Clear Sky Science · he
מודלים לשוניים גדולים לעומת ביצועי נבחנים אנושיים במבחני הבורד באנסטזיולוגיה בישראל
מדוע זה חשוב לרופאים ולמטופלים
כשכלי בינה מלאכותית נכנסים במהירות לבתי חולים ולכיתות לימוד, שאלה מרכזית היא כיצד הם מתמודדים מול רופאים אמיתיים במבחנים של ידע רפואי מרכזי. מחקר זה בוחן כיצד שני מודלים לשוניים מתקדמים השוו לעשרות תושבי מרפאה באנסטזיולוגיה במבחנים הכתובים הרשמיים בישראל, ומעניק הצצה למה ש-AI עשוי או לא להיות מוכן לעשות בהכשרה רפואית.
בדיקת בני אדם ומכונות על אותו מבחן
החוקרים קיבלו שלוש שנים רצופות של מבחני בורד באנסטזיולוגיה של ישראל, מבחן רב-ברירתי הננקט באמצע שנות ההתמחות. כל מבחן הכיל 150 שאלות בעברית, שתפסו מדעי היסוד, יסודות קליניים, אנסטזיה תת־תמחורית וטיפול בחירום. לצד תוצאות קבוצתיות אנונימיות של 381 מתמחים, הבחינה גם כללה בדיקות של שני מערכות AI מסחריות, Claude 3.7 Sonnet ו-ChatGPT-4, על כל 450 השאלות. המודלים ענו בעברית, ראו את אותן תמונות וגליונות ניטור כמו המתמחים, ונמנע מהם לזכור שאלות קודמות. כל מודל עבר כל מבחן פעמיים כדי שהצוות יוכל למדוד גם דיוק וגם עקביות פנימית.
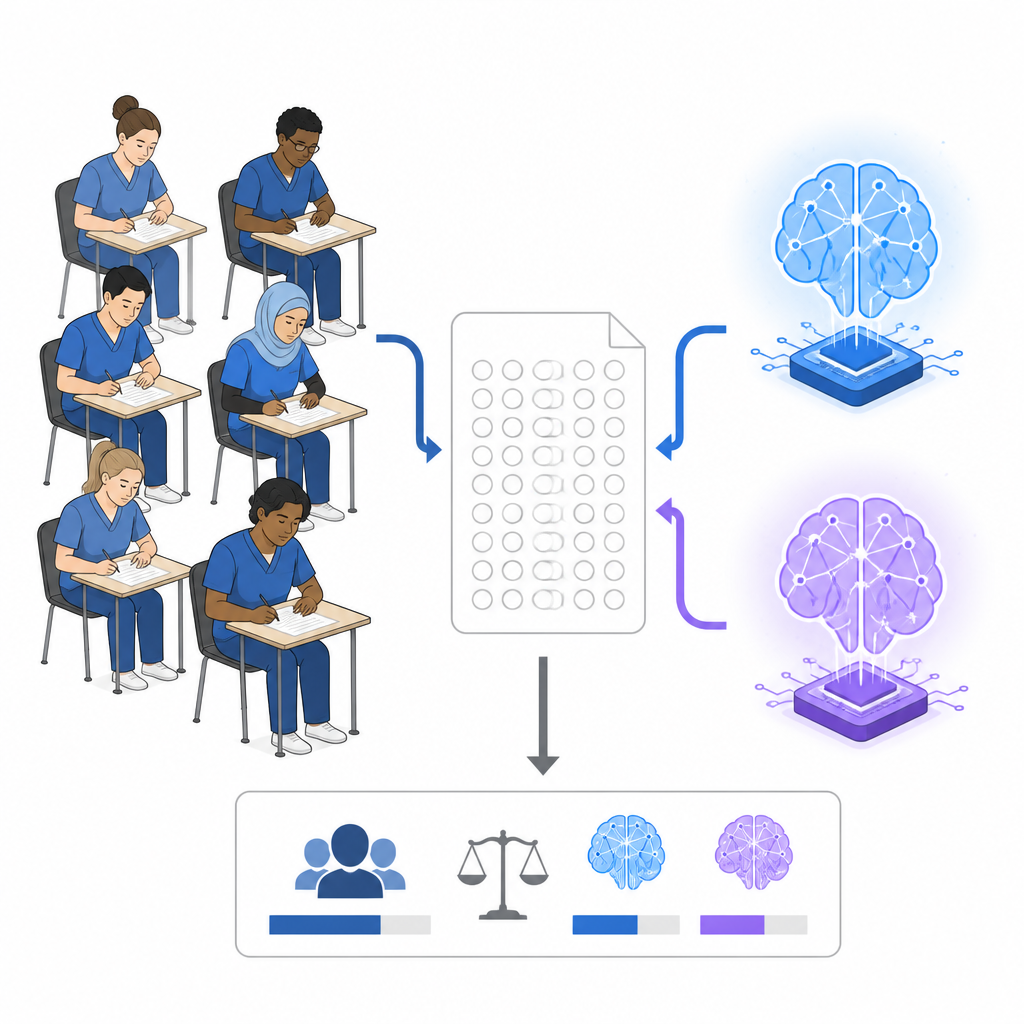
כמה טוב המודלים של ה-AI ציונו
