Clear Sky Science · de
Stabilisierende Updates im differentially privaten stochastischen Gradientenabstieg mit gepuffertem Zurückweisen
Warum privates Lernen wichtig ist
Moderne Anwendungen lernen aus großen Sammlungen von Fotos, medizinischen Akten und persönlichen Nachrichten. Diese Daten machen Machine-Learning-Modelle leistungsfähiger, bergen aber auch Risiken: Ein Modell könnte versehentlich Informationen über die Personen preisgeben, von denen es gelernt hat. Differentielle Privatsphäre ist ein mathematisches Werkzeugset, das genau dies verhindern will. Das zu dieser Zusammenfassung gehörende Paper stellt eine Methode vor, tiefe neuronale Netze so zu trainieren, dass starke Privatsphäre-Garantien erhalten bleiben, gleichzeitig aber ein Teil der Genauigkeit wiedergewonnen wird, die durch das für Privatsphäre notwendige Rauschen sonst verloren geht.
Die Herausforderung des verrauschten Trainings
Um Individuen zu schützen, fügen differentially private Trainingsverfahren in jeden kleinen Schritt, den das Modell beim Lernen macht, zufälliges Rauschen ein. Dieses Rauschen verschleiert den Beitrag einer einzelnen Person an den Daten, erschwert aber zugleich das Lernen: Die Modell-Updates werden unregelmäßig, der Fortschritt verlangsamt sich und die Endgenauigkeit sinkt im Vergleich zum nicht-privaten Training. Frühere Ansätze versuchten selektiver zu sein, indem sie Updates übersprangen, die auf einer kleinen Validierungsmenge unvorteilhaft erschienen. Solche Entscheidungen beruhten jedoch weiterhin auf einer einzigen verrauschten Messung, sodass gute Updates verworfen und schlechte fälschlich angenommen werden konnten — und dabei das knappe “Privatsphäre-Budget”, das den erlaubten Datenzugriff regelt, verschwendet wurde.
Bessere Schritte auswählen mit kleinem Speicher
Die Autorinnen und Autoren schlagen DPSGD-BR vor, einen Algorithmus, der ändert, wie das Modell entscheidet, welche Lernschritte beibehalten werden. Anstatt einen Kandidaten-Update nach dem anderen zu bewerten, hält die Methode einen winzigen Puffer von zwei vielversprechenden Kandidaten, die bereits eine schnelle private Prüfung passiert haben. Anschließend vergleicht sie deren verrauschte Verlustreduktionen und bevorzugt denjenigen, der hilfreicher erscheint, wobei sie bei gleichwertigem Ergebnis teilweise zufällig wählt. Dieser Zwei-Wege-Vergleich hebt einen Teil der Zufälligkeit auf und macht Entscheidungen weniger empfindlich gegenüber einer einzelnen verrauschten Messung. Wird der Filter zu streng und viele Kandidaten hintereinander abgelehnt, wechselt der Algorithmus automatisch in einen einfacheren Ein-Kandidaten-Modus, damit das Training in flachen oder schwierigen Bereichen der Verlustoberfläche nicht zum Stillstand kommt.
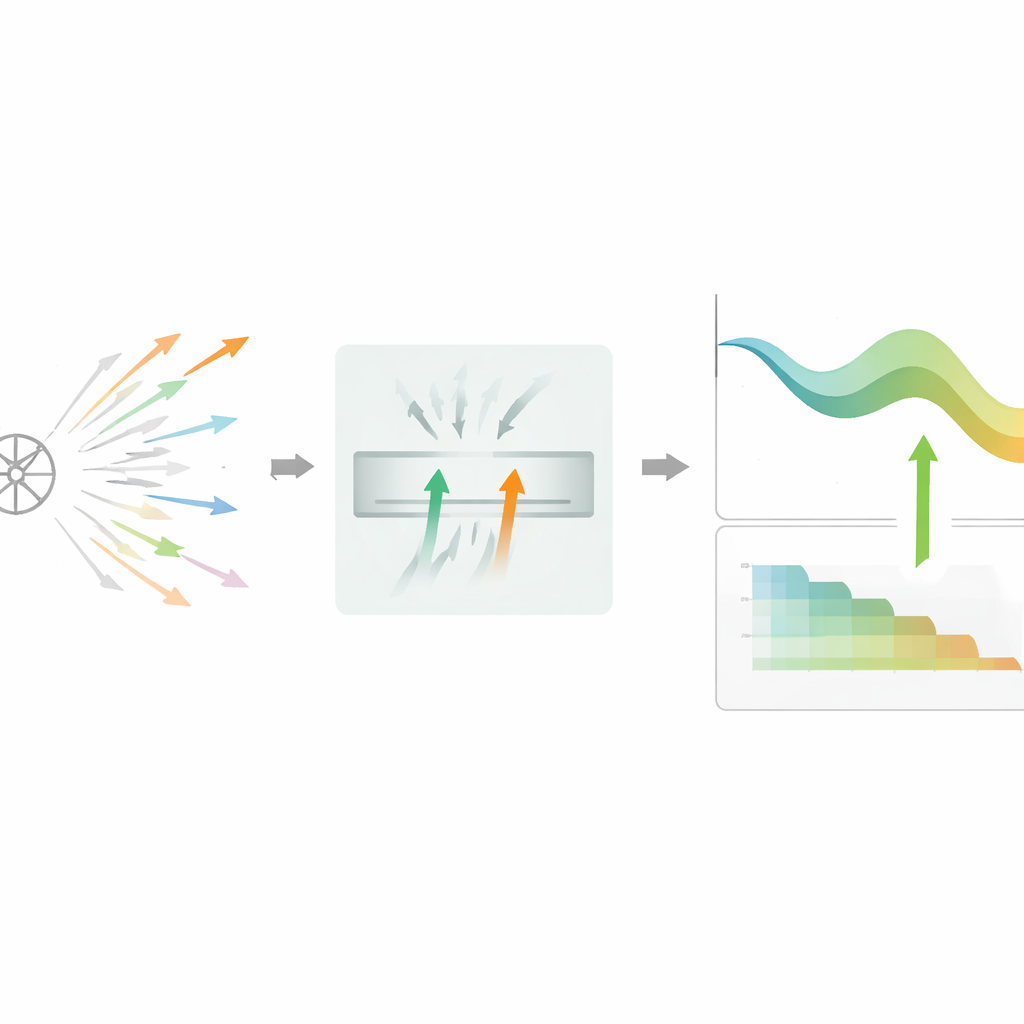
Anpassung von Rauschen und Schrittgröße über die Zeit
