Clear Sky Science · pl
AMR-GNN: wieloreprezentacyjny framework grafowych sieci neuronowych umożliwiający przewidywanie genomowego oporu na antybiotyki
Dlaczego przewidywanie oporności na leki ma znaczenie
Infekcje oporne na antybiotyki są jednym z największych zagrożeń medycznych naszych czasów, zabijając ponad milion osób rocznie. Lekarze pilnie potrzebują szybszych sposobów ustalania, które antybiotyki będą skuteczne w danym przypadku, lecz tradycyjne testy laboratoryjne mogą trwać kilka dni. W badaniu przedstawiono nowe rozwiązanie oparte na sztucznej inteligencji, nazwane AMR-GNN, które analizuje pełną sekwencję DNA bakterii i przewiduje, czy będą one oporne czy wrażliwe na różne antybiotyki — co może umożliwić poradę już tego samego dnia przy łóżku pacjenta.
Od powolnych hodowli do cyfrowych testów DNA
Dziś większość szpitali wciąż polega na testach opartych na hodowli: bakterie są namnażane w laboratorium i wystawiane na działanie różnych leków, aby sprawdzić, które z nich hamują wzrost. Choć metoda ta jest wiarygodna, jest też powolna i pracochłonna. Równocześnie sekwencjonowanie całych genomów bakteryjnych stało się tańsze i łatwiejsze, generując ogromne ilości szczegółowych danych. Wyzwanie polega na tym, że DNA bakterii jest niezwykle wysokowymiarowe, zawiera miliony elementów budulcowych i nie istnieje jedna powszechnie przyjęta metoda przekształcenia tego kodu genetycznego w format, który komputery łatwo wykorzystają do przewidywania oporności. Wcześniejsze narzędzia często koncentrowały się na kilku znanych genach oporności lub prostych wzorcach, co dobrze działa, gdy oporność wynika z pojedynczej mutacji, ale zawodzi, gdy wiele subtelnych zmian wchodzi ze sobą w interakcje.
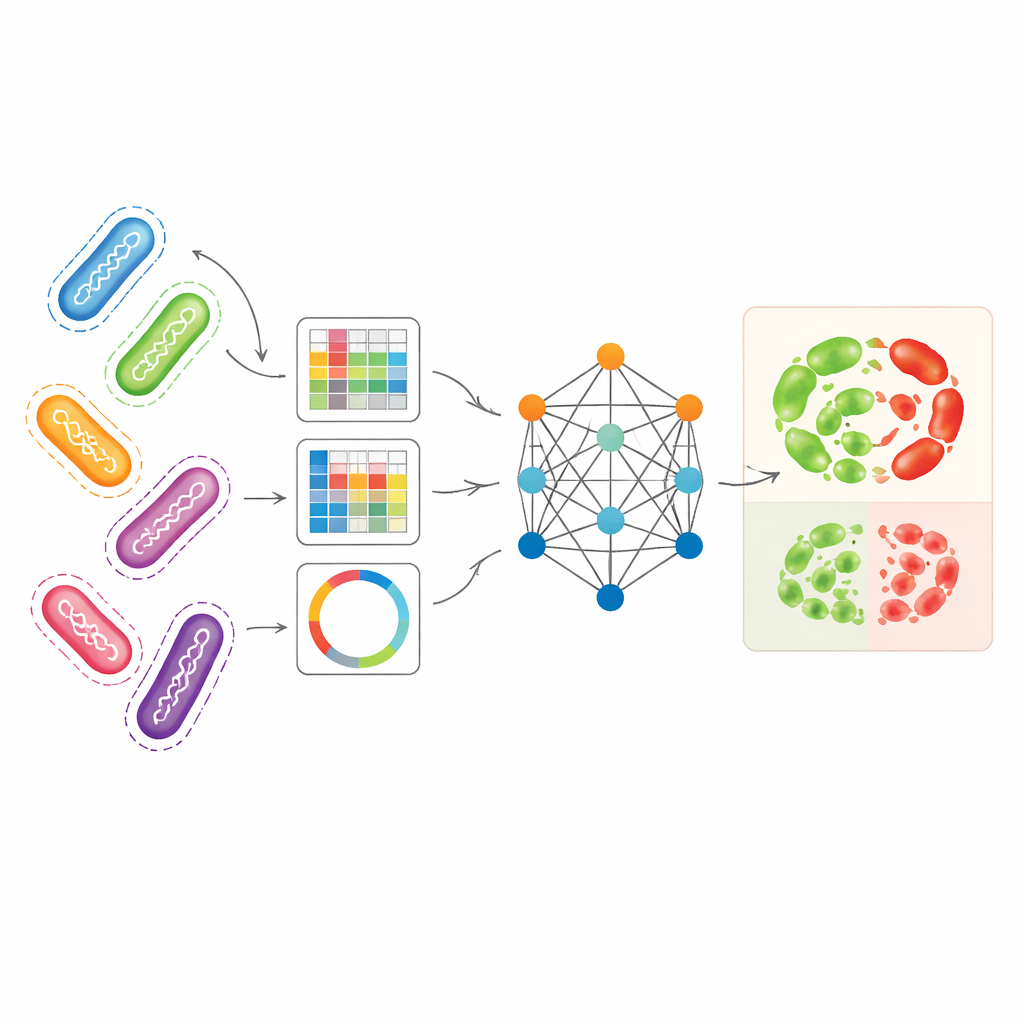
Łączenie różnych genomowych perspektyw w jedną całość
Badacze postanowili wykorzystać kilka komplementarnych sposobów reprezentacji genomów bakterii jednocześnie. Jako główny przypadek testowy wybrali Pseudomonas aeruginosa — patogen szpitalny o szczególnie złożonych wzorcach oporności. Jedna reprezentacja, zwana unitigami, wychwytuje powtarzające się fragmenty DNA bez odwoływania się do genomu referencyjnego. Inna śledzi drobne zmiany DNA w konkretnych pozycjach, a trzecia przekształca wybrane geny związane z opornością w układy przypominające obrazy, podsumowujące sposób, w jaki krótkie odcinki DNA są ułożone. Każda z tych reprezentacji pozwalała samodzielnie standardowym modelom uczenia maszynowego przewidywać oporność z przyzwoitą dokładnością, szczególnie unitigi dla niektórych antybiotyków. Jednak każda z perspektyw pomija fragment biologicznej historii, a używanie ich oddzielnie niedostatecznie wykorzystuje bogactwo danych genomowych.
