Clear Sky Science · es
Una red de atención ligera y multiescala para la detección de peligros geológicos en robótica de rescate
Robots más inteligentes para tierras peligrosas
Cuando terremotos, lluvias intensas o cortes en la carretera provocan desprendimientos y deslizamientos, a menudo es demasiado arriesgado que las personas inspeccionen taludes y vías dañadas. Este estudio demuestra cómo un nuevo sistema de visión "ligero" puede ayudar a pequeños robots de rescate a detectar rápidamente obstáculos peligrosos y fallos del terreno en escenas caóticas, incluso cuando los robots disponen de capacidad de cálculo a bordo limitada.
Por qué es tan difícil detectar peligros
Los peligros geológicos en el mundo real presentan muchas formas y tamaños: una sola roca suelta, el borde de una carretera colapsado, un talud que cede o un árbol caído sobre un carril. Sus colores y texturas frecuentemente se confunden con el terreno circundante, y el mal tiempo, el polvo y la vegetación empeoran la vista. Los robots de rescate trabajan con ordenadores y baterías compactos, por lo que no pueden ejecutar modelos de inteligencia artificial enormes y consumidores de energía. Los sistemas de detección existentes o bien pasan por alto objetivos pequeños o confusos, o bien son demasiado pesados para funcionar con eficiencia en un robot de campo.

Una nueva forma de enfocar la visión del robot
Los investigadores se basan en una familia popular de detectores de objetos en tiempo real conocida como YOLO, ampliamente usada para encontrar objetos en imágenes y vídeo. Introducen un nuevo bloque llamado Depthwise Separable Selective Kernel Attention (DSSKA), y lo integran en una red compacta YOLOv8n para crear el modelo DSSKA-YOLOv8n. En términos sencillos, este módulo permite que la red observe la misma escena a través de varias “ventanas” de distinto tamaño y luego decida automáticamente qué tamaño de ventana importa más en cada punto de la imagen. Al emplear una forma de cálculo eficiente, mantiene el número de parámetros entrenables reducido mientras agudiza la capacidad del modelo para notar tanto rocas diminutas como fallos extensos del talud.
Entrenamiento con escenas reales de montaña
Para probar su enfoque, el equipo reunió una colección de imágenes personalizada procedente de carreteras montañosas propensas a peligros en la provincia de Sichuan, China. El conjunto de datos contiene cuatro tipos principales de peligro: desprendimientos de roca, árboles caídos, deslizamientos y colapsos de carretera. Ampliaron y equilibraron esta colección con un procesamiento cuidadoso de las imágenes, como rotaciones de vista, cambios de iluminación y la simulación de desenfoque o bloqueos parciales, para imitar el mal tiempo y las escenas con desorden. Después, el modelo se entrenó y comprobó en condiciones controladas, usando medidas estándar de qué tan a menudo detecta peligros correctamente y con qué precisión los delimita.
Qué tan bien funciona el nuevo modelo
En comparación con la red YOLOv8n original, DSSKA-YOLOv8n mejora la calidad global de detección aumentando el tamaño del modelo solo por un pequeño margen. También supera a otra versión que usa un módulo de atención más tradicional, pero con aproximadamente un 61 % menos de parámetros. En los cuatro tipos de peligro, el nuevo modelo alcanza alta precisión y puntuaciones sólidas en pruebas exigentes que premian la detección precisa a múltiples niveles de solapamiento entre las predicciones y la verdad de terreno. Resulta especialmente eficaz para patrones más claros como carreteras colapsadas y grandes deslizamientos, aunque los desprendimientos muy irregulares y los troncos que se confunden con el fondo siguen siendo más difíciles. Inspecciones visuales muestran que la red mejorada se centra más en los contornos y texturas de los peligros reales y comete menos falsas alarmas y omisiones de objetivos pequeños que la referencia.
