Clear Sky Science · ja
バッファ付き棄却による差分プライバシー確保型確率的勾配降下法における更新の安定化
なぜプライベート学習が重要か
現代のアプリは大量の写真、医療記録、個人的なメッセージから学習します。これらのデータは機械学習モデルを賢くしますが、同時にリスクも生じます:モデルが学習元の個人について何かを意図せず明らかにしてしまう可能性があるのです。差分プライバシーはこれを防ぐための数学的手法の集合です。本概要の元となる論文は、強いプライバシー保証を維持しつつ、プライバシー保護のために加えられるノイズで通常損なわれる精度の一部を回復する方法を提示しています。
ノイズの多い学習の難しさ
個人を保護するため、差分プライバシーに基づく学習は学習の各小さなステップにランダムなノイズを注入します。このノイズは単一の個人の寄与を隠しますが、学習を難しくもします:モデルの更新が不安定になり、進展が遅くなり、非プライベートな学習と比べて最終的な精度が下がります。以前の手法はより選択的になろうとし、小さな検証バッチで役に立たなさそうな更新をスキップしました。しかし、その判断も単一のノイズを含む測定に依存していたため、有益な更新が破棄されたり、逆に悪い更新が誤って受け入れられたりして、データアクセス量を管理する限られた「プライバシー予算」が無駄になることがありました。
小さなメモリでより良い一歩を選ぶ
著者らはDPSGD-BRというアルゴリズムを提案し、モデルがどの学習ステップを保持するかを決める仕組みを変えます。候補の更新を一度に一つ評価するのではなく、この手法は既に簡易なプライベートチェックを通過した有望な候補を2つだけ保持する小さなバッファを使います。そして、そのノイズを含む損失低減を比較して、より有用に見える方を選び、同等に見える場合は確率的に選択します。この二者比較はランダム性の一部を相殺し、単一のノイズ測定への感受性を低下させます。もしフィルタが厳しすぎて連続して多くの候補が棄却されるようになると、アルゴリズムは自動的に単一候補モードに切り替え、損失面が平坦な領域や難しい領域で学習が停滞しないようにします。
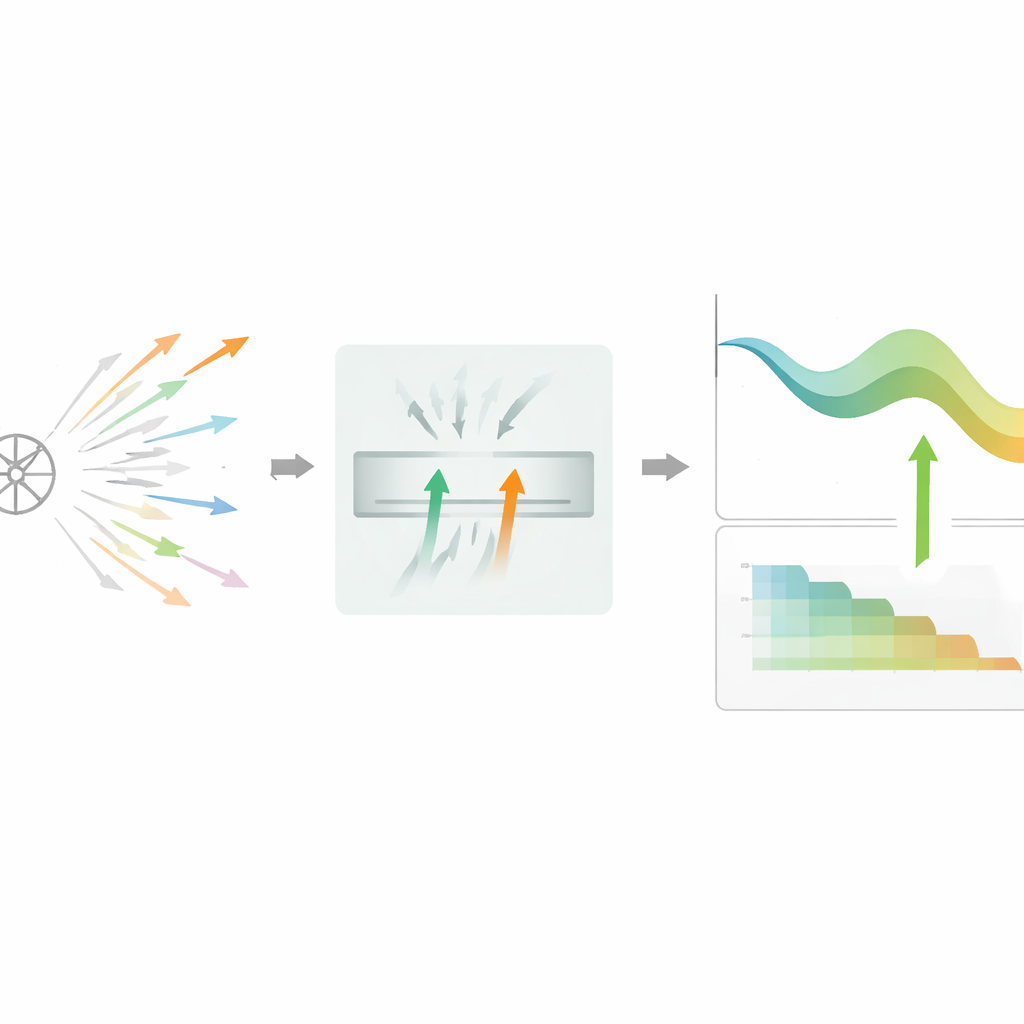
時間経過に応じたノイズと学習率の適応
