Clear Sky Science · it
Grandi modelli linguistici contro le prestazioni degli esaminandi umani negli esami di specializzazione in anestesiologia israeliani
Perché questo è importante per medici e pazienti
Con gli strumenti di intelligenza artificiale che entrano rapidamente negli ospedali e nelle aule, una domanda centrale è come si comportino rispetto ai medici reali quando vengono testati sulle conoscenze mediche di base. Questo studio esamina come due modelli linguistici avanzati si siano confrontati con centinaia di medici in formazione in anestesiologia negli esami scritti ufficiali israeliani, offrendo un’istantanea di ciò che l’IA potrebbe essere pronta — e non pronta — a fare nella formazione medica.
Testare umani e macchine sullo stesso esame
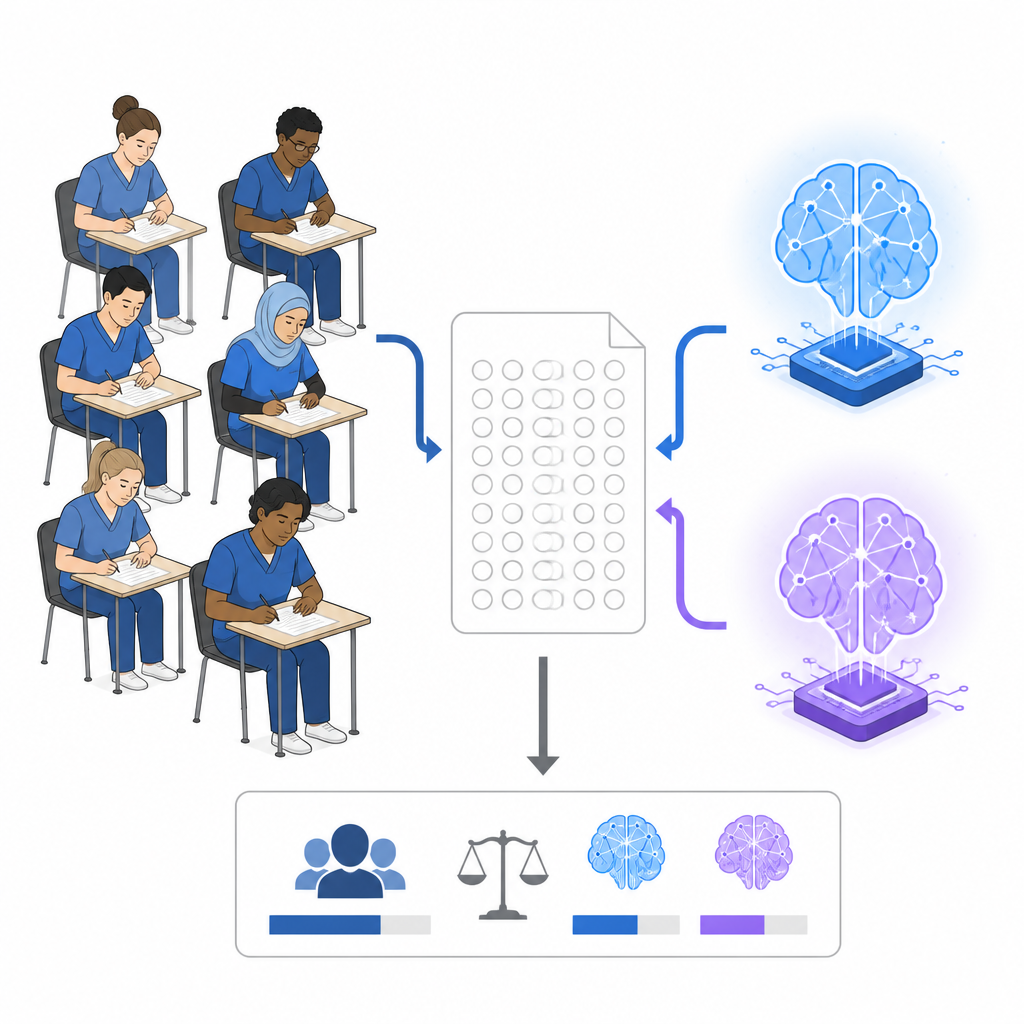
I ricercatori hanno ottenuto tre anni consecutivi degli esami Step 1 di anestesiologia israeliani, un test a scelta multipla sostenuto a metà del periodo di specializzazione. Ogni esame conteneva 150 domande in ebraico, che coprivano scienze di base, fondamenti clinici, anestesia per sottospecialità e cure d’emergenza. Oltre ai risultati di gruppo anonimizzati di 381 specializzandi, il team ha anche testato due sistemi commerciali di IA, Claude 3.7 Sonnet e ChatGPT-4, su tutte le 450 domande. I modelli hanno risposto in ebraico, hanno visto le stesse immagini e tracciati dei monitor degli specializzandi e sono stati impediti dal ricordare domande precedenti. Ogni modello ha sostenuto ogni esame due volte affinché il gruppo potesse misurarne sia l’accuratezza sia la coerenza interna.
