Clear Sky Science · he
ייצוב העדכונים ב- stochastic gradient descent פרטי אינפורמטיבי עם דחייה במאגר
למה למידה פרטית חשובה
אפליקציות מודרניות לומדות מתוך אוספים עצומים של תמונות, רשומות רפואיות והודעות אישיות. נתונים אלה מסוגלים להפוך מודלים של למידה חישובית לחכמים יותר, אך הם גם יוצרים סיכונים: המודל עלול לחשוף בטעות מידע על האנשים שלמדו ממנו. פרטיות דיפרנציאלית היא ארגז כלים מתמטי שמטרתו למנוע זאת. המאמר שמאחורי תקציר זה מציג שיטה לאימון רשתות עצביות עמוקות שמביאה ערבויות פרטיות חזקות תוך השבתה של חלק מהדיוק שאבד בדרך כלל לרעש המשמש לשמירה על פרטיות.
האתגר של אימון מרועש
כדי להגן על יחידים, אימון דיפרנציאלי פרטי מזריק רעש אקראי לכל צעד קטן שהמודל מבצע במהלך הלמידה. רעש זה מסתיר את תרומתו של כל אדם בנתונים, אך גם מקשה על הלמידה: העדכונים של המודל נעשים רעועים, ההתקדמות מאטה ולדיוק הסופי יש ירידה בהשוואה לאימון שאינו פרטי. שיטות קודמות ניסו להיות ברירות יותר, ודילגו על עדכונים שנראו לא מועילים כאשר הוערכו על אצוות אימות קטנה. עם זאת, החלטות אלה עדיין נשענו על מדידה רועשת יחידה, כך שעידכונים טובים יכלו להידחק ונבחרים רעים התקבלו בטעות, ובכך נבזבזו חלק מה"תקציב הפרטיות" המוגבל שקובע כמה גישה לנתונים מותרת.
בחירת צעדים טובה יותר עם זיכרון קטן
המחברים מציעים את DPSGD-BR, אלגוריתם שמשנה את אופן החלטת המודל אילו צעדי למידה לשמור. במקום לשפוט עדכון מועמד אחד בכל פעם, השיטה שומרת מאגר זעיר של שני מועמדים מבטיחים שעברו כבר בדיקה פרטית מהירה. היא משווה אז את הפחתות ההפסד הרועשות שלהם ומעדיפה את זה שנראה מועיל יותר, לפעמים בוחרת באקראי אם שניהם נראים שווים. השוואה דו-כיוונית זו מפחיתה חלק מהאקראיות, מה שהופך את ההחלטות לפחות רגישות למדידה הרועשת היחידה. אם המסנן נעשה נוקשה מדי והרבה מועמדים נדחים ברצף, האלגוריתם עובר אוטומטית למצב פשוט של מועמד יחיד כדי שהאימון לא יתעכב בקרבת אזורים שטוחים או קשים על משטח ההפסד.
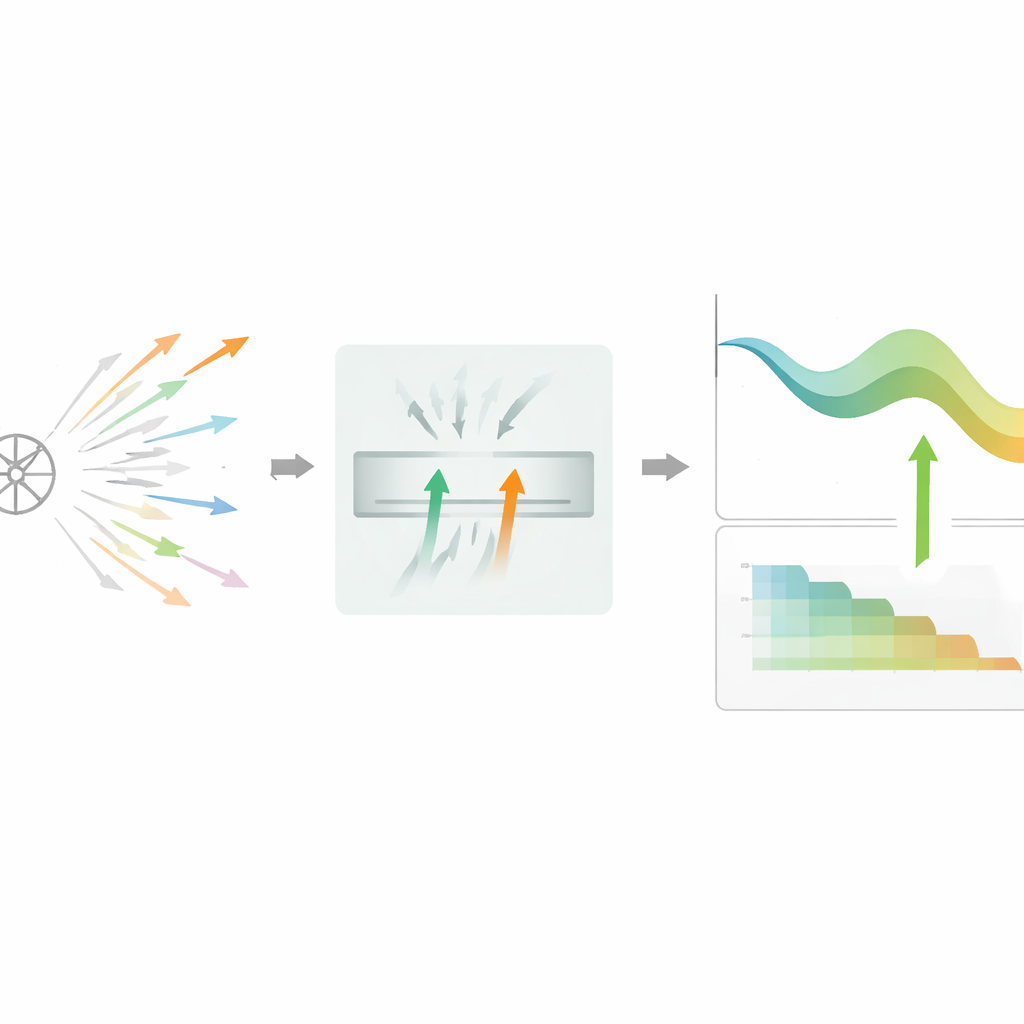
הסתגלות של רעש וגודל הצעד לאורך הזמן
