Clear Sky Science · de
Ein leichtgewichtiges und skalenübergreifendes Aufmerksamkeitsnetzwerk zur Erkennung geologischer Gefahren in Rettungsrobotern
Intelligentere Roboter für gefährliches Gelände
Wenn Erdbeben, starke Regenfälle oder Straßenschnitte Steinschlag und Erdrutsche auslösen, ist es oft zu gefährlich für Menschen, beschädigte Hänge und Straßenabschnitte zu erkunden. Diese Studie zeigt, wie ein neues „leichtgewichtiges“ Sichtsystem kleinen Rettungsrobotern helfen kann, in solchen chaotischen Szenen schnell gefährliche Hindernisse und Bodenversagen zu erkennen — selbst wenn die Roboter nur begrenzte Rechenleistung an Bord haben.
Warum das Erkennen von Gefahren so schwierig ist
Geologische Gefahren treten in der realen Welt in vielen Formen und Größen auf: ein einzelner loser Felsblock, ein eingestürzter Straßenrand, ein abrutschender Hang oder ein querliegender Baum. Farben und Texturen gehen oft im umliegenden Gelände unter, und schlechtes Wetter, Staub und Vegetation verschlechtern die Sicht zusätzlich. Rettungsroboter müssen mit kompakten Rechnern und begrenzten Akkus auskommen und können daher keine großen, energieintensiven KI-Modelle betreiben. Bestehende Erkennungssysteme übersehen entweder kleine oder verwirrende Ziele oder sind zu schwergewichtig, um effizient auf einem Feldroboter zu laufen.

Ein neuer Ansatz, die Robotersicht zu fokussieren
Die Forschenden bauen auf einer populären Familie von Echtzeit-Objektdetektoren auf, bekannt als YOLO, die weit verbreitet zum Finden von Objekten in Bildern und Videos eingesetzt werden. Sie führen einen neuen Baustein ein, das Depthwise Separable Selective Kernel Attention (DSSKA)-Modul, und integrieren es in ein kompaktes YOLOv8n-Netzwerk, um das DSSKA-YOLOv8n-Modell zu schaffen. Einfach gesagt erlaubt dieses Modul dem Netzwerk, dieselbe Szene durch mehrere unterschiedlich große „Fenster“ zu betrachten und dann an jedem Bildpunkt automatisch zu entscheiden, welche Fenstergröße am wichtigsten ist. Durch eine sparsame Form der Berechnung bleibt die Zahl der trainierbaren Parameter klein, während die Fähigkeit des Modells geschärft wird, sowohl winzige Steine als auch großflächige Hangrutschungen zu erkennen.
Training an realen Bergszenen
Um ihren Ansatz zu testen, stellten die Forschenden eine eigene Bildsammlung von gefahrenträchtigen Bergstraßen in der Provinz Sichuan, China, zusammen. Der Datensatz enthält vier Hauptgefahrenarten: Steinschlag, umgestürzte Bäume, Erdrutsche und Straßeneinbrüche. Sie erweiterten und balancierten diese Sammlung durch sorgfältige Bildverarbeitung, etwa durch Rotationen, Anpassung der Beleuchtung und Simulation von Unschärfe oder teilweiser Verdeckung, um schlechtes Wetter und überladene Szenen nachzuahmen. Das Modell wurde anschließend unter kontrollierten Bedingungen trainiert und geprüft, wobei standardisierte Maße verwendet wurden, die sowohl Trefferhäufigkeit als auch Genauigkeit der Begrenzungen bewerten.
Wie gut das neue Modell abschneidet
Verglichen mit dem ursprünglichen YOLOv8n-Netzwerk verbessert DSSKA-YOLOv8n die Gesamterkennungsqualität und vergrößert die Modellgröße nur geringfügig. Es übertrifft außerdem eine andere Version mit einem traditionelleren Aufmerksamkeitsmodul, jedoch mit etwa 61 Prozent weniger Parametern. Über alle vier Gefahrenarten erzielt das neue Modell hohe Präzision und starke Werte in anspruchsvollen Tests, die genaue Erkennung über verschiedene Überlappungsstufen zwischen Vorhersagen und Ground-Truth belohnen. Es erweist sich insbesondere bei klareren Mustern wie eingestürzten Straßen und großen Erdrutschen als besonders effektiv, während sehr unregelmäßige Steinschläge und Baumstämme, die im Hintergrund verschwimmen, weiterhin schwieriger sind. Visuelle Inspektionen zeigen, dass das verbesserte Netzwerk sich stärker auf Umrisse und Texturen echter Gefahren konzentriert und weniger Fehlalarme und verpasste kleine Ziele produziert als die Ausgangsbasis.