Come hanno segnato i modelli di IA
In media su tutti gli esami, Claude 3.7 Sonnet ha risposto correttamente a circa tre domande su quattro, chiaramente sopra il punteggio complessivo degli specializzandi, poco più di tre su cinque. ChatGPT-4 ha fatto leggermente meglio rispetto ai residenti ma non con un margine ampio. Claude ha superato la soglia ufficiale di superamento in ogni tentativo, mentre ChatGPT-4 è passato solo nella metà dei casi. Tuttavia, rispetto al quarto superiore degli esaminandi umani, che mediamente ottenevano quasi quattro risposte corrette su cinque, entrambi i sistemi di IA sono rimasti indietro. In altre parole, i modelli attuali hanno superato il candidato tipico in questi test scritti ma non hanno eguagliato i migliori partecipanti umani.
Punti di forza, debolezze e prestazioni disomogenee
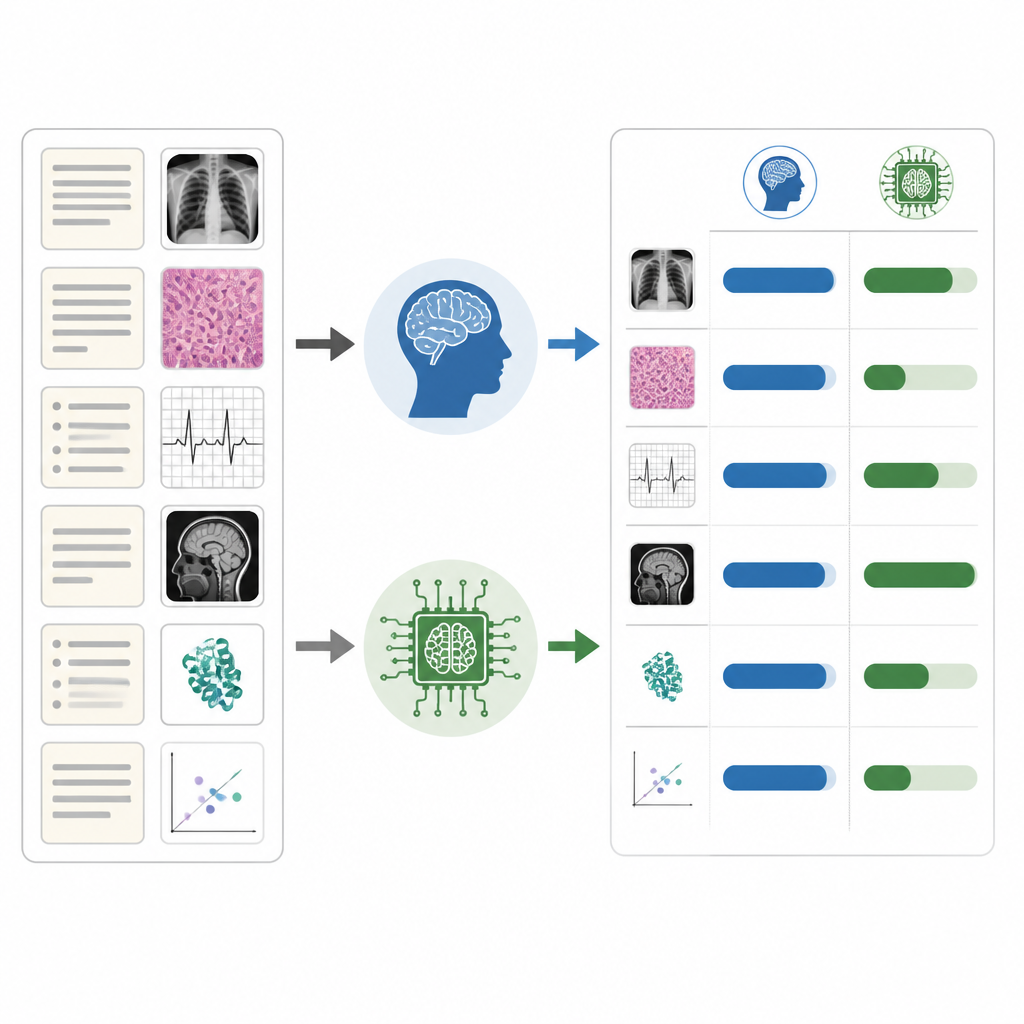
Lo studio ha rivelato che i sistemi di IA non erano ugualmente efficaci in tutti i tipi di domanda. Entrambi i modelli hanno gestito molto bene le domande più semplici e hanno reso relativamente meglio nelle aree teoriche, come la fisiologia cardiaca, dove norme e concetti sono ben consolidati. Le loro prestazioni sono calate nelle domande più difficili e nelle aree pratiche come l’anestesia ambulatoriale e l’anestesia regionale, dove il contesto, il giudizio e l’esperienza clinica sfumata contano di più. Le domande che includevano immagini, esami o tracciati di monitoraggio li hanno inoltre messo più in difficoltà rispetto agli item solo testuali, mentre i residenti umani hanno ottenuto punteggi simili in entrambi i formati. Claude e ChatGPT hanno mostrato una sostanziale coerenza interna quando hanno sostenuto lo stesso esame due volte, ma hanno concordato solo moderatamente con i pattern di risposta degli esaminandi umani.
Cosa significa per l’educazione medica