מעבר לבחירה חכמה יותר, DPSGD-BR מתאים גם את המנופים המרכזיים לאורך האימון. אחרי כל עדכון שמתקבל, הוא בודק עד כמה השתפרה הדיוק על האימות. כאשר המודל לומד במהירות, השיטה מצמצמת הן את רמת הרעש והן את קצב הלמידה באופן אגרסיבי יותר, מה שעוזר לצאת משלב ראשוני רועש מאוד לתחום יציב יותר. מאוחר יותר, כאשר ההתקדמות מאיטה, היא מדללת את הכמויות הללו בעדינות רבה יותר ומרפה את כלל הדחייה, כך שיעברו יותר עדכונים והמודל יוכל לכוונן דק. כל זאת נעשה במסגרת חשבונאית מחמירה, שעוקבת כמה מתקציב הפרטיות נוצל ועוצרת כל ירידה נוספת ברמות לאחר שהתקרב למגבלה שהוגדרה מראש.
מה מראים הניסויים
החוקרים בחנו את DPSGD-BR על אמצעי מבחן ידועים: שני מאגרי תמונות של כתב-יד וביגוד (MNIST ו-Fashion-MNIST), סט תמונות טבע מורכב יותר (CIFAR-10) וניתוח סנטימנט של ביקורות סרטים (IMDb). תחת תקציבי פרטיות תואמים, שיטתם השיגה בעקביות דיוק בדיקה גבוה יותר מאימון דיפרנציאלי פרטי סטנדרטי ומשיטה מובילה של עדכונים סלקטיביים, בדרך כלל בכ-0.5 עד 2 נקודות אחוז. היא גם הגיעה לדיוק זה עם התכנסות חלקה ומהירה יותר. מדידות של פגיעות להתקפות השערת חברות—שבו תוקף מנסה לקבוע האם נתוני אדם מסוים שימשו לאימון—נשארו קרובות לרמת ניחוש אקראי, מה שמעיד שהשיפורים בדיוק לא באו על חשבון החלשה אמפירית של הפרטיות.
מסקנה ללמידה שומרת פרטיות
במלים פשוטות, המאמר מראה שניתן להפוך למידה עמוקה פרטית גם לבטוחה יותר וגם ליעילה יותר על־ידי הוצאת תקציב הפרטיות רק על עדכונים שנבחרו היטב והתאמת רמות הרעש לשלב האימון. עם מאגר זעיר שמשווה צעדים מועמדים ולוח זמנים שמרגיע בהדרגה את תהליך הלמידה, DPSGD-BR הופך את אותה הבטחה פורמלית של פרטיות להתקדמות למידתית פרקטית יותר. עבור מתרגלים, זה מציע נתיב מעשי לעבר מודלים שמכבדים את נתוני האנשים תוך שמירה על תחרותיות בדיוק במשימות ראייה ושפה בעולם האמיתי.
ציטוט: Deng, S., Zhang, K., Zhang, W. et al. Stabilizing updates in differentially private stochastic gradient descent with buffered rejection. Sci Rep 16, 13961 (2026). https://doi.org/10.1038/s41598-026-44009-2
מילות מפתח: פרטיות דיפרנציאלית, למידה עמוקה, חופן מדרון אקראי, אימון שומר פרטיות, הסקת חברות/שייכות