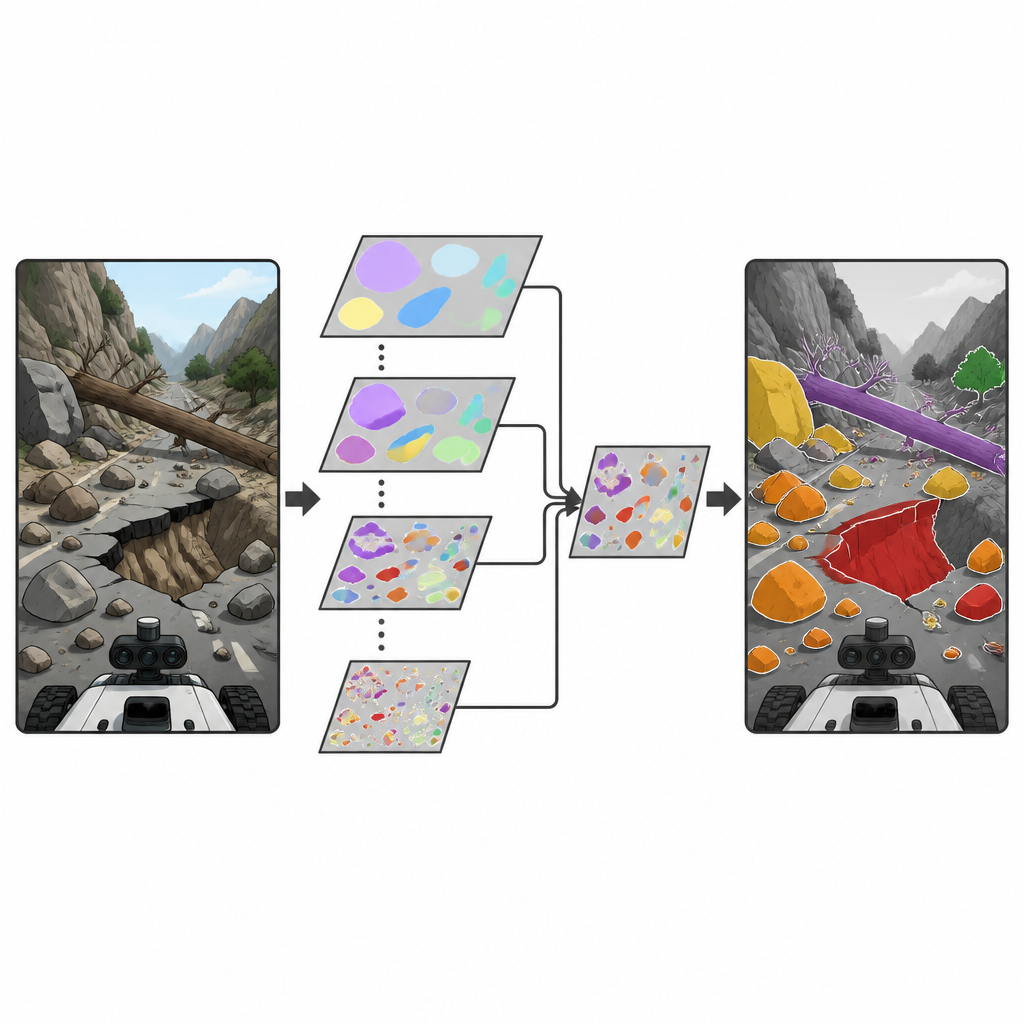
Beschränkungen und nächste Schritte
Trotz dieser Fortschritte identifizieren die Autorinnen und Autoren mehrere offene Probleme. Das aktuelle System hat weiterhin Schwierigkeiten mit extrem kleinen Objekten und verwirrenden Grenzen, etwa dort, wo sich Felsen und Schatten treffen oder wo Fahrbahnmarkierungen und Hochwasser Steinhaufen ähneln. Es richtet außerdem nur begrenzt Aufmerksamkeit auf die weitere Szene, etwa ob eine Tunneleinfahrt tatsächlich einen Einsturz signalisiert. Der Datensatz stammt aus einer einzigen Region, sodass die Leistung in sehr unterschiedlichen Klimaten und Landschaften unsicher ist, und das Modell wurde noch nicht auf einem tatsächlich fahrenden Roboter getestet, wo Geschwindigkeit, Energieverbrauch sowie Zuverlässigkeit unter Vibration und Staub entscheidend sind.
Was das für künftige Rettungseinsätze bedeutet
Insgesamt präsentiert die Studie ein kompaktes Sichtwerkzeug, das Rettungsrobotern hilft, gefährliche Geländemerkmale besser herauszuheben, ohne schwergewichtige Rechner zu benötigen. Durch die Kombination mehrskaliger Sichten der Szene mit einer effizienten Aufmerksamkeitsstrategie nähert sich das DSSKA-YOLOv8n-Modell der Genauigkeit großer Detektoren an, bleibt dabei jedoch für kleine, energiebegrenzte Geräte geeignet. Mit umfangreicherem Trainingsmaterial, zusätzlichem Kontextbewusstsein der Szene und realen Tests auf Roboterplattformen könnten solche Systeme eines Tages Einsatzkräften in den entscheidenden Stunden nach einer Katastrophe schnellerere und sicherere Einsichten in instabile Hänge und beschädigte Straßen liefern.
Zitation: Ren, K., Xiao, X., Ma, J. et al. A lightweight and cross-scale attention network for geological hazard detection in rescue robotics. Sci Rep 16, 14916 (2026). https://doi.org/10.1038/s41598-026-45112-0
Schlüsselwörter: geologische Gefahren, Rettungsroboter, Objekterkennung, Aufmerksamkeitsnetzwerke, Erdrutschüberwachung