Clear Sky Science · en
A lightweight and cross-scale attention network for geological hazard detection in rescue robotics
Smarter robots for dangerous lands
When earthquakes, heavy rains, or road cuts trigger rockfalls and landslides, it is often too risky for people to scout damaged slopes and roads. This study shows how a new “lightweight” vision system can help small rescue robots quickly spot dangerous obstacles and ground failures in such chaotic scenes, even when the robots have only limited onboard computing power.
Why spotting hazards is so hard
Geological hazards in the real world come in many shapes and sizes: a single loose boulder, a collapsed road edge, a hillside giving way, or a tree lying across a lane. Their colors and textures often blend into the surrounding terrain, and bad weather, dust, and vegetation make the view even messier. Rescue robots must work with compact computers and batteries, so they cannot run huge, power-hungry artificial intelligence models. Existing detection systems either miss small or confusing targets or are too heavy to run efficiently on a robot in the field.

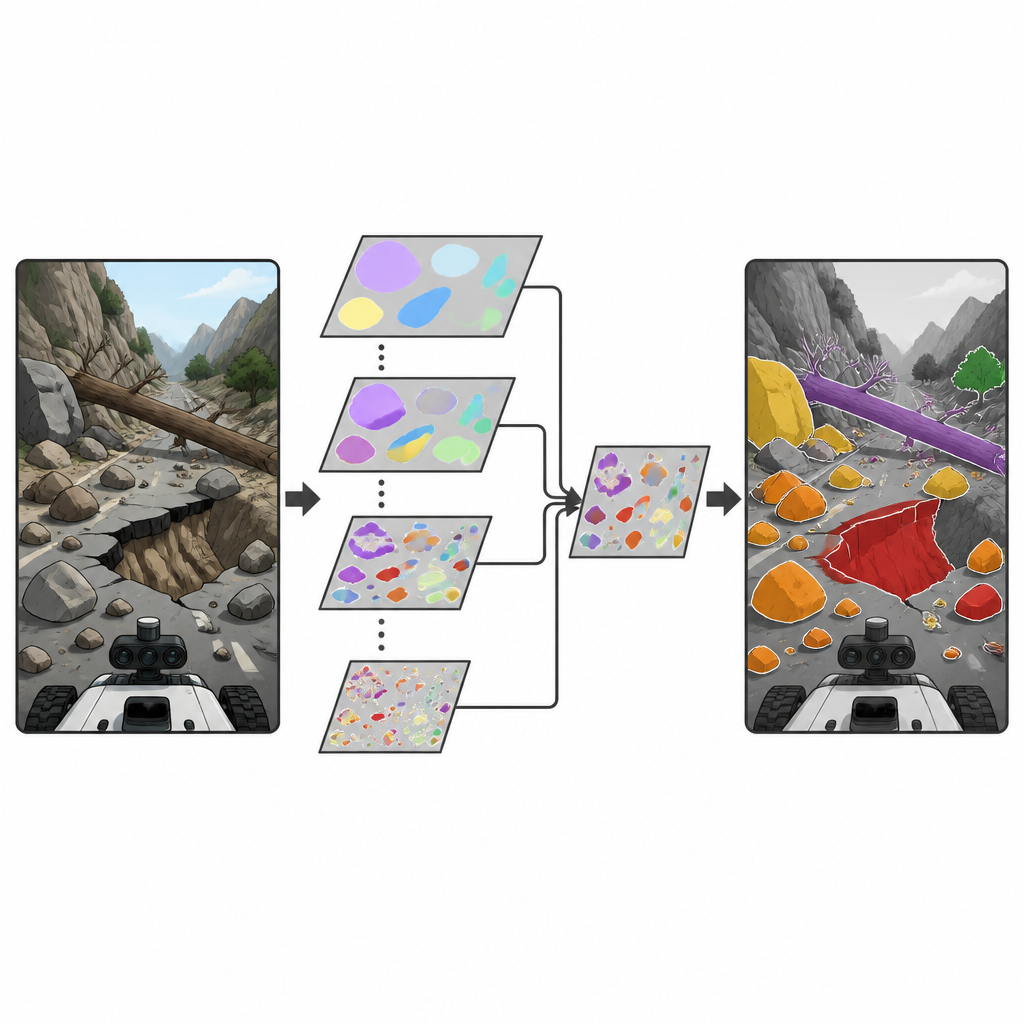
A new way to focus robot vision
The researchers build on a popular family of real-time object detectors known as YOLO, widely used for finding objects in images and video. They introduce a new building block called the Depthwise Separable Selective Kernel Attention (DSSKA) module, then plug it into a compact YOLOv8n network to create the DSSKA-YOLOv8n model. In plain terms, this module lets the network look at the same scene through several differently sized “windows” and then automatically decide which window size matters most at each point in the image. By using a lean form of calculation, it keeps the number of trainable settings small while sharpening the model’s ability to notice both tiny rocks and broad slope failures.
Training on real mountain scenes
To test their approach, the team assembled a custom image collection from hazard-prone mountain roads in Sichuan Province, China. The dataset contains four main types of danger: rockfalls, fallen trees, landslides, and road collapses. They expanded and balanced this collection with careful image processing, such as rotating views, changing lighting, and simulating blur or partial blockage, to mimic bad weather and cluttered scenes. The model was then trained and checked under controlled conditions, using standard measures of how often it finds hazards correctly and how precisely it outlines them.
How well the new model performs
Compared with the original YOLOv8n network, DSSKA-YOLOv8n raises overall detection quality while increasing the model size by only a small margin. It also outperforms another version that uses a more traditional attention module, but with about 61 percent fewer parameters. Across all four hazard types, the new model reaches high precision and strong scores on demanding tests that reward accurate detection at many overlap levels between predictions and ground truth. It proves especially effective for clearer patterns like collapsed roads and large landslides, though very irregular rockfalls and tree trunks that blend into the background remain more difficult. Visual inspections show that the improved network focuses more tightly on the outlines and textures of true hazards and makes fewer false alarms and missed small targets than the baseline.
Limits and next steps
Despite these gains, the authors identify several open problems. The current system still struggles with extremely small objects and confusing boundaries, for example where rocks and shadows meet, or where road markings and floodwater resemble rock piles. It also pays limited attention to the wider scene, such as whether a tunnel opening really signals a collapse. The dataset comes from a single region, so performance in very different climates and landscapes is uncertain, and the model has not yet been tested on an actual moving robot, where speed, power use, and reliability under vibration and dust all matter.
What this means for future rescues
Overall, the study presents a compact vision tool that helps rescue robots better pick out dangerous terrain features without needing heavyweight computers. By combining multi-scale views of the scene with an efficient attention strategy, the DSSKA-YOLOv8n model edges closer to the accuracy of large detectors while remaining suitable for small, energy-limited machines. With broader training data, added awareness of scene context, and real-world testing on robot platforms, such systems could one day give responders faster, safer insight into unstable slopes and damaged roads in the crucial hours after a disaster.
Citation: Ren, K., Xiao, X., Ma, J. et al. A lightweight and cross-scale attention network for geological hazard detection in rescue robotics. Sci Rep 16, 14916 (2026). https://doi.org/10.1038/s41598-026-45112-0
Keywords: geological hazards, rescue robots, object detection, attention networks, landslide monitoring