione rendono la scena ancora più disordinata. I robot di soccorso devono operare con computer e batterie compatti, perciò non possono eseguire modelli di intelligenza artificiale grandi e energivori. I sistemi di rilevamento esistenti o non individuano i bersagli piccoli o ambigui, oppure sono troppo pesanti per funzionare in modo efficiente su un robot in movimento.

Un nuovo modo per concentrare la visione del robot
I ricercatori si basano su una famiglia popolare di rivelatori di oggetti in tempo reale noti come YOLO, ampiamente usati per trovare oggetti in immagini e video. Introducono un nuovo blocco costruttivo chiamato Depthwise Separable Selective Kernel Attention (DSSKA), che integrano in una compatta rete YOLOv8n per creare il modello DSSKA-YOLOv8n. In termini semplici, questo modulo permette alla rete di osservare la stessa scena attraverso diverse “finestre” di dimensioni differenti e poi decidere automaticamente quale dimensione di finestra sia più rilevante in ogni punto dell’immagine. Utilizzando una forma snella di calcolo, mantiene basso il numero di parametri addestrabili pur affinando la capacità del modello di notare sia piccole pietre che ampi cedimenti di versante.
Addestramento su scene montane reali
Per testare l’approccio, il team ha assemblato una raccolta di immagini personalizzata proveniente da strade montane soggette a pericoli nella provincia di Sichuan, Cina. Il dataset contiene quattro tipi principali di pericolo: cadute di massi, alberi caduti, frane e crolli stradali. Hanno ampliato e bilanciato questa raccolta con un’attenta elaborazione delle immagini, come rotazioni delle inquadrature, modifiche dell’illuminazione e simulazioni di sfocatura o ostruzione parziale, per imitare il maltempo e le scene ingombre. Il modello è stato quindi addestrato e valutato in condizioni controllate, usando misure standard su quanto spesso individua i pericoli correttamente e quanto precisamente ne delimita i contorni.
Quanto bene si comporta il nuovo modello
Rispetto alla rete YOLOv8n originale, DSSKA-YOLOv8n migliora la qualità complessiva del rilevamento aumentando la dimensione del modello di solo una piccola percentuale. Sovraperforma inoltre un’altra versione che utilizza un modulo di attenzione più tradizionale, ma con circa il 61% di parametri in meno. Su tutti e quattro i tipi di pericolo, il nuovo modello raggiunge alta precisione e punteggi solidi in test impegnativi che premiano un rilevamento accurato a vari livelli di sovrapposizione tra predizioni e verità a terra. Si dimostra particolarmente efficace per pattern più chiari come strade collassate e grandi frane, sebbene le cadute di massi molto irregolari e i tronchi d’albero che si confondono con lo sfondo rimangano più difficili. Ispezioni visive mostrano che la rete migliorata si concentra più strettamente sui contorni e sulle trame dei veri pericoli e genera meno falsi allarmi e meno omissioni di bersagli piccoli rispetto al modello di riferimento.
