Clear Sky Science · it
Stabilizzazione degli aggiornamenti nello stochastic gradient descent differenzialmente privato con rifiuto bufferizzato
Perché l’apprendimento privato è importante
Le applicazioni moderne apprendono da enormi raccolte di foto, cartelle cliniche e messaggi personali. Questi dati possono rendere i modelli di machine learning più intelligenti, ma creano anche rischi: un modello potrebbe rivelare involontariamente informazioni sulle persone da cui ha imparato. La privacy differenziale è un insieme di strumenti matematici che mira a prevenire questo. L’articolo riassunto qui introduce un modo per addestrare reti neurali profonde che mantiene forti garanzie di privacy pur recuperando parte dell’accuratezza di solito persa a causa del rumore introdotto per proteggere la privacy.
La sfida dell’addestramento rumoroso
Per proteggere gli individui, l’addestramento differenzialmente privato introduce rumore casuale in ogni piccolo passo che il modello compie durante l’apprendimento. Questo rumore nasconde il contributo di una singola persona nei dati, ma rende anche l’apprendimento più difficile: gli aggiornamenti del modello diventano instabili, i progressi rallentano e l’accuratezza finale diminuisce rispetto all’addestramento non privato. Metodi precedenti cercavano di essere più selettivi, saltando aggiornamenti che sembravano poco utili valutati su un piccolo lotto di validazione. Tuttavia, quelle decisioni dipendevano ancora da una singola misura rumorosa, perciò aggiornamenti buoni potevano essere scartati e aggiornamenti dannosi accettati accidentalmente, sprecando il limitato “budget di privacy” che governa quanto accesso ai dati è consentito.
Scegliere passi migliori con una piccola memoria
Gli autori propongono DPSGD-BR, un algoritmo che modifica il modo in cui il modello decide quali passi di apprendimento mantenere. Invece di giudicare un aggiornamento candidato per volta, il metodo mantiene un piccolo buffer di due candidati promettenti che hanno già superato un rapido controllo privato. Confronta quindi le loro riduzioni di loss rumorose e predilige quello che sembra più utile, scegliendo a volte in modo casuale se appaiono ugualmente validi. Questo confronto a due vie annulla parte della casualità, rendendo le decisioni meno sensibili a una singola lettura rumorosa. Se il filtro diventa troppo severo e molti candidati vengono rifiutati di seguito, l’algoritmo passa automaticamente a una modalità più semplice a candidato singolo in modo che l’addestramento non si blocchi vicino a regioni piatte o difficili della superficie di perdita.
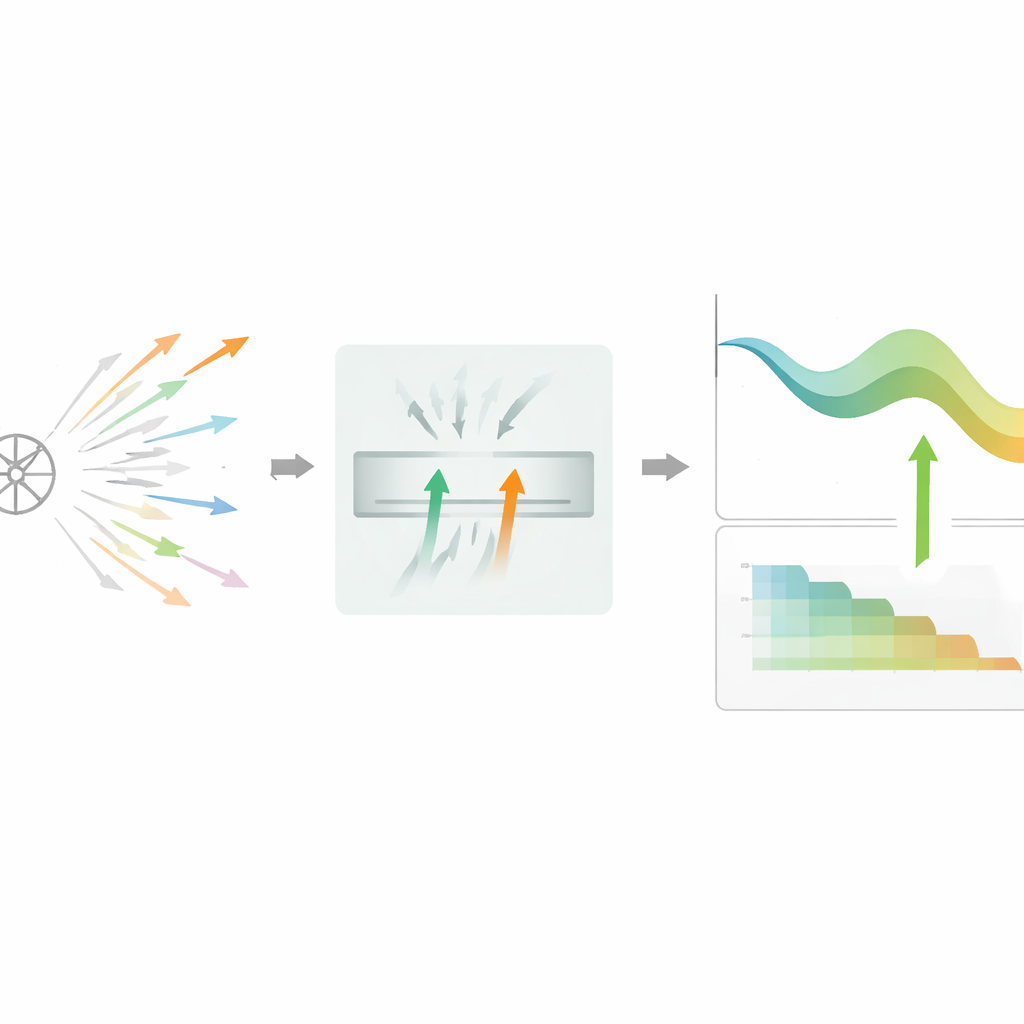
Adattare rumore e passo nel tempo
