Clear Sky Science · en
Stabilizing updates in differentially private stochastic gradient descent with buffered rejection
Why private learning matters
Modern apps learn from huge collections of photos, medical records, and personal messages. This data can make machine learning models smarter, but it also creates risks: a model might accidentally reveal something about the people it learned from. Differential privacy is a mathematical toolkit that aims to prevent this. The paper behind this summary introduces a way to train deep neural networks that keeps strong privacy guarantees while recovering some of the accuracy usually lost to privacy-preserving noise.
The challenge of noisy training
To protect individuals, differentially private training injects random noise into each small step the model takes while learning. This noise hides the contribution of any single person in the data, but it also makes learning harder: the model’s updates become shaky, progress slows, and final accuracy drops compared with non-private training. Earlier methods tried to be more selective, skipping updates that looked unhelpful when evaluated on a small validation batch. However, those decisions still depended on a single noisy measurement, so good updates could be thrown away and bad ones accidentally accepted, wasting the limited “privacy budget” that governs how much data access is allowed.
Choosing better steps with a small memory
The authors propose DPSGD-BR, an algorithm that changes how the model decides which learning steps to keep. Instead of judging one candidate update at a time, the method keeps a tiny buffer of two promising candidates that have already passed a quick private check. It then compares their noisy loss reductions and prefers the one that seems more helpful, sometimes picking randomly if they look equally good. This two-way comparison cancels out part of the randomness, making decisions less sensitive to any single noisy reading. If the filter becomes too strict and many candidates are rejected in a row, the algorithm automatically switches to a simpler single-candidate mode so that training does not stall near flat or difficult regions of the loss surface.
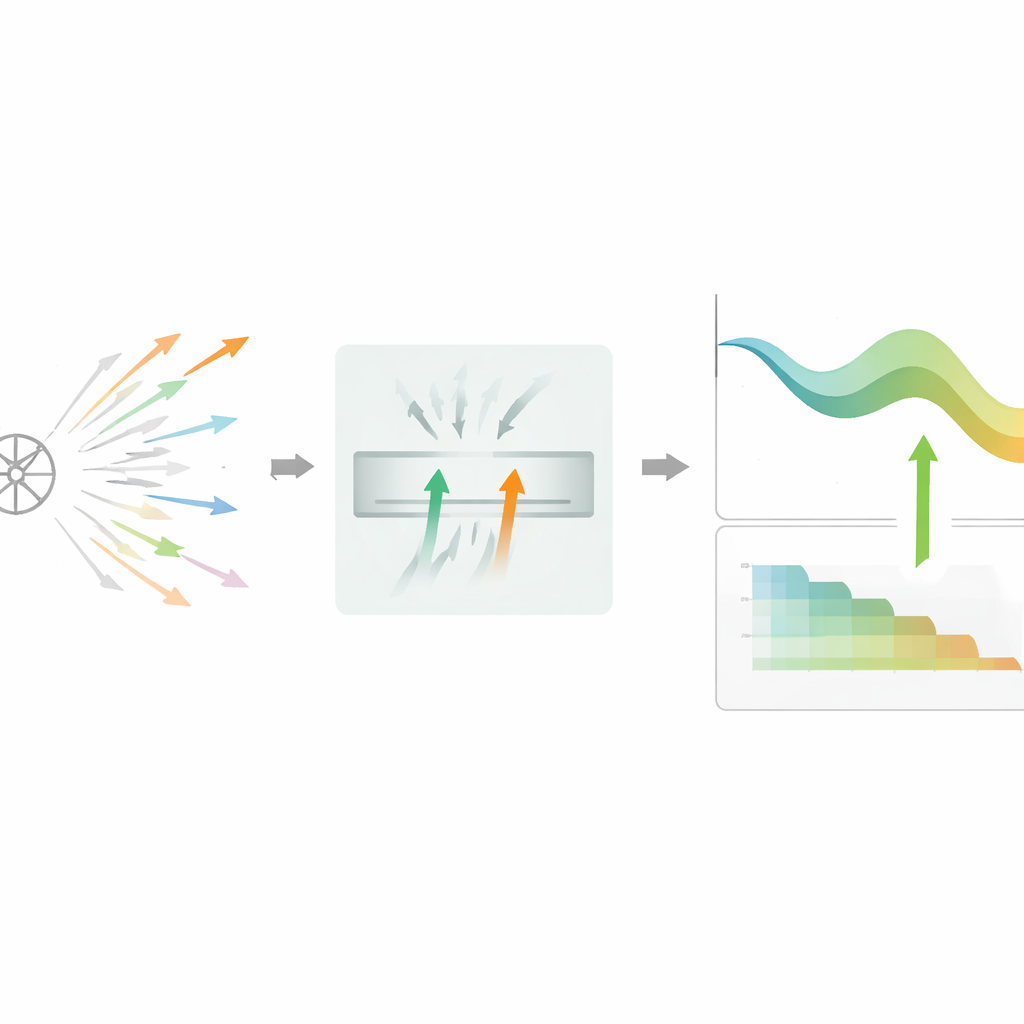
Adapting noise and step size over time
Beyond smarter selection, DPSGD-BR also adapts its key knobs throughout training. After each accepted update, it checks how much validation accuracy improved. When the model is learning quickly, the method reduces both the noise level and the learning rate more aggressively, helping it move out of a very noisy early stage into a more stable regime. Later, when progress slows, it decays these quantities more gently and relaxes the rejection rule, allowing more updates through so the model can fine-tune. All of this happens under a strict accounting framework, which tracks how much privacy budget has been spent and stops further decay once a preset limit is approached.
What the experiments show
The researchers tested DPSGD-BR on well-known benchmarks: two handwritten and clothing image datasets (MNIST and Fashion-MNIST), a more complex natural-image set (CIFAR-10), and movie-review sentiment analysis (IMDb). Under matched privacy budgets, their method consistently achieved higher test accuracy than standard differentially private training and a leading selective-update method, usually by about half a percentage point to two points. It also reached these accuracies with smoother, faster convergence. Measurements of vulnerability to membership inference attacks—where an adversary tries to tell whether a specific person’s data was used for training—stayed near the level of random guessing, indicating that the accuracy gains did not come at the expense of weaker empirical privacy.
Takeaway for privacy-conscious learning
In simple terms, the paper shows that private deep learning can be made both safer and more effective by spending privacy budget only on well-chosen updates and by matching noise levels to the stage of training. With a tiny buffer that compares candidate steps and a schedule that gradually calms the learning process, DPSGD-BR turns the same formal privacy guarantee into more useful learning progress. For practitioners, this suggests a practical path toward models that respect individuals’ data while staying competitive in accuracy on real-world vision and language tasks.
Citation: Deng, S., Zhang, K., Zhang, W. et al. Stabilizing updates in differentially private stochastic gradient descent with buffered rejection. Sci Rep 16, 13961 (2026). https://doi.org/10.1038/s41598-026-44009-2
Keywords: differential privacy, deep learning, stochastic gradient descent, privacy-preserving training, membership inference