Clear Sky Science · nl
Een lichtgewicht en schaaloverschrijdend attentienetwerk voor detectie van geologische gevaren in reddingsrobotica
Slimmere robots voor gevaarlijk terrein
Wanneer aardbevingen, hevige regenval of wegwerkzaamheden steenstortingen en aardverschuivingen veroorzaken, is het vaak te gevaarlijk voor mensen om beschadigde hellingen en wegen te verkennen. Deze studie toont aan hoe een nieuw "lichtgewicht" visionsysteem kleine reddingsrobots kan helpen snel gevaarlijke obstakels en grondinstabiliteiten in dergelijke chaotische scènes te ontdekken, zelfs wanneer de robots slechts beperkte rekenkracht aan boord hebben.
Waarom het zo lastig is om gevaren te ontdekken
Geologische gevaren komen in de echte wereld in vele vormen en maten voor: een losse kei, een ingestorte wegrand, een helling die bezwijkt of een boom die een rijstrook blokkeert. Hun kleuren en texturen vallen vaak samen met het omringende terrein, en slecht weer, stof en vegetatie maken het beeld nog rommeliger. Reddingsrobots moeten werken met compacte computers en accu’s, dus ze kunnen geen enorme, energie-intensieve AI-modellen draaien. Bestaande detectiesystemen missen vaak kleine of verwarrende doelen of zijn te zwaar om efficiënt op een robot in het veld te draaien.

Een nieuwe manier om robotvisie te richten
De onderzoekers bouwen voort op een populaire familie real-time objectdetectors bekend als YOLO, veelgebruikt om objecten in beelden en video te vinden. Zij introduceren een nieuw bouwblok genaamd Depthwise Separable Selective Kernel Attention (DSSKA)-module, en voegen dit in een compacte YOLOv8n-netwerk om het DSSKA-YOLOv8n-model te creëren. In gewone taal stelt deze module het netwerk in staat dezelfde scène te bekijken via meerdere venstergroottes en vervolgens automatisch te bepalen welke venstergrootte op elk punt in de afbeelding het belangrijkst is. Door een zuinige vorm van berekening te gebruiken, blijft het aantal trainbare parameters laag terwijl het vermogen van het model om zowel kleine stenen als brede hellingfouten op te merken, wordt aangescherpt.
Training op echte bergscènes
Om hun aanpak te testen, stelde het team een aangepaste beeldverzameling samen van gevaarlijke bergwegen in de provincie Sichuan, China. De dataset bevat vier hoofdtypen gevaren: steenlawines, omgevallen bomen, aardverschuivingen en weginstortingen. Ze breidden deze collectie uit en brachten balans aan met zorgvuldig beeldverwerken, zoals het roteren van beelden, het aanpassen van belichting en het simuleren van vervaging of gedeeltelijke blokkering, om slecht weer en rommelige scènes na te bootsen. Het model werd daarna getraind en gecontroleerd onder gecontroleerde omstandigheden, met gebruik van standaardmaatregelen voor hoe vaak het gevaren correct vindt en hoe nauwkeurig het ze afbakent.
Hoe goed het nieuwe model presteert
In vergelijking met het oorspronkelijke YOLOv8n-netwerk verhoogt DSSKA-YOLOv8n de algehele detectiekwaliteit terwijl de modelgrootte slechts marginaal toeneemt. Het presteert ook beter dan een andere versie met een meer traditioneel attentiemodule, maar met ongeveer 61 procent minder parameters. Over alle vier de gevarentypen bereikt het nieuwe model hoge precisie en sterke scores in veeleisende tests die nauwkeurige detectie belonen bij verschillende overlapniveaus tussen voorspellingen en de grondwaarheid. Het blijkt bijzonder effectief voor duidelijkere patronen zoals ingestorte wegen en grote aardverschuivingen, hoewel zeer onregelmatige steenlawines en boomstammen die in de achtergrond opgaan moeilijker blijven. Visuele inspecties tonen dat het verbeterde netwerk zich strakker richt op de omtrekken en texturen van echte gevaren en minder vals alarm en gemiste kleine doelen genereert dan de basislijn.