בממוצע על פני כל המבחנים, Claude 3.7 Sonnet ענה כשלוש מתוך ארבע שאלות נכון, גבוה באופן בולט מהציון הכולל של המתמחים שעמד קצת מעל שלוש מתוך חמש. ChatGPT-4 עשה מעט יותר טוב מהמתמחים אך לא בפער גדול. Claude עבר את סף המעבר הרשמי בכל ניסיון, בעוד ש-ChatGPT-4 עבר רק במחצית מהמקרים. יחד עם זאת, כאשר משווים אליו את הרבע העליון של הנבחנים האנושיים, שצברו בממוצע קרוב לארבע תשובות נכונות מתוך חמש, שני מערכות ה-AI עדיין נותרו מאחור. במילים אחרות, המודלים הנוכחיים עלו על המתמחה הטיפוסי במבחנים הכתובים אך לא הגיעו לביצועי האנשים הטובים ביותר.
חוזקות, חולשות וביצועים לא אחידים
המחקר הראה כי מערכות ה-AI לא היו זהות בביצועיהן בכל סוגי השאלות. שני המודלים טיפלו בפריטים הקלים היטב וביצעו יחסית טוב בתחומים תיאורטיים כגון תפקוד הלב, שבהם החוקים והקונספטים ברורים ומבוססים. הביצועים שלהם ירדו בשאלות קשות יותר ובתחומים מעשיים כגון אנסטזיה אמבולטורית ואנסטזיה אזורית, שבהם ההקשר, השיקול הדעת והניסיון הקליני המעודן חשובים. שאלות שכללו תמונות, צילומים או עקבות ניטור גם הבליגו עליהם יותר מאשר פריטים בטקסט בלבד, בעוד שמתמחים אנושיים קיבלו ציונים דומים בשני הפורמטים. Claude ו-ChatGPT הפגינו עקביות פנימית ניכרת כאשר נשאלו אותו המבחן פעמיים, אך הם הסכימו במידה מתונה בלבד עם דפוסי התשובות של הנבחנים האנושיים.
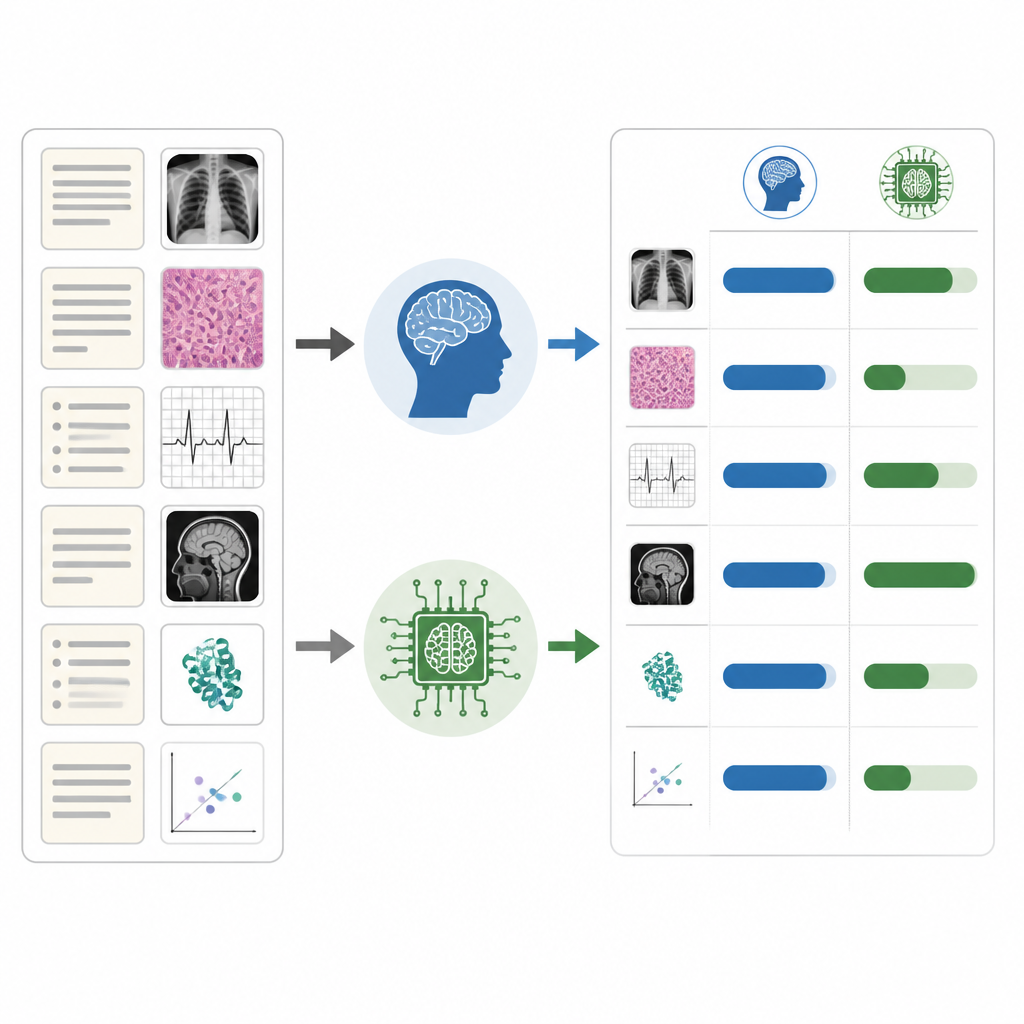
מה משמעות הדבר לחינוך רפואי