より賢い選択に加え、DPSGD-BRは学習を通じて主要な調整パラメータを適応させます。各受け入れられた更新の後、検証精度がどれだけ改善したかを確認します。モデルが速く学習している間は、ノイズレベルと学習率の両方をより積極的に下げ、非常にノイズの多い初期段階からより安定した段階へ移行するのを助けます。後半、進捗が鈍化すると、これらの量をより緩やかに減衰させ、棄却ルールを緩めてより多くの更新を通すことで微調整を可能にします。これらはすべて厳格な会計フレームワークの下で行われ、消費したプライバシー予算を追跡し、事前に設定した制限に近づくとさらなる減衰を停止します。
実験が示すもの
研究者たちはDPSGD-BRをよく知られたベンチマークで評価しました:手書き数字と衣類画像の二つのデータセット(MNISTとFashion-MNIST)、より複雑な自然画像セット(CIFAR-10)、および映画レビューの感情分析(IMDb)。等しいプライバシー予算のもとで、彼らの手法は標準的な差分プライバシー学習や主要な選択的更新手法より一貫して高いテスト精度を達成し、通常は約0.5から2パーセントポイントの差がありました。また、これらの精度によりスムーズで高速な収束で到達しました。特定の個人のデータが学習に使われたかを判定しようとするメンバーシップ推論攻撃への脆弱性の測定は、ランダム推測と同等の水準に近く、精度向上が経験的プライバシーの弱化によるものではないことを示しています。
プライバシー重視の学習への示唆
簡潔に言えば、この論文は、プライベートなディープラーニングが、プライバシー予算を慎重に選ばれた更新にのみ使い、ノイズレベルを学習の段階に合わせることで、安全性と有効性を両立できることを示しています。候補となるステップを比較する小さなバッファと、学習過程を段階的に落ち着かせるスケジュールを組み合わせることで、DPSGD-BRは同じ形式的なプライバシー保証からより実用的な学習の進展を引き出します。実務者にとって、これは個人のデータを尊重しつつ、現実世界の視覚および言語タスクで競争力のある精度を維持するための現実的な道筋を示唆しています。
引用: Deng, S., Zhang, K., Zhang, W. et al. Stabilizing updates in differentially private stochastic gradient descent with buffered rejection. Sci Rep 16, 13961 (2026). https://doi.org/10.1038/s41598-026-44009-2
キーワード: 差分プライバシー, ディープラーニング, 確率的勾配降下法, プライバシー保護学習, メンバーシップ推論