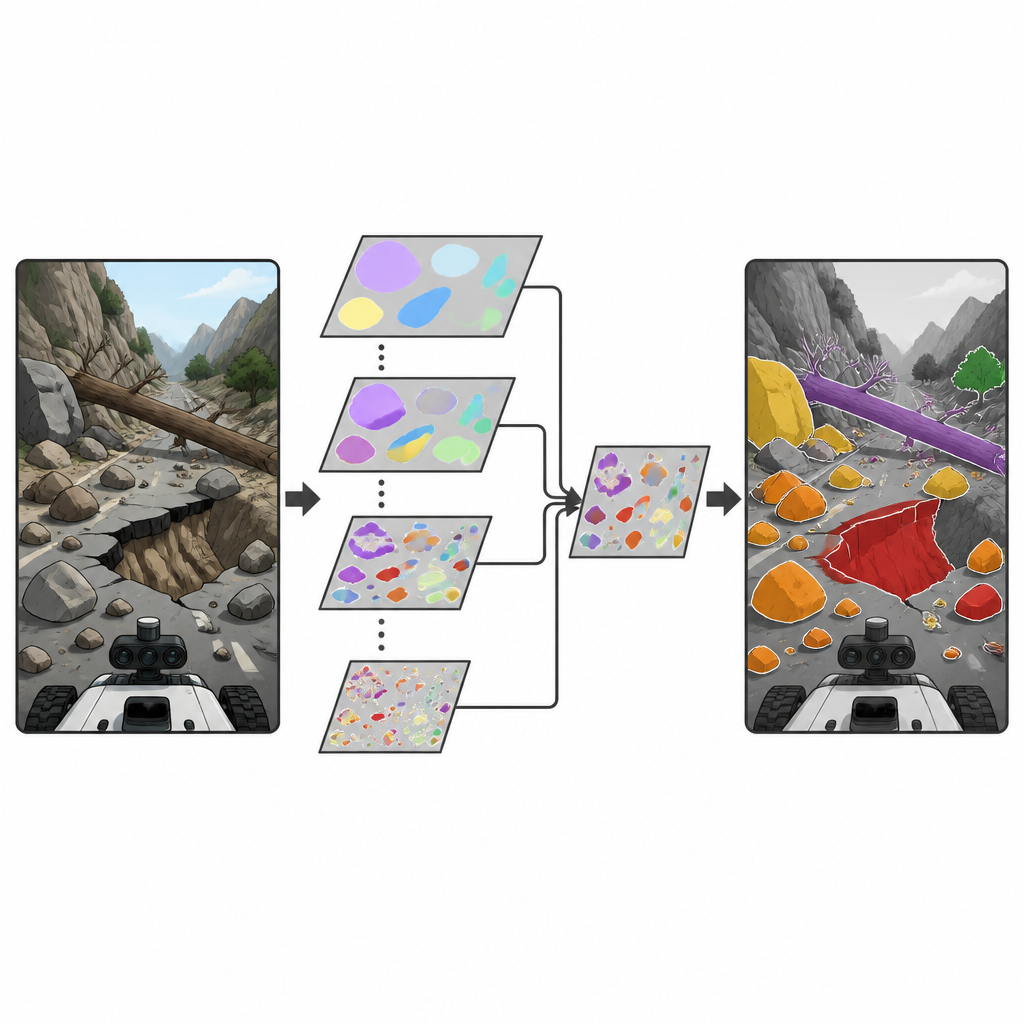
Beperkingen en volgende stappen
Ondanks deze verbeteringen identificeren de auteurs meerdere openstaande problemen. Het huidige systeem heeft nog steeds moeite met extreem kleine objecten en verwarrende grensgebieden, bijvoorbeeld waar stenen en schaduwen samenvloeien, of waar wegmarkeringen en overstromingswater op hopen stenen lijken. Het besteedt ook beperkte aandacht aan de bredere context van de scène, zoals of de opening van een tunnel daadwerkelijk een instorting aangeeft. De dataset komt uit één regio, dus de prestaties in heel andere klimaten en landschappen zijn onzeker, en het model is nog niet getest op een echte bewegende robot, waar snelheid, energieverbruik en betrouwbaarheid onder trillingen en stof van belang zijn.
Wat dit betekent voor toekomstige reddingsoperaties
Al met al presenteert de studie een compact visietool dat reddingsrobots helpt gevaarlijke terreinkenmerken beter te onderscheiden zonder zware computers nodig te hebben. Door multi-schaalbeelden van de scène te combineren met een efficiënte attentiestrategie, komt het DSSKA-YOLOv8n-model dichter bij de nauwkeurigheid van grote detectors terwijl het geschikt blijft voor kleine, energielimiteerde machines. Met bredere trainingsdata, meer bewustzijn van scènescontext en tests in de praktijk op robotplatforms, zouden dergelijke systemen op een dag hulpverleners sneller en veiliger inzicht kunnen geven in onstabiele hellingen en beschadigde wegen in de cruciale uren na een ramp.
Bronvermelding: Ren, K., Xiao, X., Ma, J. et al. A lightweight and cross-scale attention network for geological hazard detection in rescue robotics. Sci Rep 16, 14916 (2026). https://doi.org/10.1038/s41598-026-45112-0
Trefwoorden: geologische gevaren, reddingsrobots, objectdetectie, attentienetwerken, monitoring van aardverschuivingen