Über die intelligentere Auswahl hinaus passt DPSGD-BR auch seine zentralen Stellgrößen im Verlauf des Trainings an. Nach jedem akzeptierten Update prüft es, wie stark die Validierungsgenauigkeit sich verbessert hat. Lernt das Modell schnell, reduziert die Methode sowohl das Rauschen als auch die Lernrate aggressiver, um aus einer sehr verrauschten frühen Phase in ein stabileres Regime zu kommen. Später, wenn der Fortschritt langsamer wird, dämpft sie diese Größen sanfter und lockert die Zurückweisungsregel, sodass mehr Updates durchgelassen werden und das Modell feiner abgestimmt werden kann. All das geschieht unter einem strengen Abrechnungsrahmen, der verfolgt, wie viel Privatsphäre-Budget verbraucht wurde, und weiteres Absenken stoppt, sobald ein voreingestelltes Limit erreicht wird.
Was die Experimente zeigen
Die Forschenden testeten DPSGD-BR auf bekannten Benchmarks: zwei Datensätze mit handgeschriebenen und Kleidungsbildern (MNIST und Fashion-MNIST), einen komplexeren Datensatz natürlicher Bilder (CIFAR-10) und Sentiment-Analyse von Filmkritiken (IMDb). Bei gleichen Privatsphäre-Budgets erreichte ihre Methode durchweg höhere Testgenauigkeit als standardmäßiges differentially private Training und ein führendes selektives-Update-Verfahren, meist um etwa eine halbe bis zwei Prozentpunkte. Sie erzielte diese Genauigkeiten außerdem mit gleichmäßigeren, schnelleren Konvergenzen. Messungen der Verwundbarkeit gegenüber Mitgliedschaftsinferenz-Angriffen — bei denen ein Angreifer versucht zu erkennen, ob die Daten einer bestimmten Person im Training verwendet wurden — blieben nahe dem Niveau zufälligen Ratens, was darauf hindeutet, dass die Genauigkeitsgewinne nicht zulasten schwächerer empirischer Privatsphäre gingen.
Fazit für privatsphärebewusstes Lernen
Kurz gesagt zeigt das Paper, dass privates Deep Learning sowohl sicherer als auch effektiver gestaltet werden kann, wenn das Privatsphäre-Budget nur für gut ausgewählte Updates eingesetzt und die Rauschpegel an die Trainingsphase angepasst werden. Mit einem winzigen Puffer, der Kandidatenschritte vergleicht, und einem Zeitplan, der den Lernprozess allmählich beruhigt, macht DPSGD-BR dieselbe formale Privatsphäre-Garantie in nützlicheren Lernfortschritt umsetzbar. Für Praktiker deutet dies auf einen praktikablen Weg hin, Modelle zu entwickeln, die die Daten von Individuen respektieren und gleichzeitig bei Genauigkeit in realen Aufgaben der Vision- und Sprachverarbeitung konkurrenzfähig bleiben.
Zitation: Deng, S., Zhang, K., Zhang, W. et al. Stabilizing updates in differentially private stochastic gradient descent with buffered rejection. Sci Rep 16, 13961 (2026). https://doi.org/10.1038/s41598-026-44009-2
Schlüsselwörter: differentielle Privatsphäre, tiefes Lernen, stochastischer Gradientenabstieg, privatsphäre-wahrendes Training, Mitgliedschaftsinferenz