Jak model oparty na grafie uczy się od powiązanych szczepów
AMR-GNN wykorzystuje formę głębokiego uczenia znaną jako grafowa sieć neuronowa, która traktuje każdy izolowany szczep bakteryjny jako punkt (węzeł) i łączy izolaty genetycznie podobne za pomocą linków (krawędzi). W tym układzie szczegółowy profil unitigów każdego izolatu stanowi jego główny wektor cech, podczas gdy inne widoki genomowe definiują, jak izolaty są połączone w grafie. Model następnie przekazuje informacje wzdłuż tych połączeń, co pozwala mu uczyć się wzorców wspólnych dla spokrewnionych genomów. Aby uniknąć wprowadzania w błąd przez proste relacje klonalne — gdzie bakterie są blisko spokrewnione, ale różnią się opornością z powodów, które model powinien odkryć — autorzy świadomie usunęli krawędzie łączące izolaty z tej samej grupy liniowej genetycznej. Ten krok „odłączenia” zmusza sieć do zwracania większej uwagi na konkretne cechy DNA związane z opornością, zamiast polegać na szerokich etykietach linii jako skrótach.
Mocniejsze przewidywania w różnych bakteriach i wobec różnych leków
Gdy zespół porównał AMR-GNN z prostszymi modelami opartymi na pojedynczych widokach genomowych, podejście oparte na grafach poprawiło wyniki dla niemal wszystkich z 12 testowanych antybiotyków w P. aeruginosa, z największymi zyskami dla leków, które poprzednio najtrudniej było przewidzieć. Model lepiej uogólniał także na niezależne zestawy testowe, chociaż wydajność wciąż nieco spadała poza danymi treningowymi, co podkreśla potrzebę większych i bardziej zróżnicowanych zbiorów genomów. Poza P. aeruginosa badacze zastosowali AMR-GNN do ponad 23 000 genomów innych ważnych patogenów, w tym Escherichia coli, Klebsiella pneumoniae, Staphylococcus aureus i Enterococcus faecium, obejmując wiele klinicznie istotnych antybiotyków. W większości par gatunek–lek framework osiągnął bardzo wysoką dokładność i przewyższył szeroko stosowane narzędzia oparte na regułach, które polegają na skurowanych listach znanych genów oporności.
Uczynienie modeli „czarnej skrzynki” bardziej wytłumaczalnymi
Istotnym problemem w zastosowaniach klinicznych jest to, czy taki system AI może dostarczyć wglądu, dlaczego wydaje konkretne przewidywanie. Zespół rozwiązał to, stosując metody interpretowalności, które śledzą, które cechy DNA najbardziej przyczyniają się do decyzji modelu. Dla leków, przy których model osiągał najlepsze wyniki, AMR-GNN wskazał wiele znanych genów i mutacji oporności, takich jak klasyczne cele antybiotyków fluorochinolonowych. Wskazał też mniej poznane geny, których zmiany były silnie powiązane z wyższymi stężeniami leku potrzebnymi do zahamowania wzrostu bakterii, sugerując nowe kandydatury do badań laboratoryjnych. Ta zdolność zarówno do przewidywania oporności, jak i do wskazywania potencjalnych biologicznych mechanizmów pomaga zmniejszyć dystans między czystą predykcją a zrozumieniem mechanistycznym.
Co to oznacza dla przyszłej opieki nad pacjentem
W istocie praca ta pokazuje, że łączenie wielu „widoków” DNA w ramach grafowego modelu głębokiego uczenia może znacznie poprawić przewidywanie oporności na antybiotyki na podstawie genomów bakteryjnych. AMR-GNN przedstawiono jako elastyczny, możliwy do interpretacji framework, który można rozszerzać na inne typy danych, takie jak pomiary aktywności genów czy informacje kliniczne. Choć potrzeba dalszych badań — zwłaszcza większych, geograficznie zróżnicowanych zbiorów danych i prospektywnych badań klinicznych — podejście to przybliża nas do przyszłości, w której sekwencja genomu bakteryjnego, uzyskana bezpośrednio z próbki pacjenta, mogłaby szybko ukierunkować lekarzy na właściwy lek i pomóc spowolnić rozprzestrzenianie się opornych infekcji.
Cytowanie: Nguyen, HA., Peleg, A.Y., Wisniewski, J.A. et al. AMR-GNN: a multi-representation graph neural network framework to enable genomic antimicrobial resistance prediction. Nat Commun 17, 3555 (2026). https://doi.org/10.1038/s41467-026-69934-8
Słowa kluczowe: oporność na środki przeciwdrobnoustrojowe, grafowe sieci neuronowe, genomika bakterii, uczenie maszynowe, predykcja wrażliwości na antybiotyki