Clear Sky Science · ar
شبكة انتباه خفيفة وعبر مقاييس للكشف عن المخاطر الجيولوجية في روبوتات الإنقاذ
روبوتات أكثر ذكاءً للأراضي الخطرة
عندما تؤدي الزلازل أو الأمطار الغزيرة أو القص في الطرق إلى سقوط الصخور والانهيارات الأرضية، غالبًا ما يكون استكشاف المنحدرات والطرقات المتضررة خطيرًا على البشر. تُظهر هذه الدراسة كيف يمكن لنظام رؤية "خفيف" جديد أن يساعد روبوتات الإنقاذ الصغيرة على رصد العقبات الخطرة وفشل الأرض بسرعة في مثل هذه المشاهد الفوضوية، حتى عندما تمتلك هذه الروبوتات قدرة حوسبة محدودة على متنها.
لماذا يكون رصد المخاطر صعبًا للغاية
تأتي المخاطر الجيولوجية في العالم الحقيقي بأشكال وأحجام متعددة: صخرة مفردة متحررة، حافة طريق منهارة، انزلاق تربة تام، أو شجرة ساقطة عبر مسار. غالبًا ما تندمج ألوانها وملمسها مع التضاريس المحيطة، ويجعل الطقس السيئ والغبار والنباتات المشهد أكثر فوضى. يجب أن تعمل روبوتات الإنقاذ بحواسيب وبطاريات مدمجة، لذا لا يمكنها تشغيل نماذج ذكاء اصطناعي ضخمة تستهلك طاقة كبيرة. الأنظمة الحالية إما تفوّت الأهداف الصغيرة أو المربكة أو تكون ثقيلة جدًا بحيث لا تعمل بكفاءة على روبوت ميداني.

طريقة جديدة لتركيز رؤية الروبوت
يبني الباحثون على عائلة شائعة من كاشفات الأجسام في الوقت الحقيقي المعروفة باسم YOLO، المستخدمة على نطاق واسع لاكتشاف الأشياء في الصور والفيديو. يقدمون كتلة بناء جديدة تسمى وحدة الانتباه الاختيارية قابلة للفصل بحسب العمق (Depthwise Separable Selective Kernel Attention - DSSKA)، ثم يدمجونها في شبكة YOLOv8n مدمجة لإنشاء نموذج DSSKA-YOLOv8n. ببساطة، تتيح هذه الوحدة للشبكة النظر إلى المشهد نفسه من خلال عدة "نوافذ" ذات أحجام مختلفة ثم تقرر تلقائيًا أي حجم نافذة هو الأكثر أهمية عند كل نقطة في الصورة. وباستخدام شكل مقتصد من العمليات الحسابية، تحافظ على عدد الإعدادات القابلة للتعلّم صغيرًا بينما تُحسّن قدرة النموذج على ملاحظة الصخور الصغيرة وفشل المنحدرات الواسعة على حد سواء.
التدريب على مشاهد جبلية حقيقية
لاختبار نهجهم، جمع الفريق مجموعة صور مخصصة من طرق جبلية معرضة للمخاطر في مقاطعة سيتشوان، الصين. تحتوي مجموعة البيانات على أربعة أنواع رئيسية من المخاطر: سقوط الصخور، الأشجار الساقطة، الانهيارات الأرضية، وانهيارات الطريق. وسّعوا ووازنوا هذه المجموعة بمعالجة صور دقيقة مثل تدوير المشاهد، تغيير الإضاءة، ومحاكاة التمويه أو الانسداد الجزئي لمحاكاة الطقس السيئ والمشاهد المزدحمة. ثم تم تدريب النموذج وفحصه في ظروف مضبوطة، باستخدام مقاييس قياسية لمعدل اكتشاف المخاطر بدقة ومدى تحديدها.
مدى أداء النموذج الجديد
بالمقارنة مع شبكة YOLOv8n الأصلية، يرفع DSSKA-YOLOv8n جودة الكشف العامة مع زيادة بسيطة فقط في حجم النموذج. كما يتفوق على نسخة أخرى تستخدم وحدة انتباه تقليدية أكثر، مع نحو 61 بالمئة أقل من المعاملات. عبر الأنواع الأربعة من المخاطر، يصل النموذج الجديد إلى دقة عالية ونتائج قوية في اختبارات صارمة تكافئ الكشف الدقيق عند مستويات تداخل متعددة بين التنبؤات والواقع الأرضي. يثبت فعاليته بشكل خاص للأنماط الواضحة مثل الطرق المنهارة والانهيارات الأرضية الكبيرة، رغم أن سقوط الصخور غير المنتظم جدًا وجذوع الأشجار التي تندمج مع الخلفية تظل أصعب. تُظهر الفحوصات البصرية أن الشبكة المحسنة تركز بشكل أوثق على محيطات وملمس المخاطر الحقيقية وتُقلل الإنذارات الكاذبة والغيابات للأهداف الصغيرة مقارنةً بالنموذج الأساسي.