Oltre a una selezione più intelligente, DPSGD-BR adatta anche le sue impostazioni chiave durante l’addestramento. Dopo ogni aggiornamento accettato, verifica quanto è migliorata l’accuratezza sulla validazione. Quando il modello sta imparando rapidamente, il metodo riduce sia il livello di rumore sia il tasso di apprendimento in modo più aggressivo, aiutandolo a uscire da una fase iniziale molto rumorosa verso un regime più stabile. Successivamente, quando i progressi rallentano, decresce queste quantità in modo più dolce e allenta la regola di rifiuto, permettendo a più aggiornamenti di passare così che il modello possa perfezionarsi. Tutto questo avviene sotto un rigoroso quadro di rendicontazione, che tiene traccia di quanto budget di privacy è stato speso e interrompe ulteriori decrescite una volta che si avvicina un limite prestabilito.
Cosa mostrano gli esperimenti
I ricercatori hanno testato DPSGD-BR su benchmark noti: due dataset di immagini di scrittura a mano e abbigliamento (MNIST e Fashion-MNIST), un insieme di immagini naturali più complesso (CIFAR-10) e l’analisi del sentiment delle recensioni di film (IMDb). Con budget di privacy confrontabili, il loro metodo ha costantemente raggiunto una maggiore accuratezza di test rispetto all’addestramento differenzialmente privato standard e rispetto a un metodo selettivo di riferimento, solitamente con un miglioramento che va da circa mezzo punto percentuale a due punti. Ha inoltre raggiunto queste accuratezze con una convergenza più regolare e più rapida. Le misure di vulnerabilità agli attacchi di membership inference — dove un avversario cerca di determinare se i dati di una specifica persona sono stati usati per l’addestramento — sono rimaste vicine al livello del caso, indicando che i guadagni di accuratezza non sono stati ottenuti a scapito di una privacy empirica più debole.
Conclusione per l’apprendimento attento alla privacy
In termini semplici, l’articolo mostra che il deep learning privato può essere reso allo stesso tempo più sicuro e più efficace spendendo il budget di privacy solo per aggiornamenti ben scelti e adattando i livelli di rumore alla fase dell’addestramento. Con un piccolo buffer che confronta passi candidati e un programma che calma gradualmente il processo di apprendimento, DPSGD-BR trasforma la stessa garanzia formale di privacy in un progresso di apprendimento più utile. Per i praticanti, questo suggerisce una strada pratica verso modelli che rispettano i dati degli individui mantenendo al contempo competitività nell’accuratezza su compiti reali di visione e linguaggio.
Citazione: Deng, S., Zhang, K., Zhang, W. et al. Stabilizing updates in differentially private stochastic gradient descent with buffered rejection. Sci Rep 16, 13961 (2026). https://doi.org/10.1038/s41598-026-44009-2
Parole chiave: privacy differenziale, deep learning, stochastic gradient descent, addestramento che preserva la privacy, inference di membership