Questo quadro disomogeneo ha importanti implicazioni su come l’IA dovrebbe essere usata nella formazione dei medici. Poiché l’accuratezza dei modelli varia da quasi perfetta in alcuni argomenti a preoccupantemente bassa in altri, fare affidamento su di loro come fonte principale di studio potrebbe fuorviare gli apprendenti. Per esempio, uno specializzando potrebbe ricevere spiegazioni eccellenti sulla fisiologia cardiaca ma indicazioni scarse su certe tecniche anestesiologiche senza rendersene conto. Gli autori sostengono che questi strumenti vadano usati con cautela in ambito educativo, con stretta supervisione umana, verifica dei fatti e consapevolezza chiara dei loro punti ciechi, specialmente nelle aree che coinvolgono immagini e decisioni complesse nel mondo reale.
Conclusione sul futuro dell’IA e dell’anestesia
Lo studio conclude che i modelli linguistici avanzati oggi superano lo specializzando medio di anestesiologia in un impegnativo esame scritto nazionale, ma restano al di sotto dei migliori performer umani e mostrano grandi lacune tra gli argomenti. Superare un test a scelta multipla è solo una parte di ciò che significa essere un anestesista sicuro: servono anche abilità pratiche, gestione delle crisi e comunicazione con pazienti e team. Gli autori suggeriscono che la vera promessa dell’IA non sia nel sostituire i clinici ma nel supportarli, contribuendo a rafforzare l’apprendimento e il processo decisionale se usata in modo ponderato insieme all’esperienza umana.
Citazione: Ronen, A., Fein, S., Orbach-Zinger, S. et al. Large language models versus human examinee performance on Israeli anesthesiology board examinations. Sci Rep 16, 14978 (2026). https://doi.org/10.1038/s41598-026-45411-6
Parole chiave: formazione in anestesiologia, esami di abilitazione, grandi modelli linguistici, valutazione dell’IA medica, competenza clinica