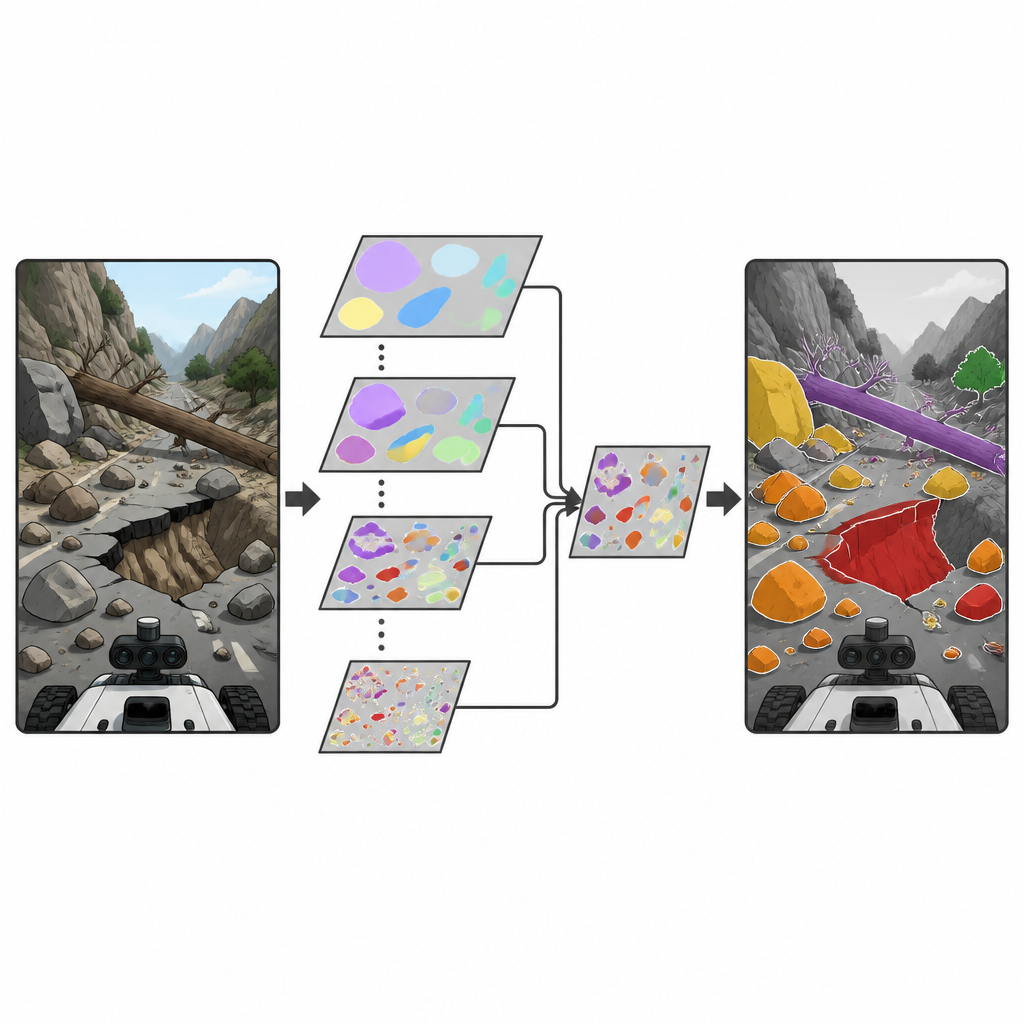
القيود والخطوات التالية
على الرغم من هذه المكتسبات، يحدد المؤلفون عدة مشكلات مفتوحة. لا يزال النظام الحالي يواجه صعوبة مع الأجسام الصغيرة للغاية والحدود المربكة، مثل الأماكن التي تلتقي فيها الصخور والظلال، أو حيث تشبه علامات الطريق ومياه الفيضانات أكوام الصخور. كما يعطي اهتمامًا محدودًا للمشهد الأوسع، مثل ما إذا كان افتتاح نفق يشير فعليًا إلى انهيار. تأتي مجموعة البيانات من منطقة واحدة، لذا فإن الأداء في مناخات وتضاريس مختلفة غير مؤكد، ولم يتم اختبار النموذج بعد على روبوت متحرك فعليًا، حيث تهم السرعة، واستهلاك الطاقة، والموثوقية تحت الاهتزاز والغبار.
ما يعنيه ذلك لعمليات الإنقاذ المستقبلية
بشكل عام، تقدم الدراسة أداة رؤية مدمجة تساعد روبوتات الإنقاذ على تمييز معالم التضاريس الخطرة بشكل أفضل دون الحاجة إلى حواسيب ثقيلة. من خلال الجمع بين مشاهد متعددة المقاييس للمشهد واستراتيجية انتباه فعّالة، يقترب نموذج DSSKA-YOLOv8n من دقة الكاشفات الكبيرة بينما يظل مناسبًا للأجهزة الصغيرة محدودة الطاقة. مع بيانات تدريب أوسع، وزيادة الوعي بسياق المشهد، والاختبار الواقعي على منصات روبوتية، قد تمنح هذه الأنظمة المستجيبين يومًا ما رؤية أسرع وأكثر أمانًا للمنحدرات غير المستقرة والطرق المتضررة في الساعات الحرجة بعد الكارثة.
الاستشهاد: Ren, K., Xiao, X., Ma, J. et al. A lightweight and cross-scale attention network for geological hazard detection in rescue robotics. Sci Rep 16, 14916 (2026). https://doi.org/10.1038/s41598-026-45112-0
الكلمات المفتاحية: المخاطر الجيولوجية, روبوتات الإنقاذ, كشف الأجسام, شبكات الانتباه, مراقبة الانهيارات الأرضية