התמונה הלא אחידה הזו טומנת בחובה השלכות חשובות לגבי השימוש ב-AI בהכשרת רופאים. מאחר שדיוק המודלים נע משולי-שלמות בנושאים מסוימים לרמות מדאיגות אחרות, הסתמכות עליהם כמקור עיקרי ללמידה עשויה להטעות לומדים. לדוגמה, מתמחה עלול לקבל הסברים מצוינים בפיזיולוגיה של הלב אך הדרכה לקויה בטכניקות אנסטזיה מסוימות, מבלי להבין את ההבדל. הכותבים טוענים שיש להשתמש בכלים אלה בזהירות בהוראה, תחת פיקוח אנושי צמוד, בדיקת עובדות ומודעות ברורה לנקודות העיוורון שלהם, במיוחד בתחומים הכוללים תמונות וקבלת החלטות מורכבת בעולם האמיתי.
מסקנה לעתיד ה-AI והאנסטזיה
המחקר מסכם שמודלים לשוניים מתקדמים כיום עולים על המתמחה הממוצע באנסטזיולוגיה במבחן כתוב לאומי מאתגר, אך הם עדיין נופלים מהמבצעים האנושיים הטובים ביותר ומראים פערים גדולים בין נושאים. מעבר מבחן רב-ברירתי הוא רק מרכיב במה שמוגדר כאנסטזיולוג בטוח, הכולל גם מיומנויות מעשיות, ניהול משברים ותקשורת עם מטופלים וצוותים. הכותבים מציעים שההבטחה האמיתית של ה-AI אינה להחליף קלינאים אלא לתמוך בהם — לחזק למידה וקבלת החלטות כשהוא משולב באופן מושכל עם המומחיות האנושית.
ציטוט: Ronen, A., Fein, S., Orbach-Zinger, S. et al. Large language models versus human examinee performance on Israeli anesthesiology board examinations. Sci Rep 16, 14978 (2026). https://doi.org/10.1038/s41598-026-45411-6
מילות מפתח: הכשרה באנסטזיולוגיה, מבחני בורד, מודלים לשוניים גדולים, הערכה של AI רפואי, יכולות קליניות