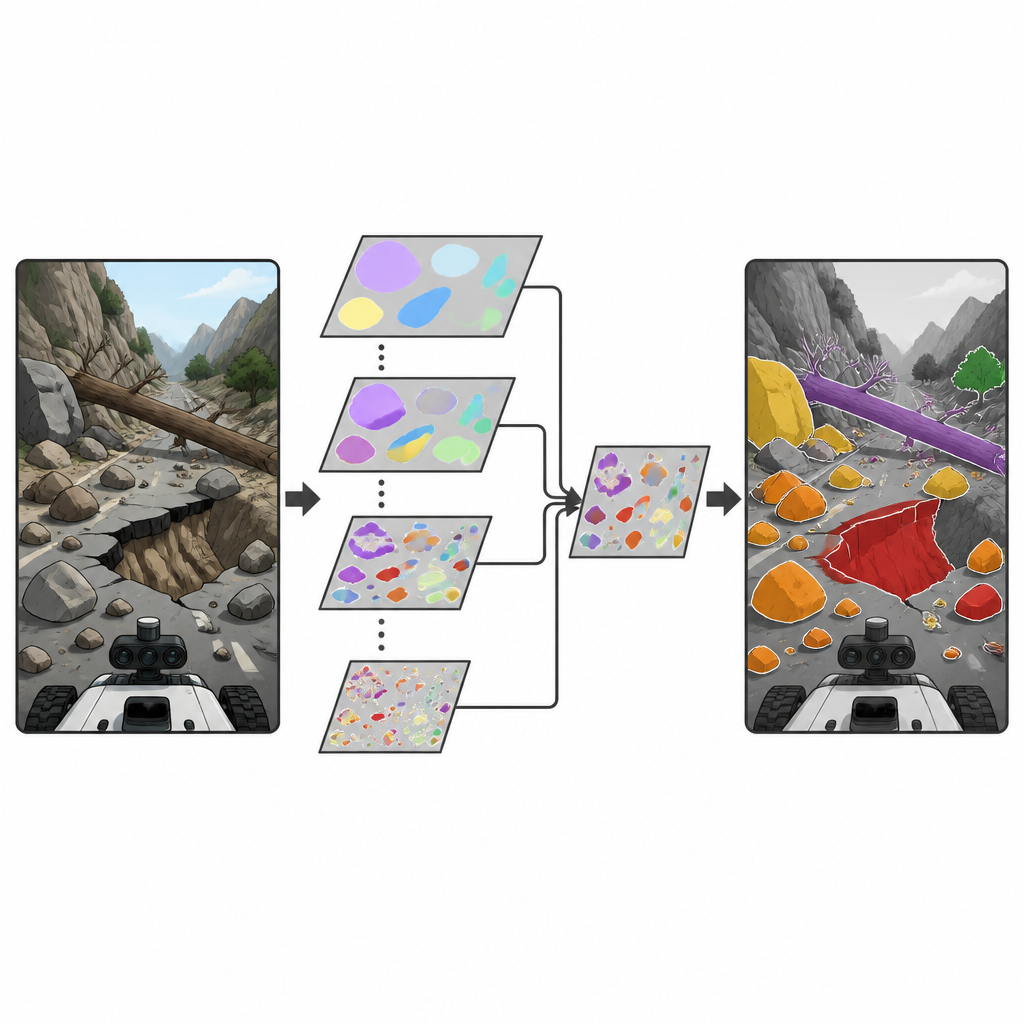
Límites y próximos pasos
A pesar de estas mejoras, los autores identifican varios problemas abiertos. El sistema actual todavía tiene dificultades con objetos extremadamente pequeños y límites confusos, por ejemplo donde las rocas y las sombras se encuentran, o donde las marcas viales y el agua de inundación se asemejan a pilas de rocas. También presta atención limitada a la escena más amplia, como si la apertura de un túnel realmente indica un colapso. El conjunto de datos procede de una sola región, por lo que el rendimiento en climas y paisajes muy distintos es incierto, y el modelo aún no se ha probado en un robot en movimiento real, donde la velocidad, el consumo de energía y la fiabilidad frente a vibraciones y polvo son factores determinantes.
Qué significa esto para futuros rescates
En conjunto, el estudio presenta una herramienta de visión compacta que ayuda a los robots de rescate a identificar mejor rasgos de terreno peligrosos sin necesitar ordenadores pesados. Al combinar vistas multiescala de la escena con una estrategia de atención eficiente, el modelo DSSKA-YOLOv8n se acerca a la precisión de detectores grandes mientras sigue siendo adecuado para máquinas pequeñas y con energía limitada. Con datos de entrenamiento más amplios, mayor conciencia del contexto de la escena y pruebas en el mundo real sobre plataformas robóticas, tales sistemas podrían algún día ofrecer a los equipos de respuesta información más rápida y segura sobre taludes inestables y carreteras dañadas en las horas cruciales tras un desastre.
Cita: Ren, K., Xiao, X., Ma, J. et al. A lightweight and cross-scale attention network for geological hazard detection in rescue robotics. Sci Rep 16, 14916 (2026). https://doi.org/10.1038/s41598-026-45112-0
Palabras clave: peligros geológicos, robots de rescate, detección de objetos, redes de atención, monitoreo de deslizamientos