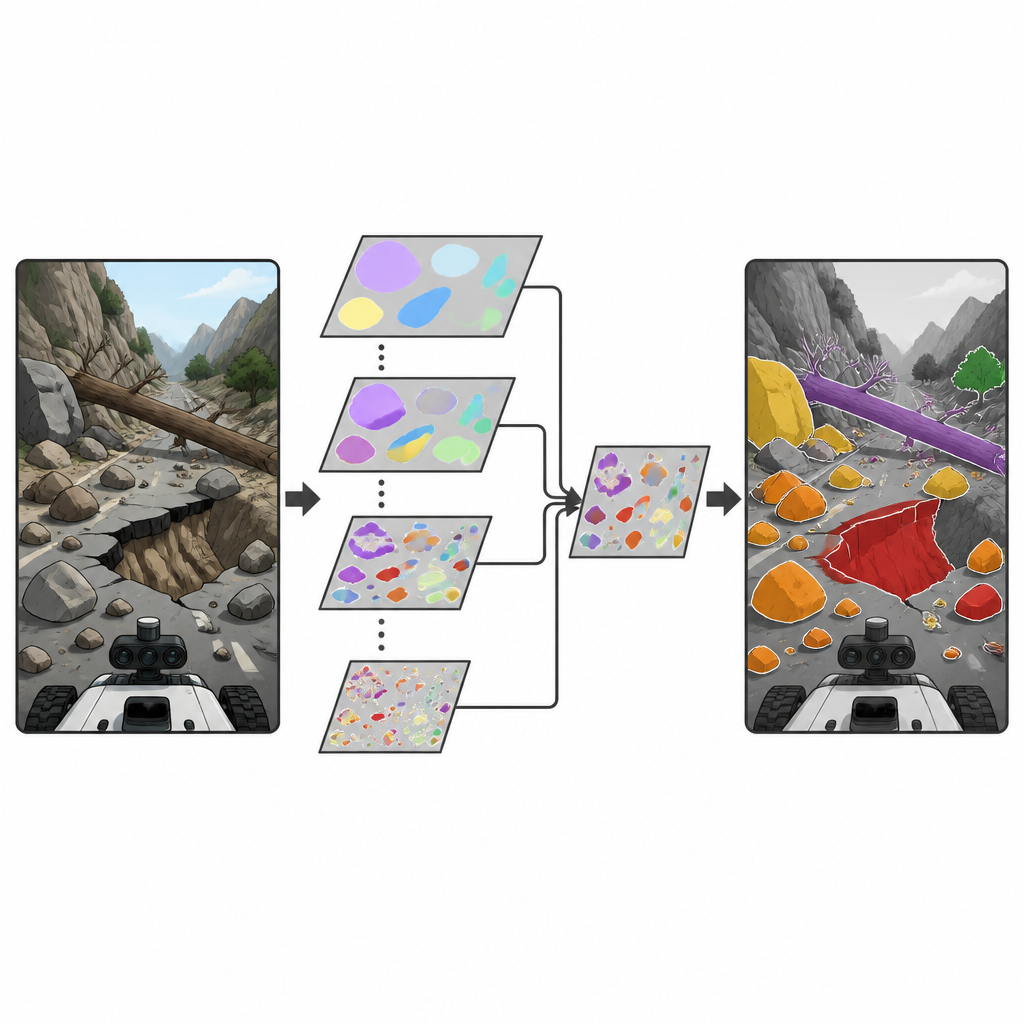
Limiti e prossimi passi
Nonostante questi miglioramenti, gli autori identificano diversi problemi aperti. L’attuale sistema fatica ancora con oggetti estremamente piccoli e confini ambigui, per esempio dove massi e ombre si incontrano, o dove segnaletica stradale e acqua alluvionale ricordano cumuli di rocce. Presta inoltre attenzione limitata alla scena più ampia, come capire se l’apertura di una galleria segnali realmente un crollo. Il dataset proviene da una singola regione, quindi la prestazione in climi e paesaggi molto diversi è incerta, e il modello non è ancora stato testato su un robot in movimento, dove velocità, consumo energetico e affidabilità sotto vibrazione e polvere sono fattori critici.
Cosa significa per i soccorsi futuri
Nel complesso, lo studio presenta uno strumento di visione compatto che aiuta i robot di soccorso a riconoscere meglio le caratteristiche del terreno pericolose senza richiedere computer pesanti. Combinando visuali multiscala della scena con una strategia di attenzione efficiente, il modello DSSKA-YOLOv8n si avvicina all’accuratezza dei rivelatori di grandi dimensioni restando adatto a macchine piccole e con risorse energetiche limitate. Con dati di addestramento più ampi, una maggiore consapevolezza del contesto della scena e test sul campo su piattaforme robotiche reali, tali sistemi potrebbero un giorno fornire ai soccorritori informazioni più rapide e più sicure su pendii instabili e strade danneggiate nelle ore cruciali dopo una catastrofe.
Citazione: Ren, K., Xiao, X., Ma, J. et al. A lightweight and cross-scale attention network for geological hazard detection in rescue robotics. Sci Rep 16, 14916 (2026). https://doi.org/10.1038/s41598-026-45112-0
Parole chiave: rischi geologici, robot di soccorso, rilevamento oggetti, reti di attenzione, monitoraggio frane